
lavelImageをやり直します
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "data/vision.json"
import io
import cv2
import matplotlib.pyplot as plt
import matplotlib
from google.cloud import vision
import xml.etree.ElementTree as ET
img = cv2.imread("img/license.jpeg")
client = vision.ImageAnnotatorClient()
with io.open("img/license.jpeg", 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.document_text_detection(image=image)
text_infos = []
document = response.full_text_annotation
for page in document.pages:
for block in page.blocks:
for paragraph in block.paragraphs:
for word in paragraph.words:
for symbol in word.symbols:
bounding_box = symbol.bounding_box
xmin = bounding_box.vertices[0].x
ymin = bounding_box.vertices[0].y
xmax = bounding_box.vertices[2].x
ymax = bounding_box.vertices[2].y
xcenter = (xmin+xmax)/2
ycenter = (ymin+ymax)/2
text = symbol.text
text_infos.append([text, xcenter, ycenter])
tree = ET.parse("data/license.xml")
root = tree.getroot()
result_dict = {}
for obj in root.findall("./object"):
name = obj.find('name').text
xmin = obj.find('bndbox').find('xmin').text
ymin = obj.find('bndbox').find('ymin').text
xmax = obj.find('bndbox').find('xmax').text
ymax = obj.find('bndbox').find('ymax').text
xmin, ymin, xmax, ymax = int(xmin), int(ymin), int(xmax), int(ymax)
texts = ''
for text_info in text_infos:
text = text_info[0]
xcenter = text_info[1]
ycenter = text_info[2]
if xmin <= xcenter <= xmax and ymin <= ycenter <= ymax:
texts += text
result_dict[name] = texts
for k, v in result_dict.items():
print('{} : {}'.format(k, v))
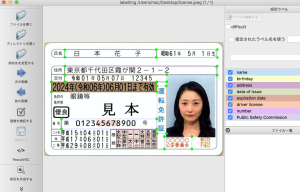
$ python3 app.py
name : 日本花子
birthday : 昭和61年5月1日生)
address : 東京都千代田区霞加喂2-1-2
data of issue : 令和01年05月07日12345
expiration date : 12024年(今和06年)06月01日未有动
driver license : 運転免許証
number : 第012345678900号
Public Safety Commission : 00000公安委員会
Finally
やっと来たね
というか、サイズが一定なら免許証以外でもOCRできるね