import librosa
import librosa.display
import matplotlib.pyplot as plt
a, sr = librosa.load('voiceset/kirishima_b01.wav')
librosa.display.waveplot(a, sr)

print(a)
print(len(a))
print(sr)
print(a)
print(len(a))
print(sr)
print(a)
print(len(a))
print(sr)
[ 1.3803428e-06 -2.3314392e-06 7.8938438e-06 … 0.0000000e+00
0.0000000e+00 0.0000000e+00]
132300
22050 // 波形のデータが1秒間に幾つの振幅を持つか
### 高音と低音の比較
a, sr = librosa.load('sample/hi.wav')
librosa.display.waveplot(a, sr)
plt.show()
a, sr = librosa.load('sample/lo.wav')
librosa.display.waveplot(a, sr)
plt.show()
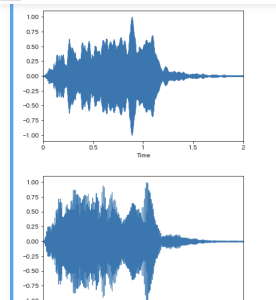
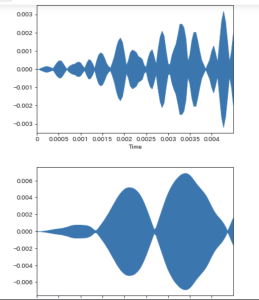
highはlowよりも細かく振動している
振動数が多いと音が高くなる傾向にある
この特性を元に、SVNに与えて話者認識を行う
import numpy as np
import librosa
import librosa.display
import os
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import svm
dir_name = 'voiceset'
for file_name in sorted(os.listdir(path=dir_name)):
print("read: {}".format(file_name))
a, sr = librosa.load(os.path.join(dir_name, file_name))
print(a.shape)
librosa.display.waveplot(a, sr)
plt.show()
同じ人の音声でも全く異なる波形になる
speakers = {'kirishima': 0, 'suzutsuki': 1, 'belevskaya': 2}
def get_data(dir_name):
data_X = []
data_y = []
for file_name in sorted(os.listdir(path=dir_name)):
print("read: {}".format(file_name))
a, sr = librosa.load(os.path.join(dir_name, file_name))
print(a.shape)
speaker = file_name[0:file_name.index('_')]
data_X.append(a)
data_y.append((speakers[speaker], file_name))
return (np.array(data_X), np.array(data_y))
data_X, data_y = get_data("voiceset")
SVMに学習させるには、要素数を同じ数に揃えなければならない
speakers = {'kirishima': 0, 'suzutsuki': 1, 'belevskaya': 2}
def get_feat(file_name):
a, sr = librosa.load(file_name)
return a[0:5000]
def get_data(dir_name):
data_X = []
data_y = []
for file_name in sorted(os.listdir(path=dir_name)):
print("read: {}".format(file_name))
speaker = file_name[0:file_name.index('_')]
data_X.append(get_feat(os.path.join(dir_name, file_name)))
data_y.append((speakers[speaker], file_name))
return (np.array(data_X), np.array(data_y))
data_X, data_y = get_data("voiceset")
print("====data_X====")
print(data_X.shape)
print(data_X)
print("====data_y====")
print(data_y.shape)
print(data_y)
教師データとテストデータに分割する
train_X, test_X, train_y, test_y = train_test_split(data_X, data_y, random_state=11813)
print("{}->{}, {}".format(len(data_X), len(train_X),len(test_X)))
cvmで学習
clf = svm.SVC(gamma=0.0001, C=1)
clf.fit(train_X, train_y.T[0])
SVC(C=1, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=’ovr’, degree=3, gamma=0.0001, kernel=’rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
テストデータの分類
clf.predict(np.array([test_X[0]]))
ok_count = 0
for X, y in zip(test_X, test_y):
actual = clf.predict(np.array([X]))[0]
expected = y[0]
file_name = y[1]
ok_count += 1 if actual == expected else 0
result = 'o' if actual == expected else 'x'
print("{} file: {}, actual:{}, expected: {}".format(result, file_name, actual, expected))
print("{}/{}".format(ok_count, len(test_X)))
x file: suzutsuki_b06.wav, actual:2, expected: 1
x file: kirishima_04_su.wav, actual:2, expected: 0
x file: kirishima_c01.wav, actual:2, expected: 0
o file: belevskaya_b04.wav, actual:2, expected: 2
o file: belevskaya_b14.wav, actual:2, expected: 2
x file: kirishima_b04.wav, actual:2, expected: 0
x file: suzutsuki_b08.wav, actual:2, expected: 1
o file: belevskaya_b07.wav, actual:2, expected: 2
x file: suzutsuki_b03.wav, actual:2, expected: 1
o file: belevskaya_b10.wav, actual:2, expected: 2
x file: kirishima_b01.wav, actual:2, expected: 0
o file: belevskaya_07_su.wav, actual:2, expected: 2
5/12
予測の精度を上げる必要がある