深層学習では、損失関数として使用されるクロスエントロピーを最小化させる為に、ベクトルθを繰り返し更新する
勾配降下法でもっとも下りが低くなる方向に進む(gradient descent, steepest descent)
訓練データから繰り返しサンプルを取り出し、勾配を計算する
サンプルの集合をミニバッチと呼ぶ
各層のパラメータを使って予測を行う 計算は入力層から出力層に向かって行われる
コーディングと理論の学習を並行して行った方が効率が良いな。
随机应变 ABCD: Always Be Coding and … : хороший

深層学習では、損失関数として使用されるクロスエントロピーを最小化させる為に、ベクトルθを繰り返し更新する
勾配降下法でもっとも下りが低くなる方向に進む(gradient descent, steepest descent)
訓練データから繰り返しサンプルを取り出し、勾配を計算する
サンプルの集合をミニバッチと呼ぶ
各層のパラメータを使って予測を行う 計算は入力層から出力層に向かって行われる
コーディングと理論の学習を並行して行った方が効率が良いな。
keras parameter
– input_dim: the size of the vocabulary
– output_dim: the size of the dense vector
– input_length: the length of the sequence
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
// 省略
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(sentences_train)
X_train = tokenizer.texts_to_sequences(sentences_train)
X_test = tokenizer.texts_to_sequences(sentences_test)
vocab_size = len(tokenizer.word_index) + 1
embedding_dim = 50
maxlen = 100
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
print(model.summary())
$ python3 test.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 50) 87350
_________________________________________________________________
flatten (Flatten) (None, 5000) 0
_________________________________________________________________
dense (Dense) (None, 10) 50010
_________________________________________________________________
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 137,371
Trainable params: 137,371
Non-trainable params: 0
_________________________________________________________________
None
history = model.fit(X_train, y_train,
epochs=20,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Testing Accuracy: {:.4f}".format(accuracy))
plot_history(history)
ValueError: Failed to find data adapter that can handle input: (
何でやろう。。。。
model = Sequential()
model.add(layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=maxlen))
model.add(layers.GlobalMaxPool1D())
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d (Global (None, 50) 0
_________________________________________________________________
dense (Dense) (None, 10) 510
_________________________________________________________________
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 87,871
Trainable params: 87,871
Non-trainable params: 0
_________________________________________________________________
なんかこんがらがってきた。。
### Embeddingとは?
自然言語処理におけるEmbeddingとは、「文や単語、文字など自然言語の構成要素に対して何らかの空間におけるベクトルを与えること」
There are various ways to vectorize text
– Words represented by each word as a vector
– Characters represented by each character as a vector
– N-grams of words/characters represented as a vector
### One-Hot Encoding
taking a vector of the length of the vocabulary with the entry for each word in the corpus
cities = ['London', 'Berlin', 'Berlin', 'New York', 'London'] print(cities)
$ python3 one-hot.py
[‘London’, ‘Berlin’, ‘Berlin’, ‘New York’, ‘London’]
label encode
from sklearn.preprocessing import LabelEncoder cities = ['London', 'Berlin', 'Berlin', 'New York', 'London'] encoder = LabelEncoder() city_labels = encoder.fit_transform(cities) print(city_labels)
$ python3 one-hot.py
[1 0 0 2 1]
Using OneHotEncoder
from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder cities = ['London', 'Berlin', 'Berlin', 'New York', 'London'] encoder = LabelEncoder() city_labels = encoder.fit_transform(cities) encoder = OneHotEncoder(sparse=False) city_labels = city_labels.reshape((5, 1)) array = encoder.fit_transform(city_labels) print(array)
$ python3 one-hot.py
[[0. 1. 0.]
[1. 0. 0.]
[1. 0. 0.]
[0. 0. 1.]
[0. 1. 0.]]
### Word Embeddings
The word embeddings collect more information into fewer dimensions.
To map semantic meaning into a geometric space called embedding space.
famous e.g. “King – Man + Woman = Queen”
from keras.preprocessing.text import Tokenizer // 省略 tokenizer = Tokenizer(num_words=5000) tokenizer.fit_on_texts(sentences_train) X_train = tokenizer.texts_to_sequences(sentences_train) X_test = tokenizer.texts_to_sequences(sentences_test) vocab_size = len(tokenizer.word_index) + 1 # adding 1 because of reserved 0 index print(sentences_train[2]) print(X_train[2])
$ python3 split.py
Of all the dishes, the salmon was the best, but all were great.
