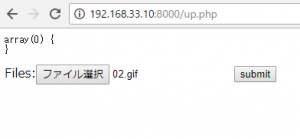
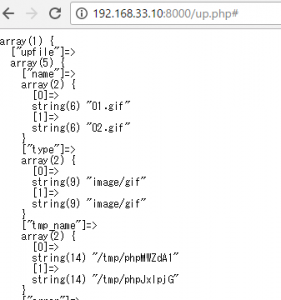
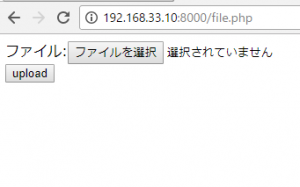
メール送信後のテーブルを作成します。file送信の機能は後から追加の予定。
create table mail.sends(
id int unsigned auto_increment primary key,
username varchar(41),
destination varchar(41),
subject varchar(255),
body varchar(255),
file1 varchar(255),
file2 varchar(255),
sendtime datetime default null
);
DBへの接続 ”to”がpostされたら、DBに入れます。
session_start();
if(isset($_POST["to"])){
$username = $_SESSION["username"];
$destination = htmlspecialchars($_POST["to"]);
$subject = htmlspecialchars($_POST["subject"]);
$body = htmlspecialchars($_POST["body"]);
$date = date("Y-m-d h:i");
$dsn = "mysql:dbname=mail;host=localhost";
$user = "hoge";
$password = "hogehoge";
try {
$dbh = new PDO($dsn, $user, $password);
} catch (PDOException $e){
print('connection failed:'.$e->getMessage());
}
$stmt = $dbh -> prepare("INSERT INTO sends (username, destination, subject, body, sendtime) VALUES(:username, :destination, :subject, :body, :sendtime)");
$stmt->bindParam(':username', $username, PDO::PARAM_STR);
$stmt->bindParam(':destination', $destination, PDO::PARAM_STR);
$stmt->bindParam(':subject', $subject, PDO::PARAM_STR);
$stmt->bindParam(':body', $body, PDO::PARAM_STR);
$stmt->bindParam(':sendtime', $date, PDO::PARAM_STR);
$stmt->execute();
}
メールを新規作成します。
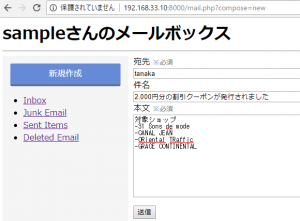
ブラウザ上の挙動
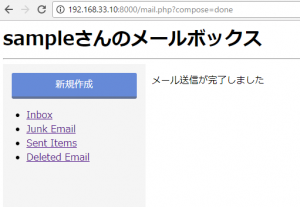
mysql側
select * from sends
mysql> select * from sends;
+----+----------+-------------+----------------------------------------------------------+--------------------------------------------------------------------------------------------+-------+-------+---------------------+
| id | username | destination | subject | body | file1 | file2 | sendtime |
+----+----------+-------------+----------------------------------------------------------+--------------------------------------------------------------------------------------------+-------+-------+---------------------+
| 1 | sample | tanaka | 2,000円分の割引クーポンが発行されました | 対象ショップ
-31 Sons de mode
-CANAL JEAN
-ORiental TRaffic
-GRACE CONTINENTAL
| NULL | NULL | 2018-03-26 10:23:00 |
+----+----------+-------------+----------------------------------------------------------+--------------------------------------------------------------------------------------------+-------+-------+---------------------+
1 row in set (0.00 sec)
入ってますね。
時間は $date = date(“Y-m-d h:i”); ではなく、$date = date(“Y-m-d H:i”); ですね。
次は、
1.添付ファイルを送りたい。
2.メールの宛先がusernamesの中になければ、宛先なしで送信エラーとしたい。
3.send itemをクリックすると、sendテーブルから送信メールを呼び出したい。
あれ、まてよ、
受け取るtestは、receiveテーブルから読み込む想定なので、receiveテーブルにもinsertしないといけない?