
What is APNs?
Apple Push Notification Service (APNs) is the core of remote notification functionality. It is a robust, secure, and very efficient service for application developers to deliver information to iOS(and indirectly watchOS), tvOS, and macOS devices.
なるほど。
Datepickerの範囲指定
まず、普通のdatepicker
<script src="http://code.jquery.com/jquery-3.2.1.min.js"></script>
<script src="https://ajax.googleapis.com/ajax/libs/jqueryui/1.12.1/jquery-ui.min.js"></script>
<link rel="stylesheet" href="https://ajax.googleapis.com/ajax/libs/jqueryui/1.12.1/themes/smoothness/jquery-ui.css">
<input type="text" name="date" value="">
<script>
$("[name=date]").datepicker({
// YYYY-MM-DD形式で入力されるように設定
dateFormat: 'yy-mm-dd'
});
</script>
特に問題ありません。
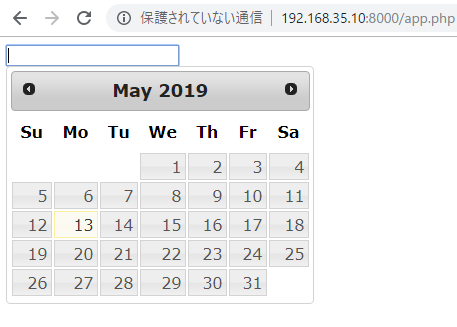
で、これを今日からにするには、minDateを0dに指定します。
<script>
$("[name=date]").datepicker({
// YYYY-MM-DD形式で入力されるように設定
dateFormat: 'yy-mm-dd',
minDate: '0d'
});
</script>
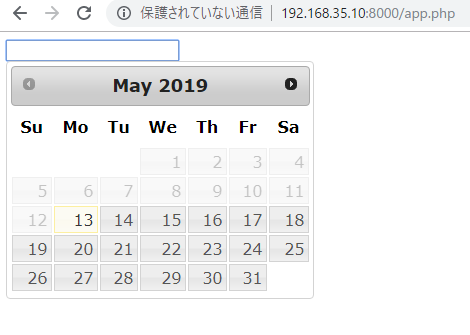
年末を指定するにはどうするかだな。
+1y -1dだと駄目みたい。
ちょっとあかんあー
倍マーチンアルゴリズムと条件分岐
例えば、持ってるポジションから逆方向に0.6%以上動いたら、倍マーチンを打つと仮定しよう。
ポジション:109.958円
現在値:109.327円
# 手持ち資金が50万円とする
$cash = 500000;
$leverage = 25;
$lot = 200000;
$long = 1;
$short = -1*0;
# ドル円価格
$dollyen = 109.958;
# 現在価格
$current = 109.327;
if(abs($current – $dollyen)/$current > 0.006){
echo “倍マーチン”;
} else {
echo “ポジション:” . $dollyen.”円
“;
echo “ロット:”. $lot. “
“;
$sum = $dollyen * $lot * $long;
$multi = $sum / $cash;
if($multi < 25){
echo "投資額:" .$sum. "円
“;
echo “
現在値:” . $current . “円
“;
$total = $current * $lot * $long;
$deposit = $cash + ($total – $sum);
echo “口座残高:” . $deposit . “円
“;
$rmargin = $total * 0.04;
echo “必要証拠金:” .$rmargin . “円
“;
$mrate = ($cash + ($total – $sum)) / $rmargin;
echo “証拠金維持率:” .$mrate * 100 . “%
“;
if ($mrate < 0.5){
echo "ロスカットが発生しました";
} else {
echo "※証拠金維持率が50%を割とロスカットとなります。ロスカットに注意してください。";
}
} else {
echo "レバレッジを25倍以下に抑えてください";
}
}
[/php]
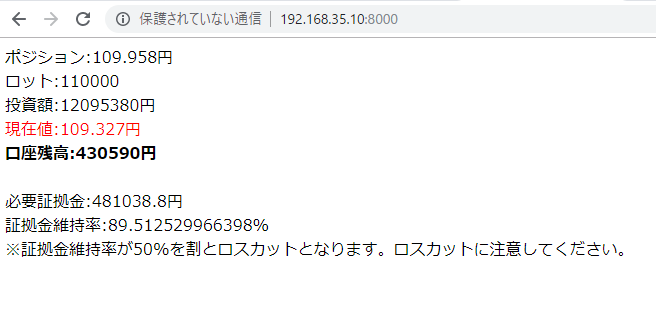
例えばこれ、連続3回までの倍マーチン自動アルゴリズムと考えると、
1 + 2 + 4 + 8 = 15 だから、
初回のエントリーは、現在資産 * 25 / 15 = 1.6
手持ちが50万だったら、1ロットってことになる。
つまり、ドル円で考えるなら、種が60万くらいないと、連続3回の倍マーチンが成立しないってことだ。
1ロットで0.6%なら6000円くらい。手持ち50万で6000円の勝ち負けなら、許容範囲というか、妥当なところだろう。
倍マーチンはとりあえず0.6%としておこう。
考えなければいけないのは、
初回のエントリーのタイミングと、利確のタイミング。
倍マーチンのラインが0.6%なら、損切の2倍ルールを応用すると、1.2%で利確、となる。しかし、0.6の1.2%だとドル円だと厳しいな。。あんまりチャリンチャリンしなさそうだ。
エントリーのタイミングは、フィボナッチ、移動平均線など議論しつくされているからな~ ただ、自動売買のエントリーとなると話がちょっと違うか。イメージとしては標準偏差を使うイメージなんだが。。
マーチンゲールのアルゴリズムを考える
マーチンゲールとは?
