
pip install -q google-generativeai
import google.generativeai as genai # Googleの生成AIライブラリ
from google.colab import userdata # Google Colabのユーザーデータモジュール
GOOGLE_API_KEY=userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
print("使用可能なGeminiのモデル一覧:")
for model in genai.list_models():
if "generateContent" in model.supported_generation_methods:
print(model.name)
model = genai.GenerativeModel("models/gemini-2.0-flash-001")
print(f"選択されたモデル: {model.model_name}")
config = genai.GenerationConfig(
max_output_tokens=2048, # 生成されるトークンの最大数
temperature=0.8, # 出力のランダム性を制御
)
def generate_content(model, prompt):
response = model.generate_content(prompt, generation_config=config)
return response.text
user_input = input("質問を入力してください: ")
response = generate_content(model, user_input)
print(f"Gemini: {response}")
LLMの内部構造: LLaMA-2
LLaMA-2の主要構造
1. Pythonコード (約1000行) : llama
2. パラメータ : llama-2-7b 次の単語予想に使用
3. トークナイザ : 前処理でテキストを分割
step1: トークナイザで入力テキストを細かく分割する
step2: Transformerとパラメータを用いて次の単語を予測
step3: 予測結果を元に次の単語を選択し結合
※予測結果から単語を選ぶプロセスをサンプリングと呼ぶ
model.py
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
"""
Initialize a Transformer model.
Args:
params (ModelArgs): Model configuration parameters.
Attributes:
params (ModelArgs): Model configuration parameters.
vocab_size (int): Vocabulary size.
n_layers (int): Number of layers in the model.
tok_embeddings (ParallelEmbedding): Token embeddings.
layers (torch.nn.ModuleList): List of Transformer blocks.
norm (RMSNorm): Layer normalization for the model output.
output (ColumnParallelLinear): Linear layer for final output.
freqs_cis (torch.Tensor): Precomputed cosine and sine frequencies.
"""
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
# Note that self.params.max_seq_len is multiplied by 2 because the token limit for the Llama 2 generation of models is 4096.
# Adding this multiplier instead of using 4096 directly allows for dynamism of token lengths while training or fine-tuning.
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
"""
Perform a forward pass through the Transformer model.
Args:
tokens (torch.Tensor): Input token indices.
start_pos (int): Starting position for attention caching.
Returns:
torch.Tensor: Output logits after applying the Transformer model.
"""
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full(
(seqlen, seqlen), float("-inf"), device=tokens.device
)
mask = torch.triu(mask, diagonal=1)
# When performing key-value caching, we compute the attention scores
# only for the new sequence. Thus, the matrix of scores is of size
# (seqlen, cache_len + seqlen), and the only masked entries are (i, j) for
# j > cache_len + i, since row i corresponds to token cache_len + i.
mask = torch.hstack([
torch.zeros((seqlen, start_pos), device=tokens.device),
mask
]).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output
いくつかの処理では、パラメータと呼ばれる数値を使用して演算が行われる
パラメータを繰り返し調整し、予想の精度を高める
※予想が誤っていた場合、パラメータを修正する (バックプロパゲーションと呼ばれる)
※LLMのパラメータ: 「Apple」という単語は、その単語が持つ意味、文脈、関連する概念(例えば、食べ物、会社名、色など)が、膨大な数値の集合(ベクトル)として表現されます。これらの数値の組み合わせによって、単語間の関係性が学習されています。
※単語のIDやトークンに対して数値ベクトルが割り当てられる
※モデルの大部分を占めるのは、単語間の関係性を理解し、次の単語を予測するための複雑な計算を行う、**アテンション機構やフィードフォワードネットワーク内の重み(weights)やバイアス(biases)**です。これらのパラメータが、文脈に応じた適切な単語の埋め込みベクトルを組み合わせ、最終的な出力を生成する。
### LLMの学習ステップ
学習ステップ1. 事前学習(Pre-training): 基盤モデル ただし、対話形式の学習が不足、不適切な質問にも答えてしまう
学習ステップ2. ファインチューニング(Fine-tuning): 特定のタスクや分野に特化させることができる
学習ステップ3. ヒューマンフィードバック(Human Feedback): 人間からのフィードバックを得る
### 事前学習に使われるデータ
モデルの用途によって、収集するデータ元(Webサイト、書籍、会話テキスト)の比率などが変わってくる。例えば、チャット用途の場合は、比較的会話データが多く学習される傾向にある。
### Transformer
Transformerの構造は主にEncoder(テキスト理解)とDecoder(テキスト生成)の要素から成り立つ
Attention機構の役割: 文中から関連度の高い単語を発見する
モーションAI
元画像

text
“This note is a personal reflection of a freelance engineer’s experience.”
