
tesseractを使います。
### install
$ sudo yum-config-manager –add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_8/
$ sudo rpm –import https://build.opensuse.org/projects/home:Alexander_Pozdnyakov/public_key
$ sudo yum update
$ sudo yum install tesseract
$ sudo yum install tesseract-langpack-jpn
### バージョン確認
$ tesseract -v
tesseract 4.1.1-rc2-20-g01fb
leptonica-1.78.0
libgif 5.1.4 : libjpeg 6b (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 1.0.0
Found AVX2
Found AVX
Found SSE
$ cd /usr/share/tesseract/4/tessdata/
$ sudo wget https://github.com/tesseract-ocr/tessdata/raw/master/eng.traineddata
$ sudo wget https://github.com/tesseract-ocr/tessdata/raw/master/jpn.traineddata
### テスト
– eng version
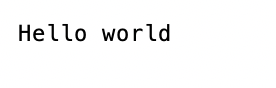
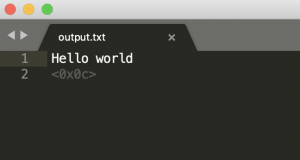
$ tesseract a.png output
– jpn version

$ tesseract test_jp.png output -l jpn
#### pyocr
tesseractをpythonで使えるようにする
$ sudo pip3 install pyocr
app.py
from PIL import Image
import sys
import pyocr
tools = pyocr.get_available_tools()
langs = tools[0].get_available_languages()
img = Image.open('test.png')
txt = tools[0].image_to_string(
img,
lang=langs[0],
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print(txt)
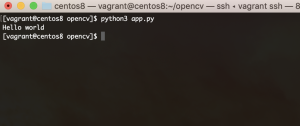
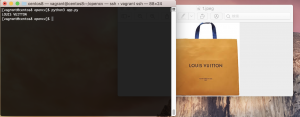
vuitton画像にしてみる。
$ python3 app.py
LOUIS VUITTON
さて、そろそろラズパイやるか。