
mysqld –verbose –help
Variables (–variable-name=value)
and boolean options {FALSE|TRUE} Value (after reading options)
———————————————————- —————
abort-slave-event-count 0
allow-suspicious-udfs FALSE
archive ON
auto-increment-increment 1
auto-increment-offset 1
autocommit TRUE
automatic-sp-privileges TRUE
avoid-temporal-upgrade FALSE
back-log 80
basedir /usr/
big-tables FALSE
bind-address *
binlog-cache-size 32768
binlog-checksum CRC32
binlog-direct-non-transactional-updates FALSE
binlog-error-action IGNORE_ERROR
binlog-format STATEMENT
binlog-gtid-simple-recovery FALSE
binlog-max-flush-queue-time 0
binlog-order-commits TRUE
binlog-row-event-max-size 8192
binlog-row-image FULL
binlog-rows-query-log-events FALSE
binlog-stmt-cache-size 32768
binlogging-impossible-mode IGNORE_ERROR
blackhole ON
block-encryption-mode aes-128-ecb
bulk-insert-buffer-size 8388608
character-set-client-handshake TRUE
character-set-filesystem binary
character-set-server utf8
character-sets-dir /usr/share/mysql/charsets/
chroot (No default value)
collation-server utf8_general_ci
completion-type NO_CHAIN
concurrent-insert AUTO
connect-timeout 10
console FALSE
datadir /var/lib/mysql/
date-format %Y-%m-%d
datetime-format %Y-%m-%d %H:%i:%s
default-storage-engine InnoDB
default-time-zone (No default value)
default-tmp-storage-engine InnoDB
default-week-format 0
delay-key-write ON
delayed-insert-limit 100
delayed-insert-timeout 300
delayed-queue-size 1000
des-key-file (No default value)
disconnect-on-expired-password TRUE
disconnect-slave-event-count 0
div-precision-increment 4
end-markers-in-json FALSE
enforce-gtid-consistency FALSE
eq-range-index-dive-limit 10
event-scheduler OFF
expire-logs-days 0
explicit-defaults-for-timestamp FALSE
external-locking FALSE
federated ON
flush FALSE
flush-time 0
ft-boolean-syntax + -><()~*:""&|
ft-max-word-len 84
ft-min-word-len 4
ft-query-expansion-limit 20
ft-stopword-file (No default value)
gdb FALSE
general-log FALSE
general-log-file /var/lib/mysql/localhost.log
group-concat-max-len 1024
gtid-mode OFF
help TRUE
host-cache-size 279
ignore-builtin-innodb FALSE
init-connect
init-file (No default value)
init-slave
innodb ON
innodb-adaptive-flushing TRUE
innodb-adaptive-flushing-lwm 10
innodb-adaptive-hash-index TRUE
innodb-adaptive-max-sleep-delay 150000
innodb-additional-mem-pool-size 8388608
innodb-api-bk-commit-interval 5
innodb-api-disable-rowlock FALSE
innodb-api-enable-binlog FALSE
innodb-api-enable-mdl FALSE
innodb-api-trx-level 0
innodb-autoextend-increment 64
innodb-autoinc-lock-mode 1
innodb-buffer-page ON
innodb-buffer-page-lru ON
innodb-buffer-pool-dump-at-shutdown FALSE
innodb-buffer-pool-dump-now FALSE
innodb-buffer-pool-filename ib_buffer_pool
innodb-buffer-pool-instances 0
innodb-buffer-pool-load-abort FALSE
innodb-buffer-pool-load-at-startup FALSE
innodb-buffer-pool-load-now FALSE
innodb-buffer-pool-size 134217728
innodb-buffer-pool-stats ON
innodb-change-buffer-max-size 25
innodb-change-buffering all
innodb-checksum-algorithm innodb
innodb-checksums TRUE
innodb-cmp ON
innodb-cmp-per-index ON
innodb-cmp-per-index-enabled FALSE
innodb-cmp-per-index-reset ON
innodb-cmp-reset ON
innodb-cmpmem ON
innodb-cmpmem-reset ON
innodb-commit-concurrency 0
innodb-compression-failure-threshold-pct 5
innodb-compression-level 6
innodb-compression-pad-pct-max 50
innodb-concurrency-tickets 5000
innodb-data-file-path (No default value)
innodb-data-home-dir (No default value)
innodb-disable-sort-file-cache FALSE
innodb-doublewrite TRUE
innodb-fast-shutdown 1
innodb-file-format Antelope
innodb-file-format-check TRUE
innodb-file-format-max Antelope
innodb-file-io-threads 4
innodb-file-per-table TRUE
innodb-flush-log-at-timeout 1
innodb-flush-log-at-trx-commit 1
innodb-flush-method (No default value)
innodb-flush-neighbors 1
innodb-flushing-avg-loops 30
innodb-force-load-corrupted FALSE
innodb-force-recovery 0
innodb-ft-aux-table (No default value)
innodb-ft-being-deleted ON
innodb-ft-cache-size 8000000
innodb-ft-config ON
innodb-ft-default-stopword ON
innodb-ft-deleted ON
innodb-ft-enable-diag-print FALSE
innodb-ft-enable-stopword TRUE
