
### ラズパイのUBSマイクの設定
$ sudo vim /etc/modprobe.d/alsa-base.conf
options snd slots=snd_usb_audio,snd_bcm2835
options snd_usb_audio index=0
options snd_bcm2835 index=1
$ sudo vim ~/.profile
一番最後の行に追加
export ALSADEV=”plughw:0,0″
$ sudo apt-get install alsa-utils sox libsox-fmt-all
$ sudo sh -c “echo snd-pcm >> /etc/modules”
ラズパイ再起動
### マイクから音声認識
$ source dev/deepspeech-train-venv/bin/activate
$ cd deepspeech
$ git clone https://github.com/mozilla/DeepSpeech-examples
$ cd DeepSpeech-examples/DeepSpeech-examples
$ pip install -r requirements.txt
$ sudo apt install portaudio19-dev
$ pip3 install halo webrtcvad –upgrade
$ python3 DeepSpeech-examples/mic_vad_streaming/mic_vad_streaming.py -m deepspeech-0.7.1-models.tflite -s deepspeech-0.7.1-models.scorer
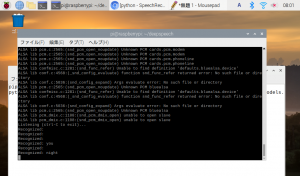
こんな感じになる
Listening (ctrl-C to exit)…
Recognized:
Recognized:
Recognized:
Recognized: you
Recognized:
Recognized: night
きたあああああああああああああああああああああ
さあ サーバーサイドやろう
とりあえず満足
https://github.com/mozilla/DeepSpeech-examples/blob/r0.9/mic_vad_streaming/mic_vad_streaming.py
line188行目でtextをrecognized:としているので、ここでテキストとして保存すれば良い
else:
if spinner: spinner.stop()
logging.debug("end utterence")
if ARGS.savewav:
vad_audio.write_wav(os.path.join(ARGS.savewav, datetime.now().strftime("savewav_%Y-%m-%d_%H-%M-%S_%f.wav")), wav_data)
wav_data = bytearray()
text = stream_context.finishStream()
print("Recognized: %s" % text)
stream_context = model.createStream()