
{
"meta": {
"code": 200
},
"data": {
"attribution": null,
"tags": [
"hammocklife"
],
"type": "image",
"location": null,
"comments": {
"count": 3
},
"filter": "Sierra",
"created_time": "1461813314",
"link": "https://www.instagram.com/p/BEun3YZCJqqgzfiJgNmTfMTlR7GwJm5bDX4qlo0/",
"likes": {
"count": 5
},
"images": {
"low_resolution": {
"url": "https://scontent.cdninstagram.com/t51.2885-15/s320x320/e35/13102358_103255900087378_1394116402_n.jpg?ig_cache_key=MTIzODEwMjI3NzE0ODQxNjY4Mg%3D%3D.2",
"width": 320,
"height": 320
},
"thumbnail": {
"url": "https://scontent.cdninstagram.com/t51.2885-15/s150x150/e35/13102358_103255900087378_1394116402_n.jpg?ig_cache_key=MTIzODEwMjI3NzE0ODQxNjY4Mg%3D%3D.2",
"width": 150,
"height": 150
},
"standard_resolution": {
"url": "https://scontent.cdninstagram.com/t51.2885-15/s640x640/sh0.08/e35/13102358_103255900087378_1394116402_n.jpg?ig_cache_key=MTIzODEwMjI3NzE0ODQxNjY4Mg%3D%3D.2",
"width": 640,
"height": 640
}
},
"users_in_photo": [],
"caption": {
"created_time": "1461813314",
"text": "A moment when time stood still.",
"from": {
"username": "udacityandroid",
"profile_picture": "https://scontent.cdninstagram.com/t51.2885-19/10358350_509158375857070_780999097_a.jpg",
"id": "55555555",
"full_name": "udacityandroid"
},
"id": "17847091000097819"
},
"user_has_liked": false,
"id": "1238102277148416682_55555555",
"user": {
"username": "udacityandroid",
"profile_picture": "https://scontent.cdninstagram.com/t51.2885-19/10358350_509158375857070_780999097_a.jpg",
"id": "55555555",
"full_name": "udacityandroid"
}
}
}
Overview of JSON
Overview of JSON
JavaScript Object Notation
{
"size": 9.5,
"wide": true,
"country-of-origin" : "usa",
"style": {
"categories": ["boot", "winklepicker"],
"color": "black"
}
}
number, boolean, string
https://api.twitter.com/1.1/favorites/list.json?count=2&screen_name=episod
https://www.instagram.com/developer/endpoints/media/#get_media
list_item.xml
<?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="wrap_content" android:gravity="center_vertical" android:orientation="horizontal" android:minHeight="?android:attr/listPreferredItemHeight" android:padding="16dp"> <ImageView android:id="@+id/list_item_icon" android:layout_width="50dp" android:layout_height="50dp" /> <LinearLayout android:layout_width="0dp" android:layout_height="wrap_content" andorid:layout_weight="1" android:orientation="vertical" android:padding="16dp"> <TextView android:id="@+id/version_name" android:layout_width="wrap_content" android:layout_height="wrap_content" /> <TextView android:id="@+id/version_name" android:layout_width="wrap_content" android:layout_height="wrap_content" /> </LinearLayout> </LinearLayout>
USGS earthquake API parameters
USGS earthquake API parameters
parameter name: description
mag: short for “magnitude”
place: where the earthquake occurred
time: when the earthquake occurred
felt: how strong this quake was felt
tsunami: was there a tsunami alert issued?
title: the title of the quake (mag + place)
coordinates: where the earthquake occured (long, lat, depth)
package com.example.android.quakereport;
import android.os.Bundle;
import android.support.v7.app.AppCompactActivity;
import android.widget.ArrayAdapter;
import android.widget.ListView;
import java.util.ArrayList;
public class EarthquakeActivity extends AppCompactActivity {
public static final String LOG_TAG = EarthquakeActivity.class.getName();
@Override
protected void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
setContentView(R.layout.earthquake_activity);
ArrayList<String> earthquakes = new ArrayList<>();
earthquakes.add("San Fransisco");
earthquakes.add("London");
earthquakes.add("Tokyo");
earthquakes.add("Mexico City");
earthquakes.add("Moscow");
earthquakes.add("Rio de Janeiro");
earthquakes.add("Paris");
ListView earthquakeListView = (ListView) findViewById(R.id.list);
ArrayAdapter<String> adapter = new ArrayAdapter<String>(
this, android.R.layout.simple_list_item_1, earthquakes);
earthquakeListView.setAdapter(adapter);
}
}
USGS spreadsheet format
https://earthquake.usgs.gov/earthquakes/feed/v1.0/csv.php
real-time data provided by USGS in spreadsheet format, most useful data in app.
date, latitude, longitude, depth, magnitude, place, type
For Developers API documentation
https://earthquake.usgs.gov/fdsnws/event/1/
Get geojson data from query and parameter
https://earthquake.usgs.gov/fdsnws/event/1/query?starttime=2017-04-29&endtime=2017-04-30&format=geojson
json pretty print
http://jsonprettyprint.com/
-time is unix timestamp
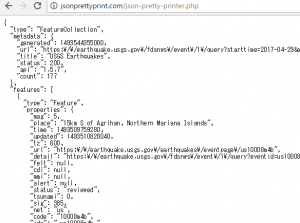
more than 4.5 magnitude
https://earthquake.usgs.gov/fdsnws/event/1/query?starttime=2017-04-29&endtime=2017-04-30&format=geojson&minmagnitude=4.5
Better Practice for User Interface
Best practices for User Interface
https://developer.android.com/training/best-ui.html
-Designing for Multiple Screens
How to build a user interface that’s flexible enough to fit perfectly on any screen and how to create different interaction patterns that are optimized for different screen sizes.
-Build a Responsible UI with ConstraintLayout
How to build a layout using ConstraintLayout and the Android Studio Layout Editor.
-Adding the App Bar
How to use the support library’s toolbar widget to implement an app bar that displays properly on a wide range of devices.
-Showing Pop-Up Message
How to use the support library’s Snackbar widget to display a brief pop-up message.
-Creating Custom Views
How to build custom UI widgets that are interactive and smooth.
-Creating Backword-Compatible UIs
How to use UI components and other APIs from the more recent versions of Android while remaining compatible with older versions of the platform.
-Implementing Accessibility
How to make your app accessible to users with vision impairment or other physical disabilities.
-Managing the System UI
How to hide and show status and navigation bars across different versions of Android, while managing the display of other screen components.
-Creating Apps with Material Design
How to implement material design on Android.
Earthquake data api
Where are some possible places to find earthquake data?
-USGA is geological survey
https://earthquake.usgs.gov/fdsnws/event/1/
http://www.seismi.org/api/
https://earthquake.usgs.gov/
https://www.programmableweb.com/category/earthquakes/api
http://www.j-shis.bosai.go.jp/api-list
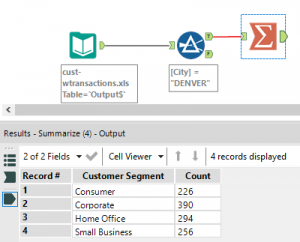
Creating data sources
customer segment -> group by
customer_ID -> count
name oreder
Descending, Ascending
data type:string, numeric, boolean
Alteryx
Alteryx: here we go
https://pages.alteryx.com/free-trial.html
sources of data
-transactional, devices, collected
categories of data
-structured, unstructured, semi-structured
structured data
-columns(fields) and rows
Scientific notation
Scientific notation
16777216
-> 16,000,000
2,000,000,000,000
-> 2trillion
6.37 x 10^-3
a x 10^exponent