innodb-ft-index-cache ON
innodb-ft-index-table ON
innodb-ft-max-token-size 84
innodb-ft-min-token-size 3
innodb-ft-num-word-optimize 2000
innodb-ft-result-cache-limit 2000000000
innodb-ft-server-stopword-table (No default value)
innodb-ft-sort-pll-degree 2
innodb-ft-total-cache-size 640000000
innodb-ft-user-stopword-table (No default value)
innodb-io-capacity 200
innodb-io-capacity-max 18446744073709551615
innodb-large-prefix FALSE
innodb-lock-wait-timeout 50
innodb-lock-waits ON
innodb-locks ON
innodb-locks-unsafe-for-binlog FALSE
innodb-log-buffer-size 8388608
innodb-log-compressed-pages TRUE
innodb-log-file-size 50331648
innodb-log-files-in-group 2
innodb-log-group-home-dir (No default value)
innodb-lru-scan-depth 1024
innodb-max-dirty-pages-pct 75
innodb-max-dirty-pages-pct-lwm 0
innodb-max-purge-lag 0
innodb-max-purge-lag-delay 0
innodb-metrics ON
innodb-mirrored-log-groups 0
innodb-monitor-disable (No default value)
innodb-monitor-enable (No default value)
innodb-monitor-reset (No default value)
innodb-monitor-reset-all (No default value)
innodb-numa-interleave FALSE
innodb-old-blocks-pct 37
innodb-old-blocks-time 1000
innodb-online-alter-log-max-size 134217728
innodb-open-files 0
innodb-optimize-fulltext-only FALSE
innodb-page-size 16384
innodb-print-all-deadlocks FALSE
innodb-purge-batch-size 300
innodb-purge-threads 1
innodb-random-read-ahead FALSE
innodb-read-ahead-threshold 56
innodb-read-io-threads 4
innodb-read-only FALSE
innodb-replication-delay 0
innodb-rollback-on-timeout FALSE
innodb-rollback-segments 128
innodb-sort-buffer-size 1048576
innodb-spin-wait-delay 6
innodb-stats-auto-recalc TRUE
innodb-stats-include-delete-marked FALSE
innodb-stats-method nulls_equal
innodb-stats-on-metadata FALSE
innodb-stats-persistent TRUE
innodb-stats-persistent-sample-pages 20
innodb-stats-sample-pages 8
innodb-stats-transient-sample-pages 8
innodb-status-file FALSE
innodb-status-output FALSE
innodb-status-output-locks FALSE
innodb-strict-mode FALSE
innodb-support-xa TRUE
innodb-sync-array-size 1
innodb-sync-spin-loops 30
innodb-sys-columns ON
innodb-sys-datafiles ON
innodb-sys-fields ON
innodb-sys-foreign ON
innodb-sys-foreign-cols ON
innodb-sys-indexes ON
innodb-sys-tables ON
innodb-sys-tablespaces ON
innodb-sys-tablestats ON
innodb-table-locks TRUE
innodb-thread-concurrency 0
innodb-thread-sleep-delay 10000
innodb-tmpdir (No default value)
innodb-trx ON
innodb-undo-directory .
innodb-undo-logs 128
innodb-undo-tablespaces 0
innodb-use-native-aio TRUE
innodb-use-sys-malloc TRUE
innodb-write-io-threads 4
interactive-timeout 28800
join-buffer-size 262144
keep-files-on-create FALSE
key-buffer-size 8388608
key-cache-age-threshold 300
key-cache-block-size 1024
key-cache-division-limit 100
language /usr/share/mysql/
large-pages FALSE
lc-messages en_US
lc-messages-dir /usr/share/mysql/
lc-time-names en_US
local-infile TRUE
lock-wait-timeout 31536000
log-bin (No default value)
log-bin-index (No default value)
log-bin-trust-function-creators FALSE
log-bin-use-v1-row-events FALSE
log-error
log-isam myisam.log
log-output FILE
log-queries-not-using-indexes FALSE
log-raw FALSE
log-short-format FALSE
log-slave-updates FALSE
log-slow-admin-statements FALSE
log-slow-slave-statements FALSE
log-tc tc.log
log-tc-size 24576
log-throttle-queries-not-using-indexes 0
log-warnings 1
long-query-time 10
low-priority-updates FALSE
lower-case-table-names 0
master-info-file master.info
master-info-repository FILE
master-retry-count 86400
master-verify-checksum FALSE
max-allowed-packet 4194304
max-binlog-cache-size 18446744073709547520
max-binlog-dump-events 0
max-binlog-size 1073741824
max-binlog-stmt-cache-size 18446744073709547520
max-connect-errors 100
max-connections 151
max-delayed-threads 20
max-digest-length 1024
max-error-count 64
max-heap-table-size 16777216
max-join-size 18446744073709551615
max-length-for-sort-data 1024
max-prepared-stmt-count 16382
max-relay-log-size 0
max-seeks-for-key 18446744073709551615
max-sort-length 1024
max-sp-recursion-depth 0
max-tmp-tables 32
max-user-connections 0
max-write-lock-count 18446744073709551615
