
元の波形を周波数ごとに分ける -> 周波数ごとに集計したもの:パワースペクトル
時間を考慮せず、周波数に対応する数値として捉える
import numpy as np
import librosa
import librosa.display
import os
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import svm
from scipy import fftpack
# 音声データを読み込む
speakers = {'kirishima' : 0, 'suzutsuki' : 1, 'belevskaya' : 2}
# 特徴量を返す
def get_feat(file_name):
a, sr = librosa.load(file_name)
fft_wave = fftpack.rfft(a, n=sr)
fft_freq = fftpack.rfftfreq(n=sr, d=1/sr)
y = librosa.amplitude_to_db(fft_wave, ref=np.max)
plt.plot(fft_freq, y)
plt.show()
return y
# 特徴量と分類のラベル済みのラベルの組を返す
def get_data(dir_name):
data_X = []
data_y = []
for file_name in sorted(os.listdir(path=dir_name)):
print("read: {}".format(file_name))
speaker = file_name[0:file_name.index('_')]
data_X.append(get_feat(os.path.join(dir_name, file_name)))
data_y.append((speakers[speaker], file_name))
return (np.array(data_X), np.array(data_y))
get_feat('sample/hi.wav')
get_feat('sample/lo.wav')
横軸が周波数
hi
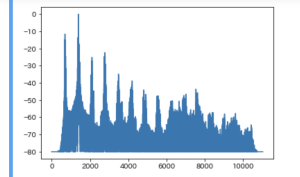
low
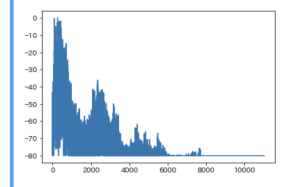
# 教師データとテストデータに分ける
train_X, test_X, train_y, test_y = train_test_split(data_X, data_y, random_state=813)
print("{} -> {}, {}".format(len(data_X), len(train_X), len(test_X)))
clf = svm.SVC(gamma=0.0000001, C=10)
clf.fit(train_X, train_y.T[0])
ok_count = 0
for X, y in zip(test_X, test_y):
actual = clf.predict(np.array([X]))[0]
expected = y[0]
file_name = y[1]
ok_count += 1 if actual == expected else 0
result = 'o' if actual == expected else 'x'
print("{} file: {}, actual: {}, expected: {}".format(result, file_name, actual, expected))
print("{}/{}".format(ok_count, len(test_X)))
o file: belevskaya_b11.wav, actual: 2, expected: 2
o file: kirishima_c01.wav, actual: 0, expected: 0
x file: kirishima_c09.wav, actual: 2, expected: 0
x file: kirishima_04_su.wav, actual: 2, expected: 0
o file: belevskaya_b14.wav, actual: 2, expected: 2
o file: kirishima_b07.wav, actual: 0, expected: 0
x file: suzutsuki_b06.wav, actual: 2, expected: 1
x file: kirishima_c02.wav, actual: 2, expected: 0
o file: kirishima_b03.wav, actual: 0, expected: 0
o file: suzutsuki_b08.wav, actual: 1, expected: 1
o file: suzutsuki_b02.wav, actual: 1, expected: 1
o file: kirishima_b05.wav, actual: 0, expected: 0
8/12
精度が上がっている