$ mkdir go
$ cd go
$ go mod init chat
$ mkdir -p cmd/web
$ mkdir -p internal/handlers
$ mkdir html
$ touch cmd/web/main.go
$ touch cmd/web/routes.go
$ touch html/home.jet
$ touch internal/handlers/handlers.go
$ mkdir domain
$ touch domain/connect.go
$ mkdir static
$ touch static/scripts.js
$ touch static/style.css
### モジュールの追加
$ go get github.com/CloudyKit/jet/v6
$ go get github.com/bmizerany/pat
$ go get github.com/gorilla/websocket
### handler, route.go, main.go省略
internal/handlers/hanlders.go
cmd/web/main.go
cmd/web/routes.go
### template
home/home.jet
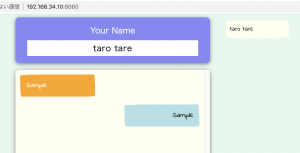
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="/static/style.css">
</head>
<body>
<div class="chat-container">
<div class="chat-header">
<label for="username">Your Name</label>
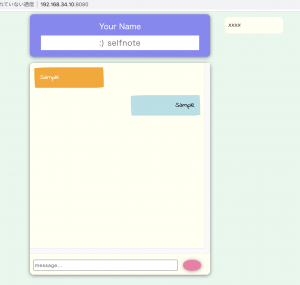
<input type="text" id="username" class="username" autocomplete="off" placeholder=":) selfnote">
</div>
<div class="chat-body">
<ul id="message-list">
<li class="me">Sample</li>
<li class="other">Sample</li>
</ul>
<div class="send-area">
<input type="text" id="message" class="message" autocomplete="off" placeholder="message...">
<button id="submit" class="submit">
<i class="far far-paper-plane"></i>
</button>
</div>
</div>
</div>
<div class="oneline-user-container">
<ul id="online-users">
<li>XXXX</li>
</ul>
</div>
<script src="/static/scripts.js"></script>
</body>
</html>
### Websocketのエンドポイント作成
/domain/connect.go
L websocket返却用の構造体
package domain
type WsJsonResponse struct {
Action string `json:"action"`
Message string `json:"message"`
}
internal/handlers/hanlders.go
import (
"chat/domain"
"log"
"net/http"
"github.com/CloudyKit/jet/v6"
"github.com/gorilla/websocket"
)
var upgradeConnection = websocket.Upgrader {
ReadBufferSize: 1024,
WriteBufferSize: 1024,
CheckOrigin: func(r *http.Request) bool {return true},
}
func WsEndpoint(w http.ResponseWriter, r *http.Request){
ws, err := upgradeConnection.Upgrade(w, r, nil)
if err != nil {
log.Println(err)
}
log.Println("OK client connecting")
var response domain.WsJsonResponse
response.Message = `<li>Connect to server</li>`
err = ws.WriteJSON(response)
if err != nil {
log.Println(err)
}
}
Route.go
func routes() http.Handler {
mux := pat.New()
mux.Get("/", http.HandlerFunc(handlers.Home))
mux.Get("/ws", http.HandlerFunc(handlers.WsEndpoint)) // 追加
fileServer := http.FileServer(http.Dir("./static/"))
mux.Get("/static/", http.StripPrefix("/static", fileServer))
return mux
}
js
let socket = null;
document.addEventListener("DOMContentLoaded", function(){
socket = new WebSocket("ws://192.168.34.10:8080/ws")
socket.onopen = () => {
console.log("successfully connected")
}
})
console
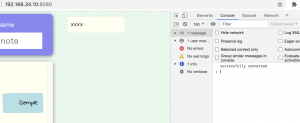
js
document.addEventListener("DOMContentLoaded", function(){
socket = new WebSocket("ws://192.168.34.10:8080/ws")
socket.onopen = () => {
console.log("successfully connected")
}
socket.onclose = () => {
console.log("connection closed")
}
socket.onerror = error => {
console.log("there was an error")
}
socket.onmessage = msg => {
let j = JSON.parse(msg.data)
console.log(j)
}
})
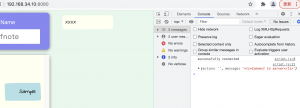
うーむ、postされたらonloadというイメージなんだが…