memlock FALSE
metadata-locks-cache-size 1024
metadata-locks-hash-instances 8
min-examined-row-limit 0
multi-range-count 256
myisam-block-size 1024
myisam-data-pointer-size 6
myisam-max-sort-file-size 9223372036853727232
myisam-mmap-size 18446744073709551615
myisam-recover-options OFF
myisam-repair-threads 1
myisam-sort-buffer-size 8388608
myisam-stats-method nulls_unequal
myisam-use-mmap FALSE
net-buffer-length 16384
net-read-timeout 30
net-retry-count 10
net-write-timeout 60
new FALSE
old FALSE
old-alter-table FALSE
old-passwords 0
old-style-user-limits FALSE
open-files-limit 1024
optimizer-prune-level 1
optimizer-search-depth 62
optimizer-switch index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on
optimizer-trace
optimizer-trace-features greedy_search=on,range_optimizer=on,dynamic_range=on,repeated_subselect=on
optimizer-trace-limit 1
optimizer-trace-max-mem-size 16384
optimizer-trace-offset -1
partition ON
performance-schema TRUE
performance-schema-accounts-size -1
performance-schema-consumer-events-stages-current FALSE
performance-schema-consumer-events-stages-history FALSE
performance-schema-consumer-events-stages-history-long FALSE
performance-schema-consumer-events-statements-current TRUE
performance-schema-consumer-events-statements-history FALSE
performance-schema-consumer-events-statements-history-long FALSE
performance-schema-consumer-events-waits-current FALSE
performance-schema-consumer-events-waits-history FALSE
performance-schema-consumer-events-waits-history-long FALSE
performance-schema-consumer-global-instrumentation TRUE
performance-schema-consumer-statements-digest TRUE
performance-schema-consumer-thread-instrumentation TRUE
performance-schema-digests-size -1
performance-schema-events-stages-history-long-size -1
performance-schema-events-stages-history-size -1
performance-schema-events-statements-history-long-size -1
performance-schema-events-statements-history-size -1
performance-schema-events-waits-history-long-size -1
performance-schema-events-waits-history-size -1
performance-schema-hosts-size -1
performance-schema-instrument
performance-schema-max-cond-classes 80
performance-schema-max-cond-instances -1
performance-schema-max-digest-length 1024
performance-schema-max-file-classes 50
performance-schema-max-file-handles 32768
performance-schema-max-file-instances -1
performance-schema-max-mutex-classes 200
performance-schema-max-mutex-instances -1
performance-schema-max-rwlock-classes 40
performance-schema-max-rwlock-instances -1
performance-schema-max-socket-classes 10
performance-schema-max-socket-instances -1
performance-schema-max-stage-classes 150
performance-schema-max-statement-classes 168
performance-schema-max-table-handles -1
performance-schema-max-table-instances -1
performance-schema-max-thread-classes 50
performance-schema-max-thread-instances -1
performance-schema-session-connect-attrs-size -1
performance-schema-setup-actors-size 100
performance-schema-setup-objects-size 100
performance-schema-users-size -1
pid-file /var/lib/mysql/localhost.pid
plugin-dir /usr/lib64/mysql/plugin/
port 3306
port-open-timeout 0
preload-buffer-size 32768
profiling-history-size 15
query-alloc-block-size 8192
query-cache-limit 1048576
query-cache-min-res-unit 4096
query-cache-size 1048576
query-cache-type OFF
query-cache-wlock-invalidate FALSE
query-prealloc-size 8192
range-alloc-block-size 4096
read-buffer-size 131072
read-only FALSE
read-rnd-buffer-size 262144
relay-log (No default value)
relay-log-index (No default value)
relay-log-info-file relay-log.info
relay-log-info-repository FILE
relay-log-purge TRUE
relay-log-recovery FALSE
relay-log-space-limit 0
replicate-same-server-id FALSE
report-host (No default value)
report-password (No default value)
report-port 0
report-user (No default value)
rpl-stop-slave-timeout 31536000
safe-user-create FALSE
secure-auth TRUE
secure-file-priv /var/lib/mysql-files/
server-id 0
server-id-bits 32
show-old-temporals FALSE
show-slave-auth-info FALSE
simplified-binlog-gtid-recovery FALSE
skip-grant-tables FALSE
skip-name-resolve FALSE
skip-networking FALSE
