
ブラウザをエディターとして使用できるようになります。
language: ‘javascript’と書いているところで、好みの言語に変更できる。
<!Doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Monaco Editor Sample</title>
<style>
#container {
width: 800px;
height: 600px;
border: 1px solid grey;
}
</style>
</head>
<body>
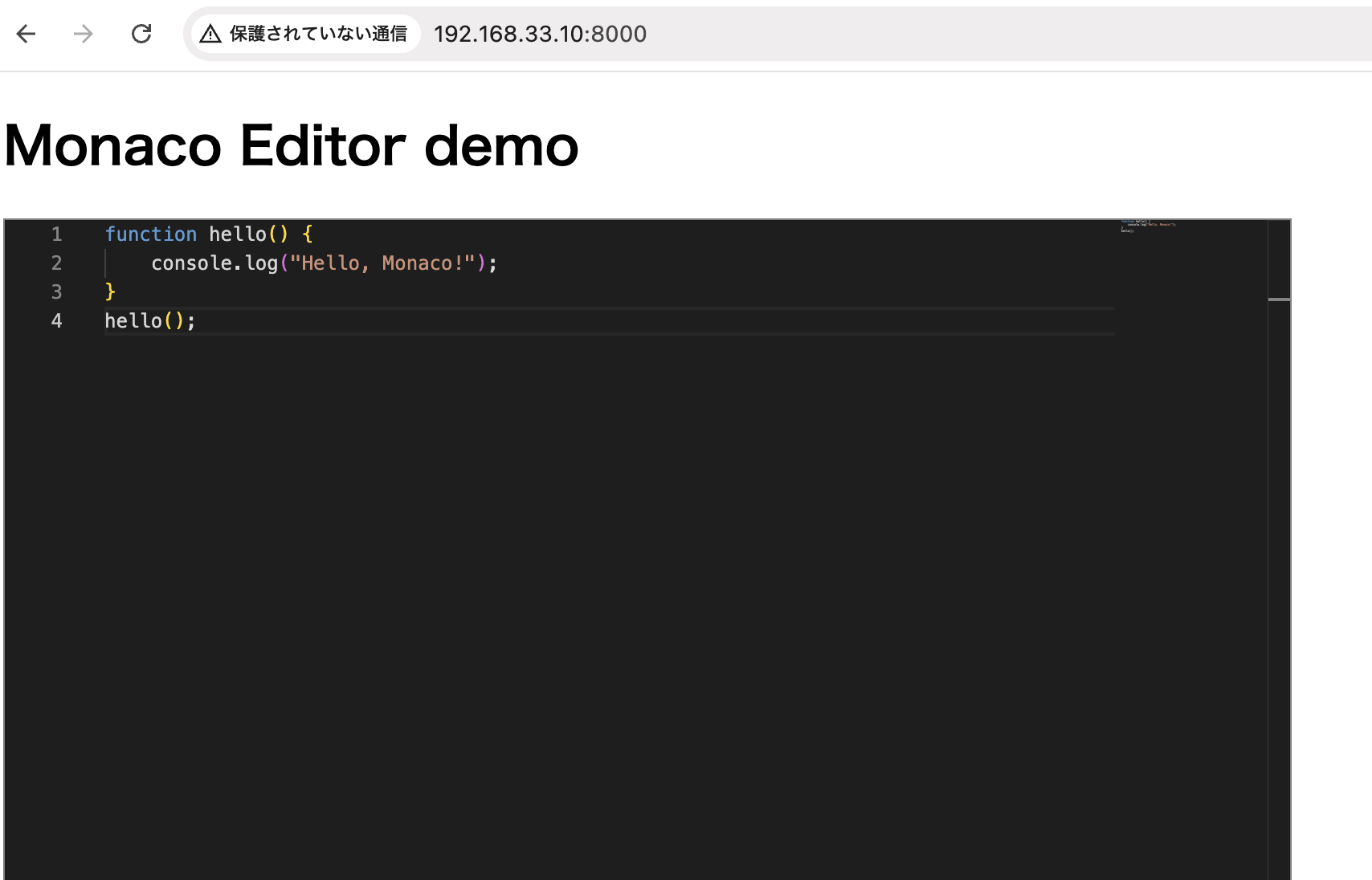
<h1>Monaco Editor demo</h1>
<div id="container"></div>
<script src="https://unpkg.com/monaco-editor@0.45.0/min/vs/loader.js"></script>
<script>
require.config({ paths: { 'vs': 'https://unpkg.com/monaco-editor@0.45.0/min/vs' }});
require(['vs/editor/editor.main'], function(){
monaco.editor.create(document.getElementById('container'), {
value: [
'function hello() {',
'\tconsole.log("Hello, Monaco!");',
'}',
'hello();'
].join('\n'),
language: 'javascript',
theme: 'vs-dark'
});
});
</script>
</body>
</html>
なるほど!
入力内容をファイルにするには
let editor;
require.config({ paths: { 'vs': 'https://unpkg.com/monaco-editor@0.45.0/min/vs' }});
require(['vs/editor/editor.main'], function(){
editor = monaco.editor.create(document.getElementById('container'), {
value: [
'fn main() {',
' println!("Hello, Rust!");',
'}'
].join('\n'),
language: 'rust',
theme: 'vs-dark'
});
});
function saveAsFile(filename, content) {
const blob = new Blob([content], { type: 'text/plain;charset=utf-8' });
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = filename;
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
}
document.getElementById('saveBtn').addEventListener('click', () => {
const code = editor.getValue();
saveAsFile("main.rs", code);
});