Amazon Route 53
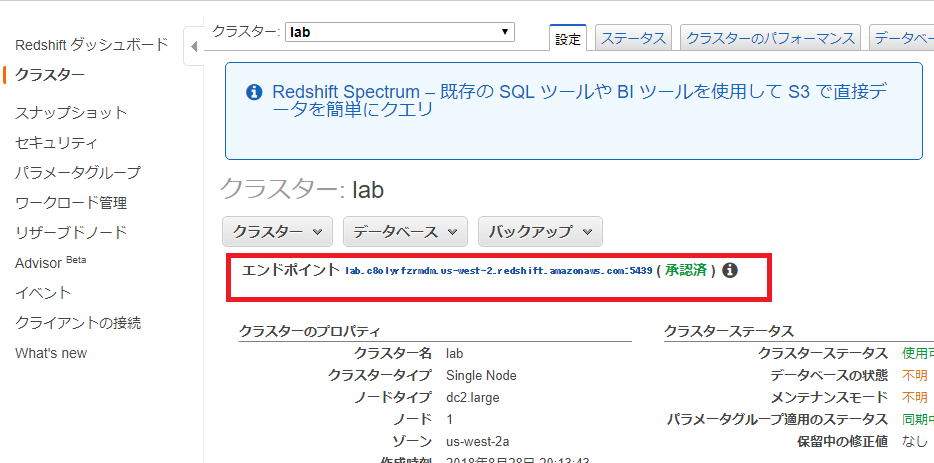
Amazon Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service. It is designed to give developers and businesses an extremely reliable and cost effective way to route end users to Internet applications by translating names like www.example.com into the numeric IP addresses like 192.0.2.1 that computers use to connect to each other, often using a process called recursion.
CNAME Record
A Canonical Name record (CNAME) is a type of resource record in the Domain Name System (DNS) used to specify that a domain name is an alias for another domain, the “canonical” domain. All information, including subdomains, IP addresses, etc. are defined by the canonical domain.
Canonical Domain
Canonical Domain is another name for the CNAME DNS record type. The CNAME record is used to create an alias for the canonical domain.
Alias Record
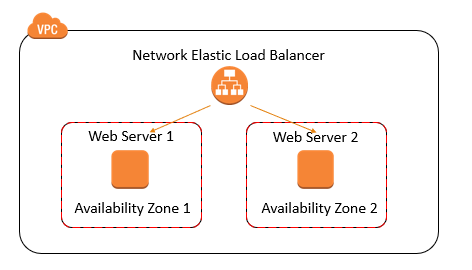
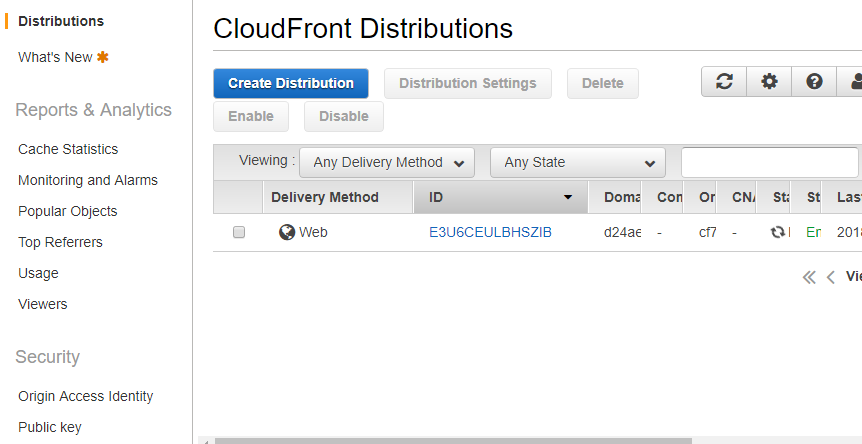
Alias resource record sets provide an Amazon Route 53 specific extension to DNS functionality. Instead of an IP address or a domain name, an alias resource record set contains a pointer to a CloudFront distribution, an ELB load balancer, an Amazon S3 bucket that is configured as a static website, or another Amazon Route 53 resource record set in the same hosted zone. When Amazon Route 53 receives a DNS query that matches the name and type in an alias resource record set, Amazon Route 53 follows the pointer and responds with the applicable value.