skip-show-database FALSE
skip-slave-start FALSE
slave-allow-batching FALSE
slave-checkpoint-group 512
slave-checkpoint-period 300
slave-compressed-protocol FALSE
slave-exec-mode STRICT
slave-load-tmpdir /tmp
slave-max-allowed-packet 1073741824
slave-net-timeout 3600
slave-parallel-workers 0
slave-pending-jobs-size-max 16777216
slave-rows-search-algorithms TABLE_SCAN,INDEX_SCAN
slave-skip-errors (No default value)
slave-sql-verify-checksum TRUE
slave-transaction-retries 10
slave-type-conversions
slow-launch-time 2
slow-query-log FALSE
slow-query-log-file /var/lib/mysql/localhost-slow.log
socket /var/lib/mysql/mysql.sock
sort-buffer-size 262144
sporadic-binlog-dump-fail FALSE
sql-mode NO_ENGINE_SUBSTITUTION
ssl FALSE
ssl-ca (No default value)
ssl-capath (No default value)
ssl-cert (No default value)
ssl-cipher (No default value)
ssl-crl (No default value)
ssl-crlpath (No default value)
ssl-key (No default value)
stored-program-cache 256
super-large-pages FALSE
symbolic-links FALSE
sync-binlog 0
sync-frm TRUE
sync-master-info 10000
sync-relay-log 10000
sync-relay-log-info 10000
sysdate-is-now FALSE
table-definition-cache 615
table-open-cache 431
table-open-cache-instances 1
tc-heuristic-recover COMMIT
temp-pool TRUE
thread-cache-size 9
thread-concurrency 10
thread-handling one-thread-per-connection
thread-stack 262144
time-format %H:%i:%s
timed-mutexes FALSE
tmp-table-size 16777216
tmpdir /tmp
transaction-alloc-block-size 8192
transaction-isolation REPEATABLE-READ
transaction-prealloc-size 4096
transaction-read-only FALSE
updatable-views-with-limit YES
validate-user-plugins TRUE
verbose TRUE
wait-timeout 28800
To see what values a running MySQL server is using, type
'mysqladmin variables' instead of 'mysqld --verbose --help'.
2018-09-19 21:19:42 11464 [Note] Binlog end
2018-09-19 21:19:42 11464 [Note] Shutting down plugin 'CSV'
2018-09-19 21:19:42 11464 [Note] Shutting down plugin 'MyISAM'
なんじゃこりゃ
my.cnfの中身を見てみよう
datadir, socket, character_set_server, default-storeage-engine, innodb_file_per_table, symbolic-link, log-err, pid
[vagrant@localhost app]$ cat /etc/my.cnf [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock character_set_server=utf8 default-storage-engine=InnoDB innodb_file_per_table # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used (fedora >= 15). # If you need to run mysqld under a different user or group, # customize your systemd unit file for mysqld according to the # instructions in http://fedoraproject.org/wiki/Systemd user=mysql # Semisynchronous Replication # http://dev.mysql.com/doc/refman/5.5/en/replication-semisync.html # uncomment next line on MASTER ;plugin-load=rpl_semi_sync_master=semisync_master.so # uncomment next line on SLAVE ;plugin-load=rpl_semi_sync_slave=semisync_slave.so # Others options for Semisynchronous Replication ;rpl_semi_sync_master_enabled=1 ;rpl_semi_sync_master_timeout=10 ;rpl_semi_sync_slave_enabled=1 # http://dev.mysql.com/doc/refman/5.5/en/performance-schema.html ;performance_schema [mysql] default-character-set=utf8 [mysqldump] default-character-set=utf8 [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid # # include all files from the config directory # !includedir /etc/my.cnf.d
なるほど、ディレクトリパスを記載していますね。
シェルスクリプト
#!/bin/sh echo "Hello World!"
./hello.sh で動かします。
[vagrant@localhost app]$ ./hello.sh
-bash: ./hello.sh: 許可がありません
permission denied.
[vagrant@localhost app]$ cat -e hello.sh
#!/bin/sh^M$
echo “Hello World!”
改行コードがおかしいみたい。
[vagrant@localhost app]$ sed -i ‘s/\r//’ hello.sh
[vagrant@localhost app]$ ./hello.sh
Hello World!
What is Amazon EBS?
Amazon Elastic Block Store (Amazon EBS) provides persistent block level storage volumes for use with Amazon EC2 instances in the AWS Cloud. Each Amazon EBS volume is automatically replicated within its Availability Zone to protect you from component failure, offering high availability and durability. Amazon EBS volumes offer the consistent and low-latency performance needed to run your workloads. With Amazon EBS, you can scale your usage up or down within minutes – all while paying a low price for only what you provision.