[11, 43, 1, 171, 1, 283, 3, 1, 47, 26, 43, 24, 22]
for word in ['the', 'all', 'happy', 'sad']:
print('{}: {}'.format(word, tokenizer.word_index[word]))
the: 1
all: 43
happy: 320
sad: 450
sklearnのCountVectorizerはwordのvector
kerasのTokenizerはwordのvalues
pad_sequences
from keras.preprocessing.sequence import pad_sequences maxlen = 100 X_train = pad_sequences(X_train, padding='post', maxlen=maxlen) X_test = pad_sequences(X_test, padding='post', maxlen=maxlen) print(X_train[0, :])
$ python3 split.py
raise TypeError(“sparse matrix length is ambiguous; use getnnz()”
TypeError: sparse matrix length is ambiguous; use getnnz() or shape[0]
何やと。。。
– Neural network model
> We have to multiply each input node by a weight w and add a bias b.
> It is generally common to use a rectified linear unit (ReLU) for hidden layers, a sigmoid function for the output layer in a binary classification problem, or a softmax function for the output layer of multi-class classification problems.
### Keras
– Keras is a deep learning and neural networks API by Francois Chollet
$ pip3 install keras
kerasを使うにはbackgroundにtensorflowが動いていないといけないので、amazon linux2にtensorflowをインストールします。
$ pip3 install tensorflow
$ python3 -c “import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))”
tf.Tensor(-784.01, shape=(), dtype=float32)
上手くインストールできたようです。
from keras.models import Sequential from keras import layers // 省略 input_dim = X_train.shape[1] model = Sequential() model.add(layers.Dense(10, input_dim=input_dim, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
model.add(layers.Dense(10, input_dim=input_dim, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) print(model.summary())
$ python3 split.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 17150
_________________________________________________________________
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 17,161
Trainable params: 17,161
Non-trainable params: 0
_________________________________________________________________
None
### batch size
history = model.fit(X_train, y_train, epochs=100, verbose=False, validation_data=(X_test, y_test) batch_size=10)
### evaluate accuracy
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Training Accuracy: {:.4f}".format(accuracy))
$ python3 split.py
Training Accuracy: 1.0000
Training Accuracy: 0.8040
### matplotlib
$ pip3 install matplotlib
import matplotlib.pyplot as plt
// 省略
def plot_history(history):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
x = range(1, len(acc) + 1)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(x, acc, 'b', label='Training acc')
plt.plot(x, val_acc, 'r', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(x, loss, 'b', label='Training loss')
plt.plot(x, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.savefig("img.png")
plot_history(history)
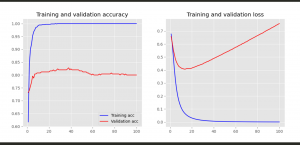
おおお、なんか凄え
#### choosing a Data Set
Sentiment Labelled Sentences Data Set
https://archive.ics.uci.edu/ml/machine-learning-databases/00331/
※Yelpはビジネスレビューサイト(食べログのようなもの)
※imdbは映画、テレビなどのレビューサイト
こちらから、英文のポジティブ、ネガティブのデータセットを取得します。
$ ls
amazon_cells_labelled.txt imdb_labelled.txt readme.txt yelp_labelled.txt
import pandas as pd
filepath_dict = {
'yelp': 'data/yelp_labelled.txt',
'amazon': 'data/amazon_cells_labelled.txt',
'imdb': 'data/imdb_labelled.txt'
}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source
df_list.append(df)
df = pd.concat(df_list)
print(df.iloc[0])
$ python3 app.py
sentence Wow… Loved this place.
label 1
source yelp
Name: 0, dtype: object
This data, predict sentiment of sentence.
vocabularyごとにベクトル化して重みを学習して判定する
>>> sentences = [‘John likes ice cream’, ‘John hates chocolate.’]