追加のエントリーをする際、枚数(ロット)を増やしていく手法です。 例 1枚(1ロット) ↓ ↓ 2枚(2ロット) ↓ ↓ 4枚(4ロット) ↓ ↓ 8枚(8ロット) ↓ ↓ というように、エントリーごとに枚数を「倍、倍」にしていきます。 100円で最初のポジションを持った後に下落し、 98円でポジションを持つ際に倍の2枚でエントリーします。 そうすることで、 100円 + 98円 + 98円 = 平均98.67円 というところまで、利益となるボーダーラインが下がってきます。 先ほどの「ナンピン」は99円でしたので、より早く利益確定を狙うことができます。 よって、一回ポジションを持ったら、利益になるまで諦めない手法と言えるでしょう。
つまり、(1)ポジションと逆にいった場合に、エントリーをするということだ。
よって、どれくらい逆にいった場合にエントリーするか、を設定する必要がある。
ナンピンの場合は、単純にエントリーだが、マーチンゲールの場合は、エントリーのロットが増える。よって、(2)最初のエントリーの倍のロットでエントリーする必要がある。
この(1)、(2)をコードに反映させる必要がある。
うむ。。。これ、以外と頭使うなー。
PHPでFXを考えよう
まず適当に考えます。手持ち50万として、ドル円が109.958円の時、1ロットは
# 手持ち資金が50万円とする $margin = 500000; # レバレッジ25倍とする $leverage = 25; # 1ロット1万通貨 $lot = 10000; $long = 1; $short = -1*0; # ドル円価格 $dollyen = 109.958; $total = $dollyen * $lot * $long; echo $total;
->1099580
当然、109万9580円です。ここから必要証拠金を考えます。
取引単位は1ロットからで、4万円とあります。
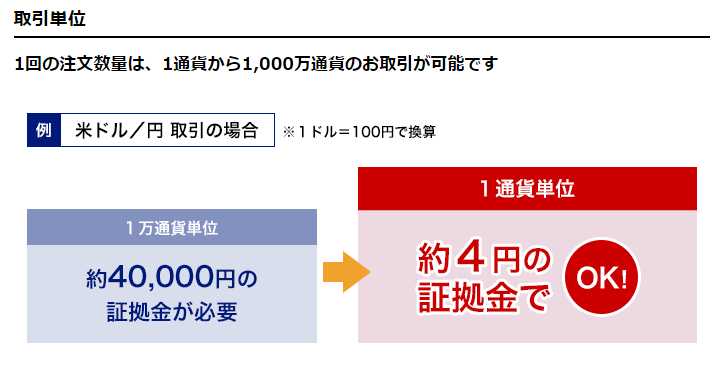
よって、requried marginを4%と置きます。
$lot = 10000; $long = 1; $short = -1*0; # ドル円価格 $dollyen = 109.958; $total = $dollyen * $lot * $long; echo $total. "<br>"; $rmargin = $total * 0.04; echo $rmargin;
-> 43983.2
必要証拠金は43,983円
証拠金維持率は、手持ちの金額から必要証拠金を割ったものだから、
$total = $dollyen * $lot * $long; echo $total. "<br>"; $rmargin = $total * 0.04; echo $rmargin . "<br>"; $mrate = $cash / $rmargin; echo $mrate * 100;
1099580
43983.2
1136.7976863893
証拠金維持率は1136.79%
つまり、50万もってて、ドル円109.958を1ロット、ロングでもったら、証拠金維持率は1136.79%になるということだ。
>金融商品取引業等に関する内閣府令の「FX証拠金規制」により、個人のお客様からの外国為替証拠金取引においては、取引金額の4%以上の証拠金をお預け入れいただくことが義務付けられております。
なるほど、この必要証拠金4%ってのは、金商法の規制ってわけね。
で、肝心のロスカットはというと、

必要証拠金が50%を下回ると、強制ロスカットというわけですね。
# 手持ち資金が50万円とする
$cash = 500000;
# レバレッジ25倍とする
$leverage = 25;
# 1ロット1万通貨
$lot = 10000;
$long = 1;
$short = -1*0;
# ドル円価格
$dollyen = 109.958;
echo “ポジション:” . $dollyen.”円
“;
$total = $dollyen * $lot * $long;
echo “投資額:” .$total. “円
“;
$rmargin = $total * 0.04;
echo “必要証拠金:” .$rmargin . “
“;
$mrate = $cash / $rmargin;
echo “証拠金維持率:” .$mrate * 100 . “%
“;
if ($mrate < 0.5){ echo "ロスカットが発生しました"; } else { echo "ロスカットに注意してください。" } [/php] こうか?? 必要証拠金は、現在の値によって変化するからちょっと違うな。
禁則文字
When it comes to the beginning or end of a line, it is a character that is inappropriate in appearance or hard to read. Typical examples include punctuation marks and parentheses. There are two types of punctuation characters: line beginning and end line punctuation characters. The former refers to characters that are inconvenient to come to the beginning of the line, and the latter refers to characters that do not allow to come to the end of line.
終わり
括弧類:」』)}】>≫]など
拗促音:ぁぃぅぇぉっゃゅょァィゥェォッャュョなど
中点や音引:・(中点/中黒)ー(音引き)―(ダーシ)-(ハイフン)など
句読点:、。,.など
その他約物:ゝ々!?:;/など