Elastic Block Store
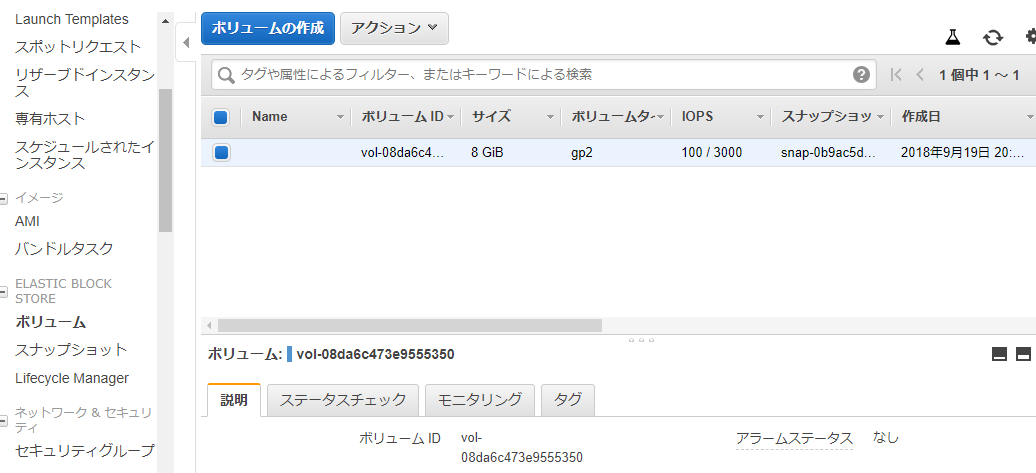
スナップショットは作られてますね。
スナップショットとは… Amazon EBSボリュームのデータを Amazon S3 にバックアップ
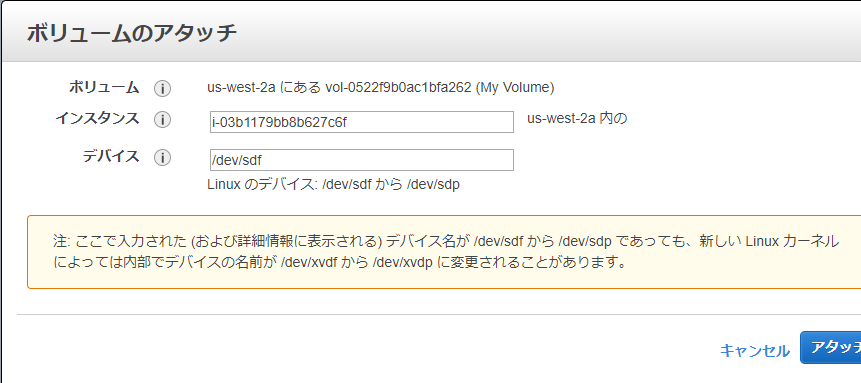
volumeを作成してEC2にattachする。
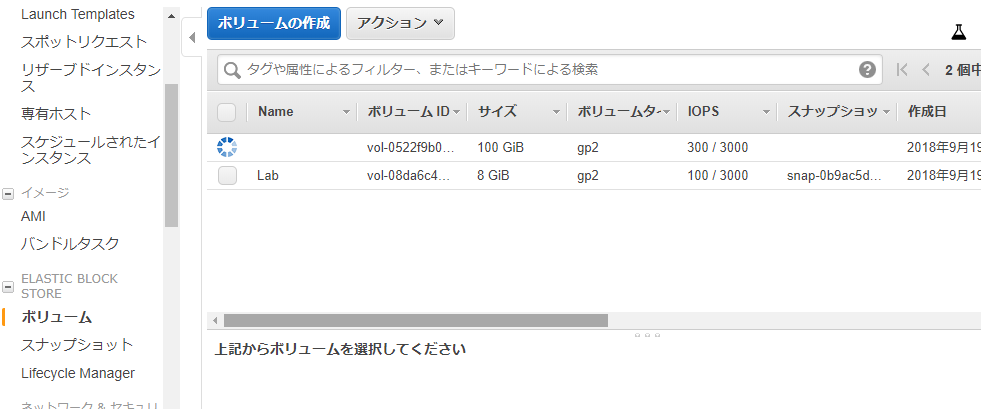
actionからattachする
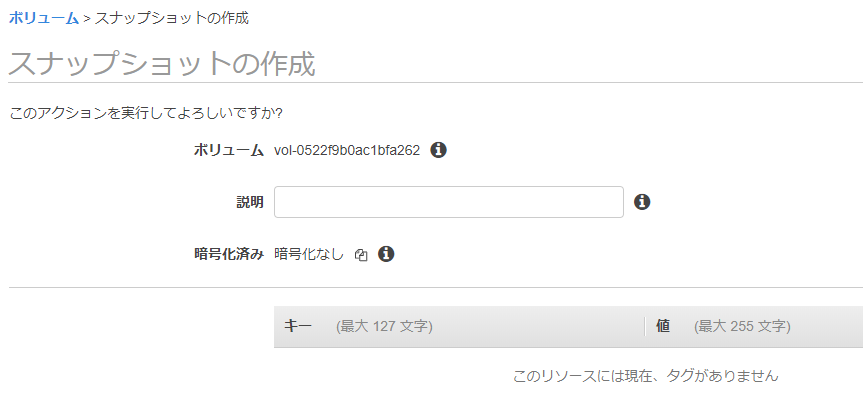
snapshotの作成でS3にバックアップされる。
modify
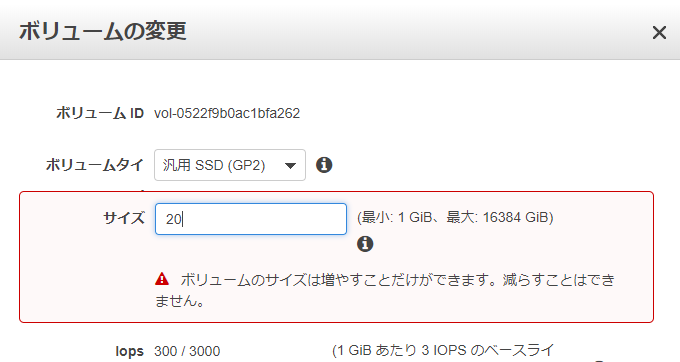
なるほど~
EBSスナップショット
ポイントインタイムスナップショットを作成することで、Amazon EBSボリュームのデータを Amazon S3 にバックアップできる。
スナップショットは増分バックアップ。
最後にスナップショットを作成した時点から、ボリューム上で変更のあるブロックだけが保存される。これにより、スナップショットを作成するのに要する時間が最小限に抑えられ、データを複製しないことで、ストレージコストが節約されます。スナップショットを削除すると、そのスナップショットに固有のデータだけが削除されます。各スナップショットには、(スナップショットを作成した瞬間から) データを新しい EBS ボリュームに復元するために必要な情報がすべて含まれる。
Amazon Elastic Block Store (Amazon EBS) は、AWS クラウド内で Amazon EC2 インスタンスと組み合わせて使用できる、永続的なブロックストレージボリューム
php artisan
[vagrant@localhost agile]$ php -v
PHP 7.1.21 (cli) (built: Aug 15 2018 18:11:46) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.1.0, Copyright (c) 1998-2018 Zend Technologies
composerを入れてlaravelを入れます。
[vagrant@localhost agile]$ php composer.phar create-project –prefer-dist laravel/laravel
[vagrant@localhost agile]$ cd laravel
[vagrant@localhost laravel]$ php artisan –version
Laravel Framework 5.7.4
access時間をinsert
mysql> use redirect
Database changed
mysql> select * from url
-> ;
+—-+——+—————————+
| no | id | url |
+—-+——+—————————+
| 1 | 001 | https://www.facebook.com/ |
| 2 | 002 | https://www.amazon.com/ |
| 3 | 003 | https://www.apple.com |
| 4 | 004 | https://www.google.com |
+—-+——+—————————+
4 rows in set (0.00 sec)
mysql> create table accesstime (
-> no int unsigned auto_increment primary key,
-> id varchar(11),
-> time datetime
-> );
Query OK, 0 rows affected (0.21 sec)
$date = new DateTime();
$datetime = $date->format('Y-m-d H:i:s');
echo $datetime;
if(isset($_GET["id"])){
$id = $_GET["id"];
} else {
$id = "001";
}
try {
$pdo = new PDO('mysql:host=localhost;dbname=redirect;charset=utf8','root','',
array(PDO::ATTR_EMULATE_PREPARES => false));
} catch (PDOException $e) {
exit('データベース接続失敗。'.$e->getMessage());
}
$stmt = $pdo->query("SELECT * FROM url where id = $id");
$row = $stmt -> fetch(PDO::FETCH_ASSOC);
$url = "location: " .$row["url"]. "";
$stmt1 = $pdo -> prepare("INSERT INTO accesstime (id, time) VALUES (:id, :time)");
$stmt1->bindParam(':id', $id, PDO::PARAM_STR);
$stmt1->bindParam(':time', $datetime, PDO::PARAM_STR);
$stmt1->execute();
header($url);
idとaccess時間がtable accesstimeに入ってますね♪
mysql> select * from accesstime;
+—-+——+———————+
| no | id | time |
+—-+——+———————+
| 1 | 001 | 2018-09-19 01:03:54 |
+—-+——+———————+
1 row in set (0.00 sec)
さあ、laravelをやりましょう。
idとurlを格納
mysql
mysql> insert into url(id, url) values
-> (‘001’, ‘https://www.facebook.com/’),
-> (‘002’, ‘https://www.amazon.com/’),
-> (‘003’, ‘https://www.apple.com’),
-> (‘004’, ‘https://www.google.com’);