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vectorizer = CountVectorizer(min_df=0, lowercase=False)
>>> vectorizer.fit(sentences)
CountVectorizer(lowercase=False, min_df=0)
>>> vectorizer.vocabulary_
{‘John’: 0, ‘likes’: 5, ‘ice’: 4, ‘cream’: 2, ‘hates’: 3, ‘chocolate’: 1}
>>> vectorizer.transform(sentences).toarray()
array([[1, 0, 1, 0, 1, 1],
[1, 1, 0, 1, 0, 0]])
### Defining Baseline Model
First, split the data into a training and testing set
from sklearn.model_selection import train_test_split
import pandas as pd
filepath_dict = {
'yelp': 'data/yelp_labelled.txt',
'amazon': 'data/amazon_cells_labelled.txt',
'imdb': 'data/imdb_labelled.txt'
}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source
df_list.append(df)
df = pd.concat(df_list)
df_yelp = df[df['source'] == 'yelp']
sentences = df_yelp['sentence'].values
y = df_yelp['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
.value return NumPy array
from sklearn.feature_extraction.text import CountVectorizer // 省略 sentences_train, sentences_test, y_train, y_test = train_test_split( sentences, y, test_size=0.25, random_state=1000) vectorizer = CountVectorizer() vectorizer.fit(sentences_train) X_train = vectorizer.transform(sentences_train) X_test = vectorizer.transform(sentences_test) print(X_train)
$ python3 split.py
(0, 125) 1
(0, 145) 1
(0, 201) 1
(0, 597) 1
(0, 600) 1
(0, 710) 1
(0, 801) 2
(0, 888) 1
(0, 973) 1
(0, 1042) 1
(0, 1308) 1
(0, 1345) 1
(0, 1360) 1
(0, 1494) 2
(0, 1524) 2
(0, 1587) 1
(0, 1622) 1
(0, 1634) 1
(1, 63) 1
(1, 136) 1
(1, 597) 1
(1, 616) 1
(1, 638) 1
(1, 725) 1
(1, 1001) 1
: :
(746, 1634) 1
(747, 42) 1
(747, 654) 1
(747, 1193) 2
(747, 1237) 1
(747, 1494) 1
(747, 1520) 1
(748, 600) 1
(748, 654) 1
(748, 954) 1
(748, 1001) 1
(748, 1494) 1
(749, 14) 1
(749, 15) 1
(749, 57) 1
(749, 108) 1
(749, 347) 1
(749, 553) 1
(749, 675) 1
(749, 758) 1
(749, 801) 1
(749, 1010) 1
(749, 1105) 1
(749, 1492) 1
(749, 1634) 2
#### LogisticRegression
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print("Accuracy:", score)
$ python3 split.py
Accuracy: 0.796
for source in df['source'].unique():
df_source = df[df['source'] == source]
sentences = df_source['sentence'].values
y = df_source['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print('Accuracy for {} data: {:.4f}'.format(source, score))
$ python3 split.py
Accuracy for yelp data: 0.7960
Accuracy for amazon data: 0.7960
Accuracy for imdb data: 0.7487
以前、バッチ処理で楽天の商品を紹介するtwitterボットのアカウントを2つ作成したのですが、ついに報酬が発生しました! 4,950円の商品が1つ売れたみたい。 不労所得で商品が売れる瞬間って面白いですね。
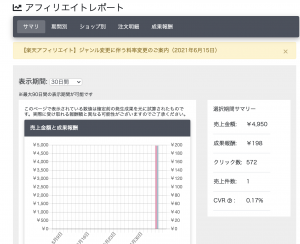
もっと自動化したいのう。
### Getting and preparing data
$ wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz
$ ls
cooking.stackexchange.id
$ head cooking.stackexchange.txt
__label__sauce __label__cheese How much does potato starch affect a cheese sauce recipe?
__label__food-safety __label__acidity Dangerous pathogens capable of growing in acidic environments
__label__cast-iron __label__stove How do I cover up the white spots on my cast iron stove?
“__label__” prefix is how fasttext recognize difference of word and label.
