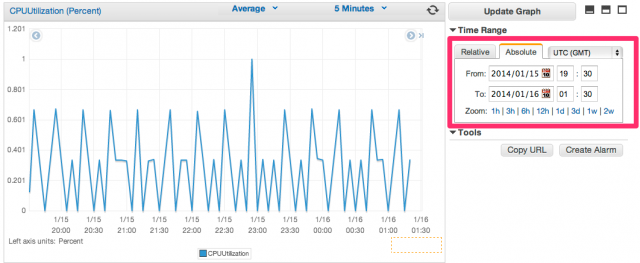
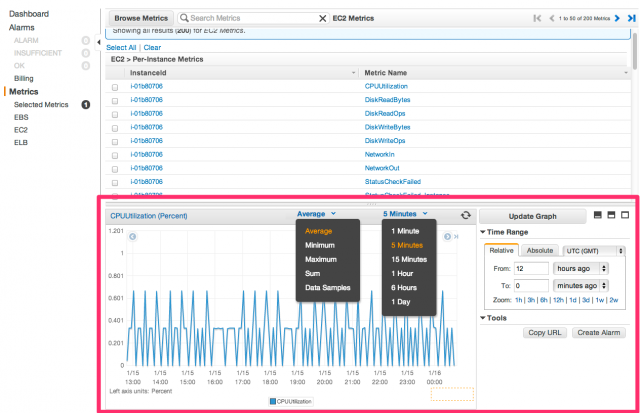
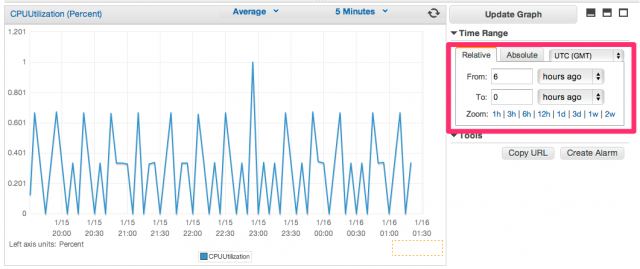
EC2インスタンスをCloudWatchでモニタリングし、基になるハードウェア障害またはAWSによる復旧を必要とする問題でインスタンスが正常に機能しなくなった事象を検知すると、CloudWatchが自動的にインスタンスを復旧する
cloudwatch-autorecovery.yml
AWSTemplateFormatVersion: "2010-09-09"
Description:
Auto Recovery for EC2
# ------------------------------------------------------------#
# Input Parameters
# ------------------------------------------------------------#
Parameters:
EC2Instance:
Type: AWS::EC2::Instance::Id
Resources:
# ------------------------------------------------------------#
# AutoRecoveryAlarm
# ------------------------------------------------------------#
AutoRecoveryAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: !Sub "${EC2Instance}-autorecovery"
Namespace: AWS/EC2
MetricName: StatusCheckFailed_System
Statistic: Minimum
Period: 60
EvaluationPeriods: 10
ComparisonOperator: GreaterThanThreshold
Threshold: 0
AlarmActions:
- !Sub "arn:aws:automate:${AWS::Region}:ec2:recover"
Dimensions:
- Name: InstanceId
Value: !Ref EC2Instance
なるほど、これはいけるね