Query OK, 4 rows affected (0.15 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from url;
+—-+——+—————————+
| no | id | url |
+—-+——+—————————+
| 1 | 1 | https://www.facebook.com/ |
| 2 | 2 | https://www.amazon.com/ |
| 3 | 3 | https://www.apple.com |
| 4 | 4 | https://www.google.com |
+—-+——+—————————+
4 rows in set (0.00 sec)
あら、idが001ではなく、1になってますね。
drop tableしてvarchar(11)に変更します。
create table url (
no int unsigned auto_increment primary key,
id varchar(11),
url varchar(255)
);
パラメーターのURLをfetchする。
if(isset($_GET["id"])){
$id = $_GET["id"];
} else {
$id = "001";
}
try {
$pdo = new PDO('mysql:host=localhost;dbname=redirect;charset=utf8','root','',
array(PDO::ATTR_EMULATE_PREPARES => false));
} catch (PDOException $e) {
exit('データベース接続失敗。'.$e->getMessage());
}
$stmt = $pdo->query("SELECT * FROM url where id = $id");
$row = $stmt -> fetch(PDO::FETCH_ASSOC);
echo $row["url"];
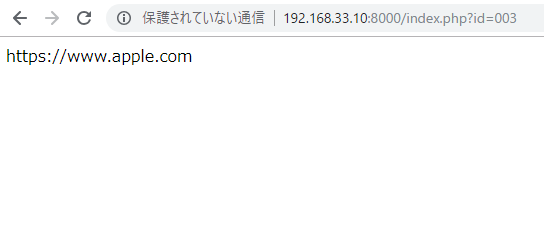
リダイレクト処理。awsでキャッシュさせれば、少し早くなるか。
if(isset($_GET["id"])){
$id = $_GET["id"];
} else {
$id = "001";
}
try {
$pdo = new PDO('mysql:host=localhost;dbname=redirect;charset=utf8','root','',
array(PDO::ATTR_EMULATE_PREPARES => false));
} catch (PDOException $e) {
exit('データベース接続失敗。'.$e->getMessage());
}
$stmt = $pdo->query("SELECT * FROM url where id = $id");
$row = $stmt -> fetch(PDO::FETCH_ASSOC);
$url = "location: " .$row["url"]. "";
header($url);