$ wc cooking.stackexchange.txt
15404 169582 1401900 cooking.stackexchange.txt
-> split example and validation
$ head -n 12404 cooking.stackexchange.txt > cooking.train
$ tail -n 3000 cooking.stackexchange.txt > cooking.valid
### train_supervised
training.py
import fasttext model = fasttext.train_supervised(input="cooking.train")
$ python3 training.py
Read 0M words
Number of words: 14543
Number of labels: 735
Floating point exception
何故だ〜〜〜〜〜〜〜〜〜〜
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
$ pip3 install cython
$ pip3 install fasttext
$ install requests requests_oauthlib
Twitterの開発者向けのページから、consumer key, consumer secret, access token, access token secretを取得します。
tweet_get.py
import re
import json
import MeCab
from requests_oauthlib import OAuth1Session
CK = ""
CS = ""
AT = ""
AS = ""
API_URL = "https://api.twitter.com/1.1/search/tweets.json?tweet_mode=extended"
KEYWORD = "芸能 OR アニメ OR 漫画 OR TV OR ゲーム"
CLASS_LABEL = "__label__1"
def main():
tweets = get_tweet()
surfaces = get_surfaces(tweets)
write_txt(surfaces)
def get_tweet():
params = {'q' : KEYWORD, 'count' : 20}
twitter = OAuth1Session(CK, CS, AT, AS)
req = twitter.get(API_URL, params = params)
results = []
if req.status_code == 200:
tweets = json.loads(req.text)
for tweet in tweets['statuses']:
results.append(tweet['full_text'])
return results
else:
print ("Error: %d" % req.status_code)
def get_surfaces(contents):
results = []
for row in contents:
content = format_text(row)
tagger = MeCab.Tagger('')
tagger.parse('')
surf = []
node = tagger.parseToNode(content)
while node:
surf.append(node.surface)
node = node.next
results.append(surf)
return results
def write_txt(contents):
try:
if(len(contents) > 0):
fileName = CLASS_LABEL + ".txt"
labelText = CLASS_LABEL + ","
f = open(fileName,'a')
for row in contents:
spaceTokens = "".join(row);
result = labelText + spaceTokens + "\n"
f.write(result)
f.close()
print(str(len(contents))+"行を書き込み")
except Exception as e:
print("テキストの書き込みに失敗")
print(e)
def format_text(text):
text=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text)
text=re.sub(r'@[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text)
text=re.sub(r'&[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text)
text=re.sub(';', "", text)
text=re.sub('RT', "", text)
text=re.sub('\n', " ", text)
return text
if __name__ == '__main__':
main()
1.エンタメ、2.美容、3.住まい/暮らし のキーワードで集めます。
__label__1: エンタメ
-> 芸能 OR アニメ OR 漫画 OR TV OR ゲーム
__label__2: 美容
-> 肌 OR ヨガ OR 骨盤 OR ウィッグ OR シェイプ
__label__3: 住まい/暮らし
-> リフォーム OR 住宅 OR 家事 OR 収納 OR 食材
label1〜3のテキストを結合させます
$ cat __label__1.txt __label__2.txt __label__3.txt > model.txt
$ ls
__label__1.txt __label__3.txt model.txt
__label__2.txt fastText tweet_get.py
learning.py
import sys import fasttext as ft argvs = sys.argv input_file = argvs[1] output_file = argvs[2] classifier = ft.supervised(input_file, output_file)
$ python3 learning.py model.txt model
raise Exception(“`supervised` is not supported any more. Please use `train_supervised`. For more information please refer to https://fasttext.cc/blog/2019/06/25/blog-post.html#2-you-were-using-the-unofficial-fasttext-module”)
Exception: `supervised` is not supported any more. Please use `train_supervised`.
