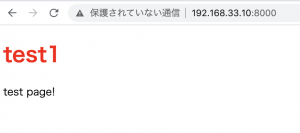
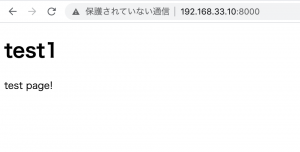
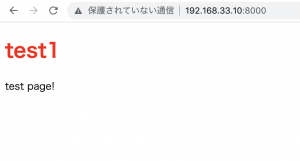
Laravel8.xをAmazon Linux 2 AMI(HVM), SSD Volume Type 64-bit(x86)で動かすことを想定して、Vagrant or EC2の開発環境構築をやっていきたい。
8系はPHP >= 7.3なので、7.4を入れるのがポイント。他は大体いつもの通りです。
EC2の場合はvagrant initは飛ばしてsshログインから始めてください。
### 1.vagrant initからsshログインまで
$ mkdir amazonlinux2
$ cd amazonlinux2
$ vagrant init gbailey/amzn2
$ vi vagrantfile
// 35行目ポートフォワーディング解除
config.vm.network "private_network", ip: "192.168.33.10"
$ vagrant up
$ vagrant ssh-config –host 192.168.33.10
$ vagrant ssh
// sshログイン後
$ cat /etc/*release
$ sudo yum update
### 2.Gitインストール(2.29.2)
$ sudo yum -y install gcc curl-devel expat-devel gettext-devel openssl-devel zlib-devel perl-ExtUtils-MakeMaker autoconf
// ダウンロード対象を確認(https://mirrors.edge.kernel.org/pub/software/scm/git/)
// 11月3日時点で最新のgit2.29.2を入れる
$ cd /usr/local/src/
$ sudo wget https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.29.2.tar.gz
$ sudo tar xzvf git-2.29.2.tar.gz
$ sudo rm -rf git-2.29.2.tar.gz
$ cd git-2.29.2
$ sudo make prefix=/usr/local all
$ sudo make prefix=/usr/local install
$ git –version
git version 2.29.2
### 3.Node.jsインストール(v11.15.0)
// 11系を入れる
$ curl –silent –location https://rpm.nodesource.com/setup_11.x | sudo bash –
$ yum install -y gcc-c++ make
$ sudo yum install -y nodejs
$ node –version
$ npm –version
### 4.Apacheインストール(Apache/2.4.46)
$ sudo yum install httpd
$ sudo systemctl start httpd
$ sudo systemctl status httpd
$ sudo systemctl enable httpd
$ sudo systemctl is-enabled httpd
$ httpd -v
### 5.PHP7.4インストール ※laravel8.xはPHP >= 7.3
$ amazon-linux-extras
$ amazon-linux-extras info php7.4
$ sudo amazon-linux-extras install php7.4
$ yum list php* | grep amzn2extra-php7.4
$ sudo yum install php-cli php-pdo php-fpm php-json php-mysqlnd php-mbstring php-xml
$ php -v
PHP 7.4.11 (cli) (built: Oct 21 2020 19:12:26) ( NTS )
おっしゃーーーーーーーーーーーー ここで一息入れてジンジャーエールを飲みます
### 6.MySQL(8.0.22)
$ sudo yum install https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
$ sudo yum install –enablerepo=mysql80-community mysql-community-server
$ sudo systemctl start mysqld
// パスワード変更
$ sudo cat /var/log/mysqld.log | grep “temporary password”
$ mysql -u root -p
mysql> ALTER USER ‘root’@’localhost’ IDENTIFIED BY ‘${temporary password}’;
mysql> SET GLOBAL validate_password.length=6;
mysql> SET GLOBAL validate_password.policy=LOW;
mysql> ALTER USER ‘root’@’localhost’ IDENTIFIED WITH mysql_native_password BY ‘${new password}’;
$ sudo systemctl enable mysqld
$ mysql -u root -p
### 7.Ansible(2.9.13)
$ sudo amazon-linux-extras install ansible2
$ ansible –version
### 8.Ruby(2.7.2)
$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv
$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
$ echo ‘export PATH=”$HOME/.rbenv/bin:$PATH”‘ >> ~/.bash_profile
$ echo ‘eval “$(rbenv init -)”‘ >> ~/.bash_profile
$ source ~/.bash_profile
// rbenvは時間がかかるので注意 痺れを切らさず待ちます
$ rbenv install 2.7.2
$ rbenv rehash
$ sudo yum install rubygems
$ gem update –system 2.7.2
### 9.AmazonLinux2 timezone変更
$ date
$ cat /etc/localtime
$ sudo vi /etc/sysconfig/clock
ZONE="Asia/Tokyo" UTC=false
$ sudo cp /etc/sysconfig/clock /etc/sysconfig/clock.org
$ strings /etc/localtime
$ date
お疲れ様でしたあああああああああああああああああああああ。githubに貼り付けときます。
今までPHP7.3で開発してたので、取り敢えず7.4が入ったあたりで満足した。
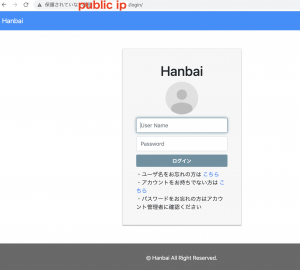
さて、いよいよcomposerでlaravel8.xをinstallしていきましょう。