Amazon ElastiCache:Amazon ElastiCache は、クラウドでのインメモリデータストアまたはキャッシュのデプロイ、運用、およびスケールを容易にするウェブサービスです。このサービスは、低速のディスクベースのデータベースに完全に依存せずに、高速のマネージド型インメモリデータストアから情報を取得できるようにすることで、ウェブアプリケーションのパフォーマンスを向上させます。
これか?
>メモリはディスク (磁気または SSD) よりも桁違いに高速であるため、インメモリキャッシュからのデータ読み取りは非常に高速 (ミリ秒以下) です。このきわめて高速なデータアクセスにより、アプリケーションの全体的なパフォーマンスが向上します。
TinyMCE
文章を見たまま編集(WYSIWYG。What you see is what you get)できるエディタのライブラリ
-プラグインなどによる機能が豊富
-WordPressに採用
-ツールバーの追加、ボタン位置の入替や削除、独自ボタンの追加などカスタマイズが柔軟
tinyMCEのself hostedからdownloadする
https://www.tiny.cloud/download/self-hosted/
4.8.2が最新版
CDNもあるようですが、今回は最新版パッケージをダウンロードします。
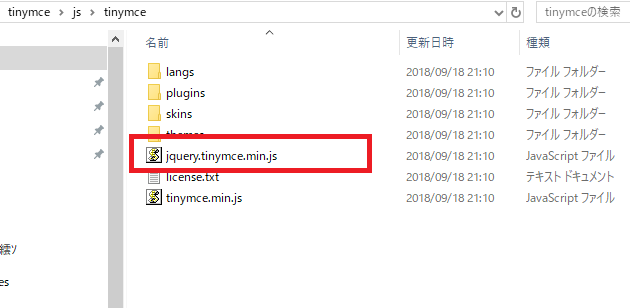
minifiedされた jquery.tinymce.min.jsを使うようですな。
プラグインはthemesなどバリエーションが豊富ですね。
githubはこちら
https://github.com/tinymce/tinymce
とりあえずforkしておきましょう。
早速vagrantで使ってみましょう。
<!Doctype html>
<html>
<head>
<meta charset="UTF-8">
<script src="tinymce/js/tinymce/tinymce.min.js"></script>
<script>
tinymce.init({
selector: "#foo",
});
</script>
</head>
<body>
<h1>TinyMCEの動作テスト</h1>
<textarea id="foo" name="foo">最初に入力する文章</textarea>
<h2>入力チェック</h2>
</body>
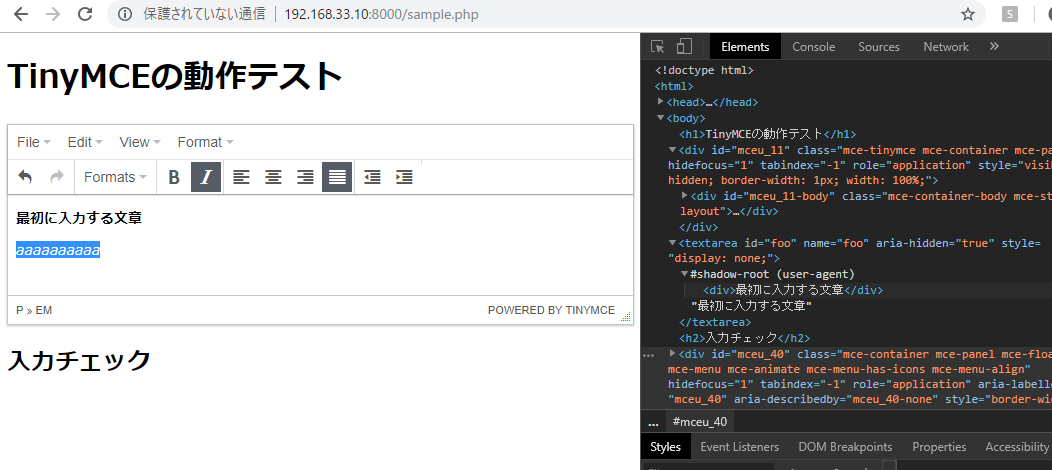
</html>
devtoolで見てるが、仕組みがようわからん。。。
RDS リードレプリカを追加する
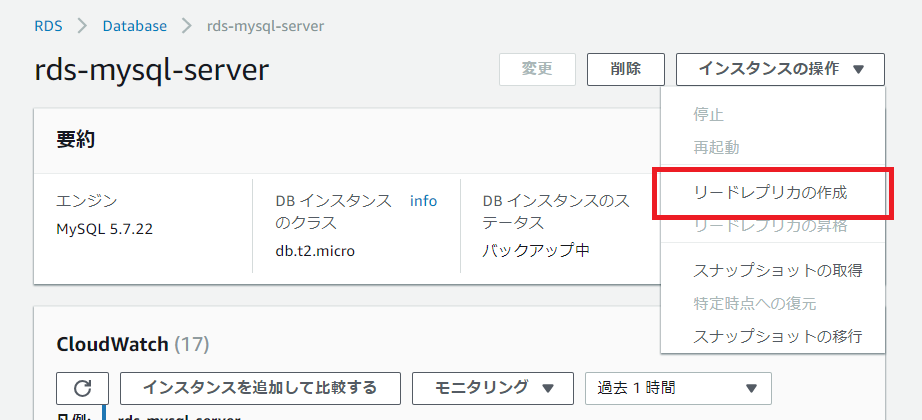
リードレプリカの作成を押下すると、
– 送信先リージョン
– サブネットグループ
– アベイラビリティーゾーン
– 暗号化
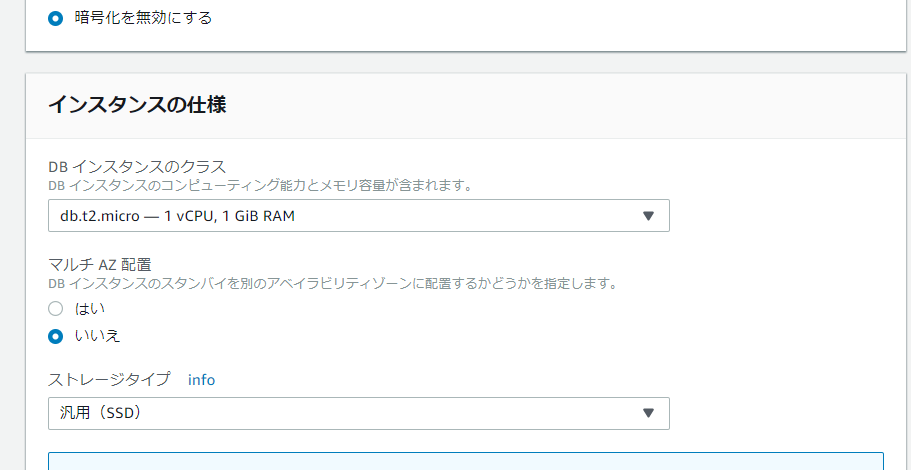
– インスタンスの仕様
インスタンスのクラスも設定できる
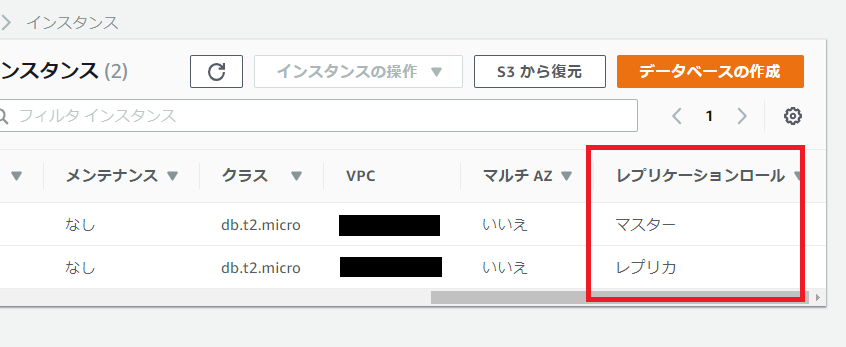
レプリケーションロールがマスタとレプリカとなる。
CPU クレジット残高は、CPU 利用率がベースラインを上回り、前の 5 分間に消費したクレジットが獲得したクレジットよりも多かった場合に減少します。