model = ft.train_supervised(input_file)
$ python3 learning.py model.txt ftmodel
Read 0M words
Number of words: 6
Number of labels: 135
Floating point exception
おかしいな、number of labelsが135ではなく3のはずなんだけど。。。
### TfIdf
Tf = Term Frequency
Idf = Inverse Document Frequency
Tfはドキュメント内の単語の出現頻度、Idfは全ての文章内の単語の出現頻度の逆数
TfIdfを使うと、いろいろな文章に出てくる単語は無視して、ある文章に何回も出てくる単語は重要な語として扱う
def get_vector_by_text_list(_items): count_vect = TfidfVectorizer(analyzer=_split_to_words) # count_vect = CountVectorizer(analyzer=_split_to_words) box = count_vect.fit_transform(_items) X = box.todense() return [X,count_vect]
MLPClassifierとは、Multi-layer Perceptron classifierの略で多層パーセプトロンと呼ばれる分類器のモデル
$ pip3 install numpy
$ pip3 install scikit-learn
$ pip3 install pandas
scikit-learnはpythonで使用できる機械学習ライブラリ
ニュースコーパスは livedoorニュースコーパス を使用します。
livedoor ニュースコーパス
$ ls
text
$ cd text
$ ls
CHANGES.txt dokujo-tsushin livedoor-homme smax
README.txt it-life-hack movie-enter sports-watch
app.py kaden-channel peachy topic-news
app.py
import os, os.path
import csv
f = open('corpus.csv', 'w')
csv_writer = csv.writer(f, quotechar="'")
files = os.listdir('./')
datas = []
for filename in files:
if os.path.isfile(filename):
continue
category = filename
for file in os.listdir('./'+filename):
path = './'+filename+'/'+file
r = open(path, 'r')
line_a = r.readlines()
text = ''
for line in line_a[2:]:
text += line.strip()
r.close()
datas.append()
print(text)
csv_writer.writerows(datas)
f.close()
$python3 app.py
以下のようなCSVファイルが生成されます。
### NNの仕組み
– 全てのテキストを形態素に分解し、全ての単語を把握した後、全ての単語に対してテキストに出現するかと言うベクトルを作成する。
– その後、ニューラルネットワークに対し、このベクトルを入力とし、出力をカテゴリとして学習を行う
nlp_tasks.py
# -*- coding: utf-8 -*-
#! /usr/bin/python3
import MeCab
from sklearn.feature_extraction.text import CountVectorizer
def _split_to_words(text):
tagger = MeCab.Tagger('-O wakati')
try:
res = tagger.parse(text.strip())
except:
return[]
return res
def get_vector_by_text_list(_items):
count_vect = CountVectorizer(analyzer=_split_to_words)
box = count_vect.fit_transform(_items)
X = box.todense()
return [X,count_vect]
models というフォルダを作成する
main.py
# -*- coding: utf-8 -*-
#! /usr/bin/python3
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.externals import joblib
import os.path
import nlp_tasks
from sklearn.neural_network import MLPClassifier # アルゴリズムのmlp
def train():
classifier = MyMLPClassifier()
classifier.train('corpus.csv')
def predict():
classifier = MyMLPClassifier()
classifier.load_model()
result = classifier.predict(u"競馬の3歳馬日本一を決めるG1レース、「第88回日本ダービー」が行われ、4番人気のシャフリヤールが優勝しました。")
print(result)
class MyMLPClassifier():
model = None
model_name = "mlp"
def load_model(self):
if os.path.exists(self.get_model_path())==False:
raise Exception('no model file found!')
self.model = joblib.load(self.get_model_path())
self.classes = joblib.load(self.get_model_path('class')).tolist()
self.vectorizer = joblib.load(self.get_model_path('vect'))
self.le = joblib.load(self.get_model_path('le'))
def get_model_path(self, type='model'):
return 'models/'+self.model_name+"_"+type+".pkl"
def get_vector(self,text)
return self.vectorizer.transform()
def train(self, csvfile):
df = pd.read_csv(cavfile,names=('text','category'))
X, vectorizer = nlp_tasks.get_vector_by_text_list(df["text"])
le = LabelEncoder()
le.fit(df['category'])
Y = le.transform(df['category'])
model = MLPClassifier(max_iter=300, hidden_layer_sizes=(100,),verbose=10,)
model.fit(X, Y)
# save models
joblib.dump(model, self.get_model_path())
joblib.dump(le.classes_, self.get_model_path("class"))
joblib.dump(vectorizer, self.get_model_path("vect"))
joblib.dump(le, self.get_model_path("le"))
self.model = model
self.classes = le.classes_.tolist()
self.vectorizer = vectorizer
def predict(self, query):
X = self.vectorizer.transform([query])
key = self.model.predict(X)
return self.classes[key[0]]
if __name__ == '__main__':
train()
#predict()
$ ls
corpus.csv main.py models nlp_tasks.py text
$ python3 main.py
Iteration 1, loss = 4.24610757
Iteration 2, loss = 2.08110509
Iteration 3, loss = 1.70032200
Iteration 4, loss = 1.49572560
// 省略
Iteration 136, loss = 0.00257828
Training loss did not improve more than tol=0.000100 for 10 consecutive epochs. Stopping.
if __name__ == '__main__':
# train()
predict()
$ python3 main.py
sports-watch
まじかーーーーーーーーーーーーーーーーーー
Sugeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee