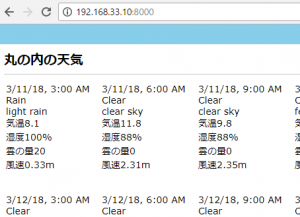
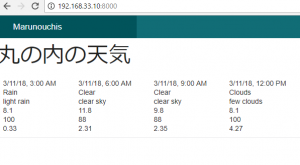
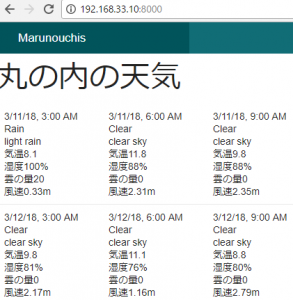
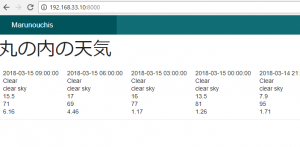
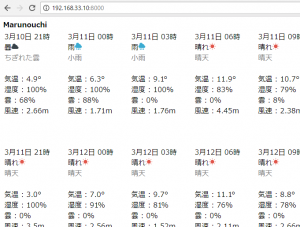
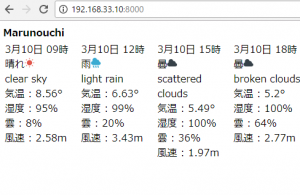
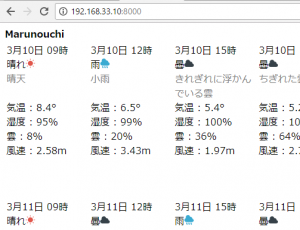
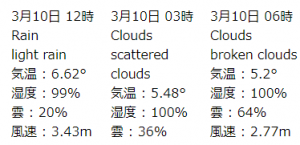
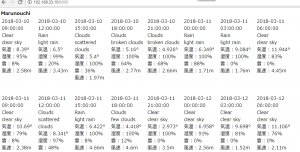
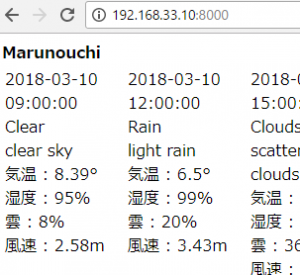
controllerで $this->viewBuilder()->layout(‘my_layout’); と指定した後に、
webrootでcssを書いていきます。
body {
margin:0;
padding:10px;
font-size: 14px;
font-family: Verdana, sans-serif;
}
.container{
maring: 0 auto;
}
h1 {
margin-top:0px;
margin-bottom: 10px;
font-size: 20px;
border-bottom: 1px solid #ccc;
padding-bottom: 5px;
}
.table1 td {
padding-bottom: 30px;
}
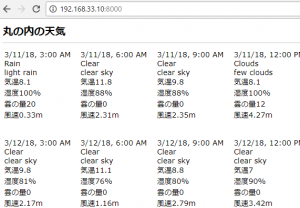
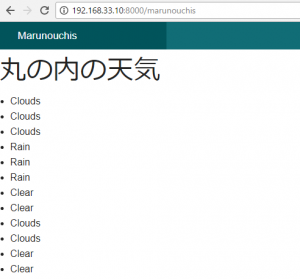
titleはindex.ctp
<?php
$this->assign('title', '丸の内の天気');
?>
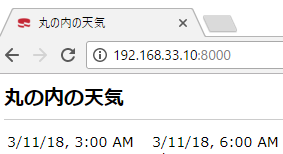
Elementをsrc/Template/Element/my_header.ctp追加します。
<header></header>
my_layout.ctpで、elementを追加します。
<body>
<?= $this->element('my_header'); ?>
<div class="container clearfix">
<?= $this->fetch('content') ?>
</div>
</body>