使用条件
会員登録を行い、ETLをDLする

binaryから画像にする
import struct
from PIL import Image, ImageEnhance
import glob, os
RECORD_SIZE = 2052
outdir = "ETL7-img/"
if not os.path.exists(outdir): os.mkdir(outdir)
files = glob.glob("ETL7/*")
fc = 0
for fname in files:
fc = fc + 1
print(fname)
f = open(fname, "rb")
f.seek(0)
i = 0
while True:
i = i + 1
s = f.read(RECORD_SIZE)
if not s: break
r = struct.unpack('>H2sH6BI4H4B4x2016s4x', s)
iF = Image.frombytes('F', (64, 63), r[18], 'bit', 4)
iP = iF.convert('L')
code_jis = r[3]
dir = outdir + "/" + str(code_jis)
if not os.path.exists(dir): os.mkdir(dir)
fn = "{0:02x}-{1:02x}{2:04x}.png".format(code_jis, r[0], r[2])
fullpath = dir + "/" + fn
enhancer = ImageEnhance.Brightness(iP)
iE = enhancer.enhance(16)
iE.save(fullpath, "PNG")
print("ok")
pickleの作成
import numpy as np
import cv2
import matplotlib.pyplot as plt
import glob
import pickle
out_dir = "./ETL7-img"
im_size = 32
save_file = out_dir + "/JapaneseHiragana.pickle"
plt.figure(figsize=(9, 17))
hiraganadir = list(range(177, 223+1))
hiraganadir.append(166)
result = []
for i, code in enumerate(hiraganadir):
img_dir = out_dir + "/" + str(code)
fs = glob.glob(img_dir + "/*")
print("dir=", img_dir)
for j, f in enumerate(fs):
img = cv2.imread(f)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img_gray, (im_size, im_size))
result.append([i, img])
if j == 3:
plt.subplot(11, 5, i + 1)
plt.axis("off")
plt.title(str(i))
plt.imshow(img, cmap="gray")
pickle.dump(result, open(save_file, "wb"))
plt.show
正解率 0.973809540271759 loss 0.09567940980195999
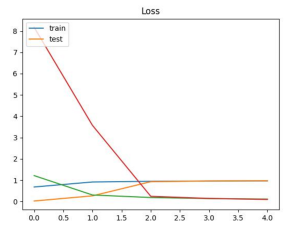
なんか出来てるっぽい