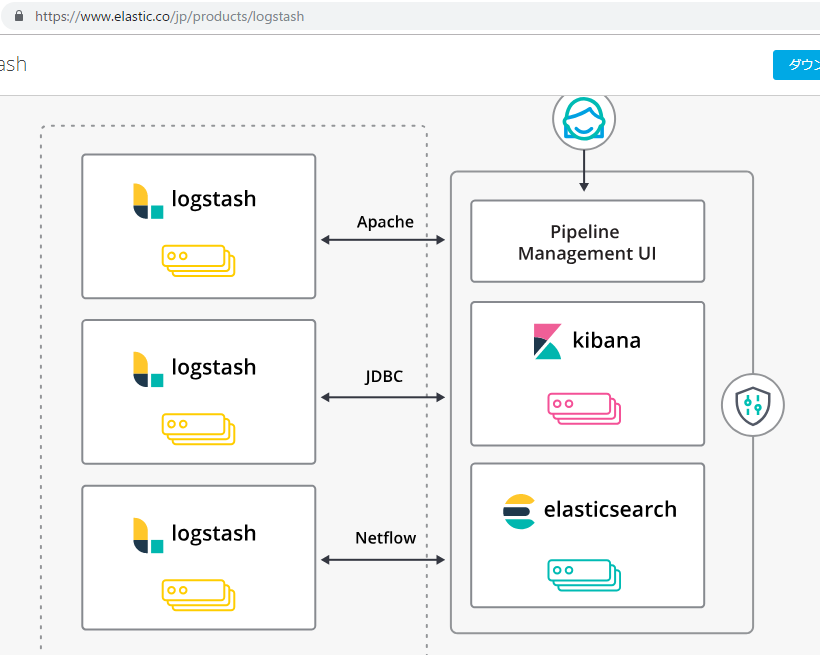
Logstash: ログの収集と記録のための機能を備えており、プラグイン形式で機能を拡張できる
Elastic Search: オープンソースで開発されている分散型データベース、 リアルタイムでのデータ分析や検索機能に優れている
Kibana: Elasticsearch内に格納されているデータを可視化できる
ELKには、Java Runtime Environment(JRE)が必要で、openjdkで提供されている。
ログ収集のパフォーマンスはLogstashよりfluentdの方が優れている?
$ cat /etc/system-release
Amazon Linux release 2 (Karoo)
$ sudo yum update -y
### Java Install
$ sudo yum search java
$ sudo yum install java-1.8.0-openjdk-devel.x86_64
$ java -version
openjdk version “1.8.0_265”
OpenJDK Runtime Environment (build 1.8.0_265-b01)
OpenJDK 64-Bit Server VM (build 25.265-b01, mixed mode)
$ javac -version
javac 1.8.0_265
## ELKインストール
ElasticSearch -> Kibana -> logstash の順にインストールしていく
### Elastic Search
こちらのサイトを参考にする
https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
$ sudo rpm –import https://artifacts.elastic.co/GPG-KEY-elasticsearch
$ cd /etc/yum.repos.d/
$ sudo touch elasticsearch.repo
$ sudo vi elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
$ sudo yum install –enablerepo=elasticsearch elasticsearch
$ sudo cat /etc/elasticsearch/jvm.options
-> Xms1g, Xmx1gを -Xms256m、-Xmx256m に変更する
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g
$ sudo service elasticsearch start
ん? failed
$ sudo systemctl status elasticsearch -l
12月 15 19:05:52 localhost systemd-entrypoint[22869]: OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000801511000, 131072, 0) failed; error=’Not enough space’ (errno=12)
何だと??
$ sudo /bin/dd if=/dev/zero of=/var/swap.1 bs=1M count=1024
$ sudo /sbin/mkswap /var/swap.1
$ sudo /sbin/swapon /var/swap.1
$ free
$ sudo service elasticsearch start
Starting elasticsearch (via systemctl): [ OK ]
きゃああああああああああああああああああああああああああああああ
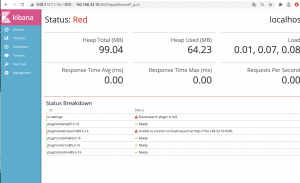
$ curl localhost:9200/
うおおおおおおおお、酒飲みてえええええええええええ