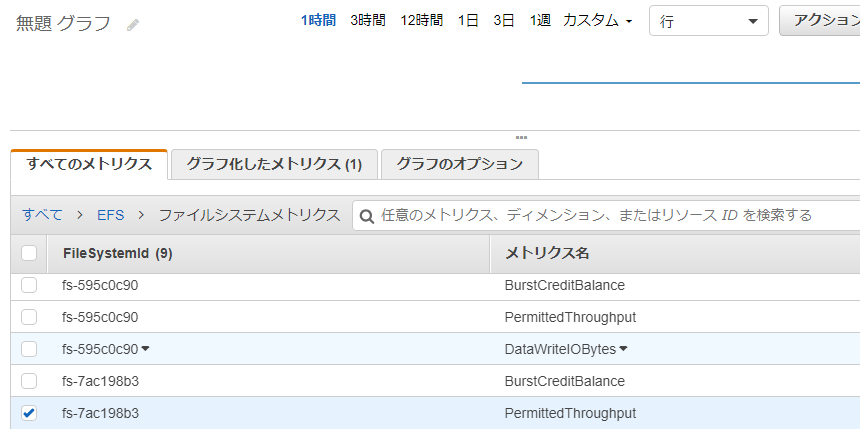
Resource Record Set
Resource record sets are the basic information elements of the domain name system. Each record set includes the name of a domain or a subdomain, a record type, and other information applicable to the record type.
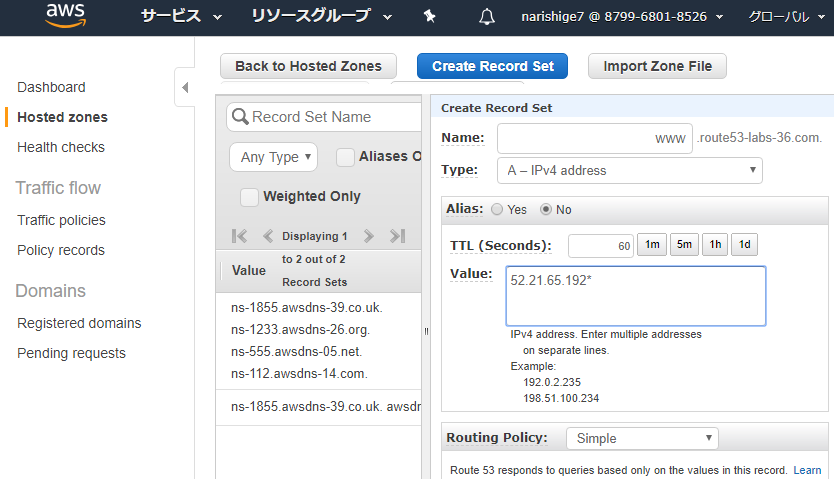
The Name Server (NS) Resource Record Set
Amazon Route 53 automatically creates a name server (NS) resource record set when you create a new hosted zone with the same name as your hosted zone. It lists the four name servers that are the authoritative name servers for your hosted zone. Do not add, change, or delete name servers in this resource record set.
For Example:
- ns-2048.awsdns-64.com
- ns-2049.awsdns-65.net
- ns-2050.awsdns-66.org
- ns-2051.awsdns-67.co.uk
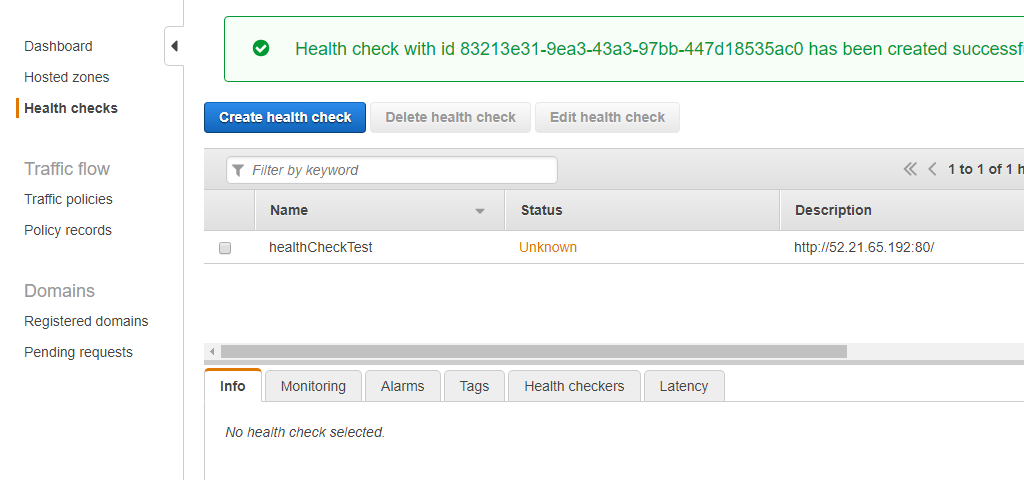
Health check