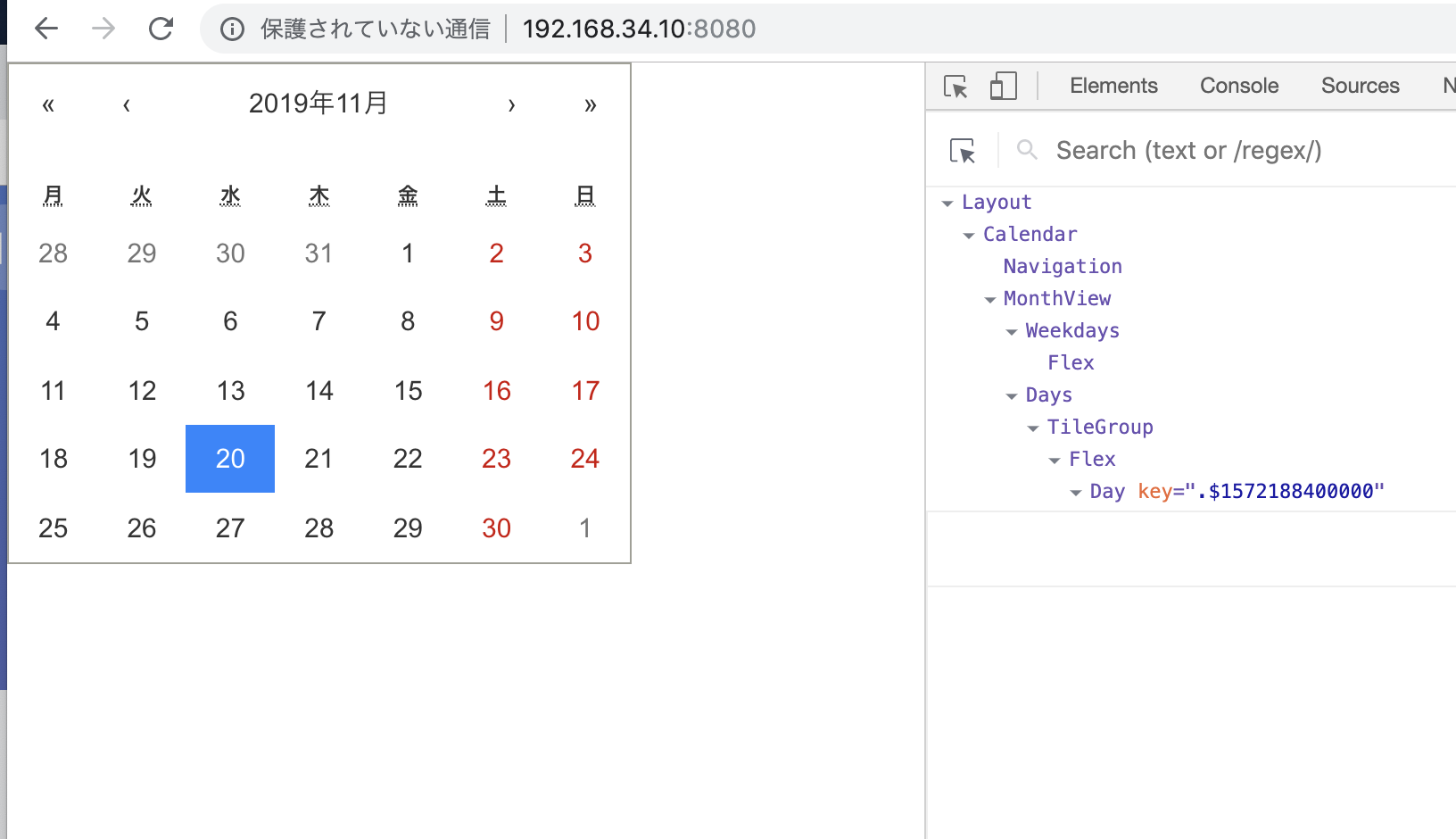
<li ng-repeat="user in users" ng-controller="UserItemController">
{{user.name|uppercase}} {{user.score}}
<button ng-click="increment()">+1</button>
</li>
angular.module('myapp', [])
.controller('MainController', ['$scope', function($scope) {
$scope.users = [
{"name":"taguchi", "score":52.22},
{"name":"tanaka", "score":38.22},
{"name":"yamada", "score":11.11},
{"name":"goto", "score":22.22},
{"name":"kurumi", "score":58.22},
{"name":"sakamoto", "score":81.11},
];
$scope.today = new Date();
}])
.controller('UserItemController', ['$scope', function($scope){
$scope.increment = function(){
$scope.user.score++;
};
}]);
やっぱGoogleはリアルタイム処理とか高速処理がめちゃくちゃ強いな。会社作った時からそーなんだろうけど、何でだろう。。
<div ng-controller="MainController">
<form name="myName" ng-submit="addUser()">
<p>Name:<input type="text" name="name" ng-model="user.name"></p>
<p><input type="submit" value="add"></p>
<pre>{{user|json}}</pre>
</form>
</div>
フォームのバリデーションはhtml5やサーバーサイド側でもできるけど、DBに入力しない問い合わせフォームのバリデーションはangularでもいいかもね。
<form novalidate name="myForm" ng-submit="addUser()">
<p>Name:<input type="text" name="name" ng-model="user.name" required ng-minlength="5" ng-maxlength="8">
<span ng-show="myForm.name.$error.required">Required!</span>
<span ng-show="myForm.name.$error.minlength">too short!</span>
<span ng-show="myForm.name.$error.maxlength">too long!</span></p>
<p><input type="submit" value="add"></p>
<pre>{{user|json}}</pre>
</form>
emailは正規表現のルールはデフォルトがあるのか、これは自分で決めたいよね。
<form novalidate name="myForm" ng-submit="addUser()">
<p>score:<input type="number" name="score" ng-model="user.score">
</p>
<p>email:<input type="email" name="email" ng-model="user.email">
<span ng-show="myForm.email.$error.email">Not valide email</span></p>
<p><input type="submit" value="add"></p>
<p>web:<input type="url" name="url" ng-model="user.url">
<span ng-show="myForm.url.$error.url">Not valide url</span></p>
<pre>{{user|json}}</pre>
</form>