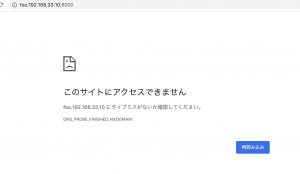
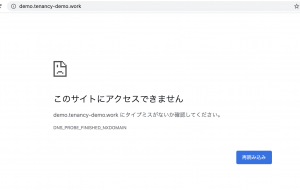
Laravelでのマルチテナントは、tenancy/tenancyを使用する。
tenancy/tenancyと、ベースの機能のみで必要な分は後から追加するtenancy/frameworkがある。
tenancy/framework推奨
$ composer require tenancy/framework
$ php artisan make:model Organization -m
create_organizations_table.php
public function up()
{
Schema::create('organizations', function (Blueprint $table) {
$table->id();
$table->string('name')->unique();
$table->timestamps();
});
}
$ php artisan migrate
Organization.php
use Illuminate\Http\Request;
use Tenancy\Identification\Contracts\Tenant;
class Organization extends Model implements Tenant
{
use HasFactory;
protected $fillable = [
'name',
'subdomain',
];
protected $dispatchesEvents = [
'created' => \Tenancy\Tenant\Events\Created::class,
'updated' => \Tenancy\Tenant\Events\Updated::class,
'deleted' => \Tenancy\Tenant\Events\Deleted::class,
];
public function getTenantKeyName(): string {
return 'name';
}
public function getTenantKey(){
return $this->name;
}
public function getTenantIdentifier(): string {
return get_class($this);
}
}
Tenancy\Identification\Concerns\AllowsTenantIdentification を使うだけでもできる
-テナントが追加されたら、テナント用のデータベースを作成してマイグレーション
-テナントが更新されたらマイグレーション実行
-テナントが削除されたらデータベース削除
-テナントを識別するため、Resolverに登録
app/Providers/AppServiceProvider
use Tenancy\Identification\Contracts\ResolvesTenants;
class AppServiceProvider extends ServiceProvider
{
public function register()
{
//
$this->app->resolving(ResolvesTenants::class, function(ResolvesTenants $resolver){
$resolver->addModel(Organization::class);
return resolver;
});
}
}
MySQLのデータベースドライバをインストール
$ composer require tenancy/db-driver-mysql
affects connections : テナントのDBにテナントのDBにアクセスできるようにする
$ composer require tenancy/affects-connections
tenancyの拡張パッケージは Event/Listner で構成
$ php artisan make:listener ResolveTenantConnection
/listeners/ResolveTenantConnection.php
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Queue\InteractsWithQueue;
use Tenancy\Identification\Contracts\Tenant;
use Tenancy\Affects\Connections\Contracts\ProvidesConfiguration;
class ResolveTenantConnection
{
public function handle(Resolving $event)
{
//
return $this;
}
public function configure(Tenant $tenant): array {
$config = [];
event(new Configuring($tenant, $config, $this));
return $config;
}
}
/app/Providers/EventServiceProvider.php
use Illuminate\Auth\Events\Registered;
use Illuminate\Auth\Listeners\SendEmailVerificationNotification;
use Illuminate\Foundation\Support\Providers\EventServiceProvider as ServiceProvider;
use Illuminate\Support\Facades\Event;
class EventServiceProvider extends ServiceProvider
{
protected $listen = [
\Tenancy\Affects\Connections\Events\Resolving::class => [
App\Listeners\ResolveTenantConnection\ResolveTenantConnection::class,
],
Registered::class => [
SendEmailVerificationNotification::class,
],
];
}
$ composer require tenancy/hooks-migration
$ php artisan make:listener ConfigureTenantMigrations
use Tenancy\Hooks\Migration\Events\ConfigureMigrations;
use Tenancy\Tenant\Events\Deleted;
class ConfigureTenantMigrations
{
public function handle(ConfigureMigrations $event)
{
//
if($event->event->tenant){
if($event->event instanceof Deleted){
$event->disable();
} else {
$event->path(database_path('tenant/migrations'));
}
}
}
}
EventServiceProvider.php
use Illuminate\Support\Facades\Event;
use App\Listeners\ConfigureTenantMigrations;
class AppServiceProvider extends ServiceProvider
{
/**
* Register any application services.
*
* @return void
*/
public function register()
{
//
$this->app->resolving(ResolvesTenants::class, function(ResolvesTenants $resolver){
$resolver->addModel(Organization::class);
return resolver;
});
}
protected $listen = [
\Tenancy\Hooks\Migration\Events\ConfigureMigrations::class => [
ConfigureTenantMigrations::class,
],
];
}
$ php artisan make:listener ConfigureTenantSeeds
use Database\Tenant\Seeders\DatabaseSeeder;
use Tenancy\Hooks\Migration\Events\ConfigureSeeds;
use Tenancy\Tenant\Events\Deleted;
use Tenancy\Tenant\Events\Updated;
class ConfigureTenantSeeds
{
public function handle(ConfigureSeeds $event)
{
//
if($event->event->tenant){
if($event->event instanceof Deleted || $event->event instanceof Updated){
$event->disable();
} else {
$event->seed(DatabaseSeeder::class);
}
}
}
}
EventServiceProvider.php
protected $listen = [
\Tenancy\Affects\Connections\Events\Resolving::class => [
App\Listeners\ResolveTenantConnection\ResolveTenantConnection::class,
],
\Tenancy\Hooks\Migration\Events\ConfigureMigrations::class => [
ConfigureTenantMigrations::class,
],
\Tenancy\Hooks\Migration\Events\ConfigureSeeds::class => [
ConfigureTenantSeed::class
],
Registered::class => [
SendEmailVerificationNotification::class,
],
];
.env.testing
TENANT_SLUG=test
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=test_central
DB_USERNAME=root
DB_PASSWORD=password
あれ? これでどうやって実装するのかようわからんな。。