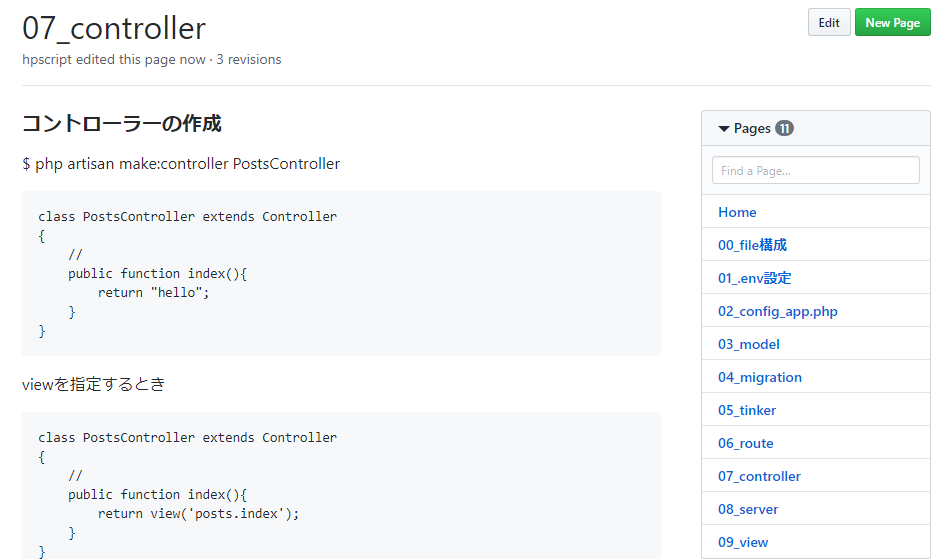
変数の$idとその名前’id’を一緒に渡す
public function show_post($id){
return view('post')->with('id', $id);
}
post.blade.php
<div class="container">
<h1>Post {{ $id }}</h1>
</div>
databaseから値を持ってくる際は、変数をfunctionの中で定義するが、routingの場合も仕組みは同じ
with(‘id’, $id)は、compact(‘id’)とも書ける
return view('post', compact('id'));
表示は、->with(‘id’, $id) と同じ
複数渡す場合
Route::get('post/{id}/{name}/{password}', 'PostsController@show_post');
public function show_post($id, $name, $password){
// return view('post')->with('id', $id);
return view('post', compact('id','name','password'));
}
<div class="container">
<h1>Post {{ $id }} {{ $name }} {{ $password }}</h1>
</div>
It’s sweet, isn’t it!