
scrapyとはweb scraping用のフレームワーク
$ pip3 install scrapy
$ scrapy version
Scrapy 2.5.1
$ scrapy startproject test1
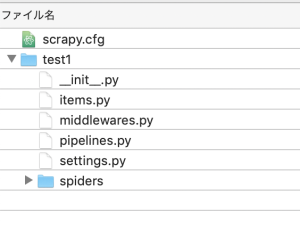
$ cd test1
$ scrapy genspider test2 https://paypaymall.yahoo.co.jp/store/*/item/y-hp600-3/
Created spider ‘test2’ using template ‘basic’ in module:
test1.spiders.test2
test1/items.py
import scrapy
class Test1Item(scrapy.Item):
title = scrapy.Field()
test1/spiders/test2.py
import scrapy
from test1.items import Test1Item
class Test2Spider(scrapy.Spider):
name = 'test2'
allowed_domains = ['paypaymall.yahoo.co.jp/store/*/item/y-hp600-3/']
start_urls = ['https://paypaymall.yahoo.co.jp/store/*/item/y-hp600-3//']
def parse(self, response):
return Test1Item(
title = response.css('title').extract_first(),
)
$ scrapy crawl test2
BS4で良いじゃんと思ってしまうが、どうなんだろうか。