始め
括弧類:「『({【<≪[など
なるほどねー
python astモジュール
The ast module makes it easy to handle Python abstract syntax trees in Python applications. The abstract syntax itself can change with every release of Python. Using this module will help to learn the current grammer programmatically.
To create an abstract syntax tree, pass ast. PyCF_ONLY_AST as a flag for the built-in function compile() or use the helper function parse() provided by this module. The result is a tree of objects of classes that inherit from ast.AST. Abstract syntax trees can be compiled into Python code objects using the built-in function compile().
[vagrant@localhost test]$ python --version
Python 3.5.2
[vagrant@localhost test]$ cat << 'EOF' > helloworld.py
> !#/usr/bin/env python
> # -*- coding: utf-8 -*-
>
> def main():
> print('hello, world!')
>
> if __name__ == '__main__':
> main()
> EOF
[vagrant@localhost test]$ python
Python 3.5.2 (default, Jul 28 2018, 11:25:01)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-23)] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>> FILENAME = ‘helloworld.py’
>>> with open(FILENAME, ‘r’) as f:
… source = f.read()
File “
source = f.read()
^
IndentationError: expected an indented block
あれ、うまくいかんな。。
Sotaって何?
state of the artの略?
ib_logfile*
ibdata* is a shared table space (It managed all data)
ib_logfile* seems to be a log file.
Data is not updated directory to the table space, but once the update contents are written to the log file.
After that, it seems that the flow is reflected in table space.
Tablespace updates are expensive and are not reflected immediately.
By writing to the log file, the writing performance is improved.
中身を見てみましょう
cd /var/lib/mysql ls sud cat ib_logfile0
なんじゃこりゃーー
InnoDB
– Default storage engine from MySQL5.5
– General purpose storage engine with good balance of reliability and performance.
– DML operations process transactions according to the ACID model, such as commit rollback and crash recovery
– Data is aligned on disk so that queries are optimized based on primary key
– Operations that call different storage engine tables can be mixed in one query
– Foreign key constraints are also supported
– InnoDB stores in tablespaces whereas MyISAM always stores data in file
– The good thing about MyISAM is that it can be easily backed up and copied in units of tables, but innoDB is still poorly managed in this respect.
– Table spaces can be stored in files, but can also be written directly to partitions.
– There is unique buffer pool for caching data and indexes in many mamory, which helps high speed data access.
う~ん、。。。