まず.wavファイルの音源を用意します。
「お疲れ様でした」という女性の声が入っています。
これをJuliusで音声認識します。
日本語のモデルはDictation-kitを使います。
https://github.com/julius-speech/dictation-kit
-> Githubのdictation-kitはトータルサイズが2Gで重いのでwgetでダウンロードしてunzipする方を使いたいと思います。
※dictation-kitをgit cloneする時
git-lfsを使うよう指示されます。
$ sudo yum install git-lfs
$ git lfs clone https://github.com/julius-speech/dictation-kit.git
no space left on device
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 520K 2.0G 1% /run
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 25G 25G 0 100% /
tmpfs 395M 0 395M 0% /run/user/1000
vagrant 234G 186G 49G 80% /vagrant
tmpfs 395M 0 395M 0% /run/user/0
これだと、直ぐにリソースが一杯になってしまい、使い切っていたのでframework系のファイル群を削除します😅
$ wget https://osdn.net/dl/julius/dictation-kit-4.5.zip
$ unzip ./dictation-kit-4.5.zip
$ cd dictation-kit-4.5
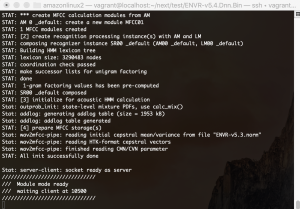
### 日本語のGMM-HMMモデルでJuliusを起動
am-dnn.jconf
L inputがmicになっているので、fileに変更します。
-input file
$ ../julius/julius/julius -C main.jconf -C am-gmm.jconf -nostrip -input rawfile
enter filename->test.wav
——
### read waveform input
enter filename->test2.wav
Stat: adin_file: input speechfile: test2.wav
STAT: 53499 samples (3.34 sec.)
STAT: ### speech analysis (waveform -> MFCC)
### Recognition: 1st pass (LR beam)
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………..pass1_best: 別れ た 真似 し た 。
pass1_best_wordseq: 別れ+動詞 た+助動詞 真似+名詞 し+動詞 た+助動詞
pass1_best_phonemeseq: silB | w a k a r e | t a | m a n e | sh i | t a | silE
pass1_best_score: -7376.977051
### Recognition: 2nd pass (RL heuristic best-first)
STAT: 00 _default: 7136 generated, 1958 pushed, 182 nodes popped in 332
sentence1: 伴天連 様 でし た 。
wseq1: 伴天連+名詞 様+接尾辞 でし+助動詞 た+助動詞
phseq1: silB | b a t e r e N | s a m a | d e sh i | t a | silE
cmscore1: 0.477 0.083 0.314 0.446 0.411 1.000
score1: -7376.384766
——
おいおいオイ、「別れ た 真似 し た 。」になってるやんか。
いい加減にしろや✊ どうなってんねんコレ。
まあ、日本語モデルはdeepspeechとかには無いからjuliusでアプリ作るけどさ。