KVSのHLSStreamingSessionURLを取得してvideojsでストリーミング表示する
credentials.js
const AWS_ACCESS_KEY_ID = '';
const AWS_SECRET_ACCESS_KEY = '';
const AWS_REGION = 'ap-northeast-1';
const AWS_STREAM_NAME = 'MyKinesisVideoStream';
html
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link href="https://vjs.zencdn.net/7.15.4/video-js.css" rel="stylesheet" />
<script src="https://sdk.amazonaws.com/js/aws-sdk-2.642.0.min.js"></script>
<script src="credentials.js"></script>
</head>
<body>
<video id="videojs" class="player video-js vjs-default-skin" data-setup='{"fluid":true}' controls autoplay muted></video>
<script src="https://vjs.zencdn.net/7.15.4/video.min.js"></script>
<script>
window.addEventListener("unhandledrejection", function(event){
console.warn("WARNING: Unhandled promise rejection." + event.reason);
location.reload()
});
window.onerror = (message, file, lineNo, colNo, error) => {
console.error('window.onerror', message, file, lineNo, colNo, error);
location.reload()
}
async function getURL(){
const accessKeyId = AWS_ACCESS_KEY_ID;
const secretAccessKey = AWS_SECRET_ACCESS_KEY;
const region = AWS_REGION;
const streamName = AWS_STREAM_NAME;
const options = {
accessKeyId: accessKeyId,
secretAccessKey: secretAccessKey,
region: region,
}
const kinesisVideoClient = new AWS.KinesisVideo(options);
const kinesisVideoArchivedMediaClient = new AWS.KinesisVideoArchivedMedia(options);
const e = await kinesisVideoClient.getDataEndpoint({
APIName: 'GET_HLS_STREAMING_SESSION_URL',
StreamName: streamName
}).promise();
kinesisVideoArchivedMediaClient.endpoint = new AWS.Endpoint(e.DataEndpoint);
const d = await kinesisVideoArchivedMediaClient.getHLSStreamingSessionURL({
DisplayFragmentTimestamp: 'ALWAYS',
StreamName: streamName
}).promise();
return d.HLSStreamingSessionURL;
}
document.addEventListener('DOMContentLoaded', async() => {
const url = await getURL();
const player = videojs('videojs');
player.src({
src: url,
type: 'application/x-mpegURL'
});
player.on('error', function(){
console.log(player.error());
location.reload();
});
setInterval(() => {
const t = player.currentTime();
console.log("current Time is "+ t +" seconds");
}, 5000)
});
</script>
</body>
</html>
### mac
kvsのsdkをdownloadした状態とする
https://github.com/awslabs/amazon-kinesis-video-streams-producer-sdk-cpp.git
macのカメラからKVSに映像を送る
$ gst-launch-1.0 avfvideosrc device-index=0 ! videoconvert ! video/x-raw,format=I420,width=1280,height=720 ! vtenc_h264_hw allow-frame-reordering=FALSE realtime=TRUE max-keyframe-interval=45 bitrate=512 ! h264parse ! video/x-h264,stream-format=avc,alignment=au,profile=baseline ! kvssink stream-name=MyKinesisVideoStream storage-size=512 access-key=”${access-key}” secret-key=”${secret-key}” aws-region=”ap-northeast-1″
$ php -S 192.168.34.10:8000
http://192.168.34.10:8000/
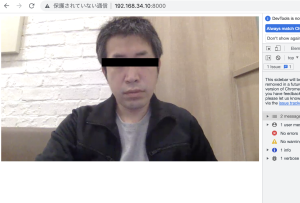
ちょっと待ってくれ
なんか凄い事やってる様な気がする…🥺