動画生成
### モーションAIサービス
音声解析+AIモーション生成
音声データから「発話のリズム・イントネーション」を自動解析
AIモデルが「口の開閉」「表情の変化」「頭や体の動き」を推定して生成
=> JSONやスクリプトの形で、「フレームごとに口パク・まばたき・首の動き」を指示するタイムラインを自動生成
=> 既存のアニメーションライブラリ(例えば Live2D、Unity、After Effects、Blender など)に食わせるデータを準備
Canvaで画像合成
Chat GPTと同じように、Canvaでも画像合成ができる。
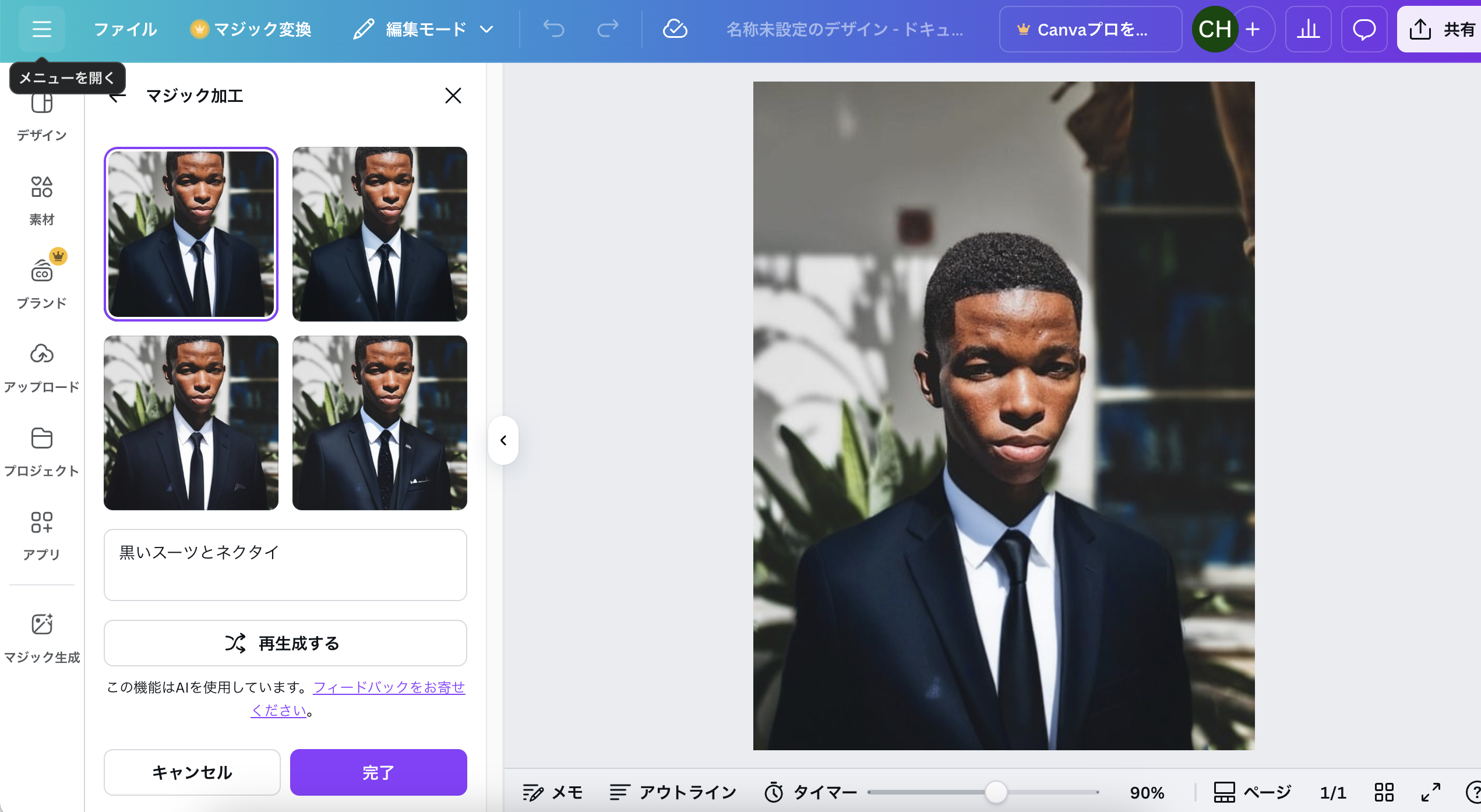
背景を変えることもできる。
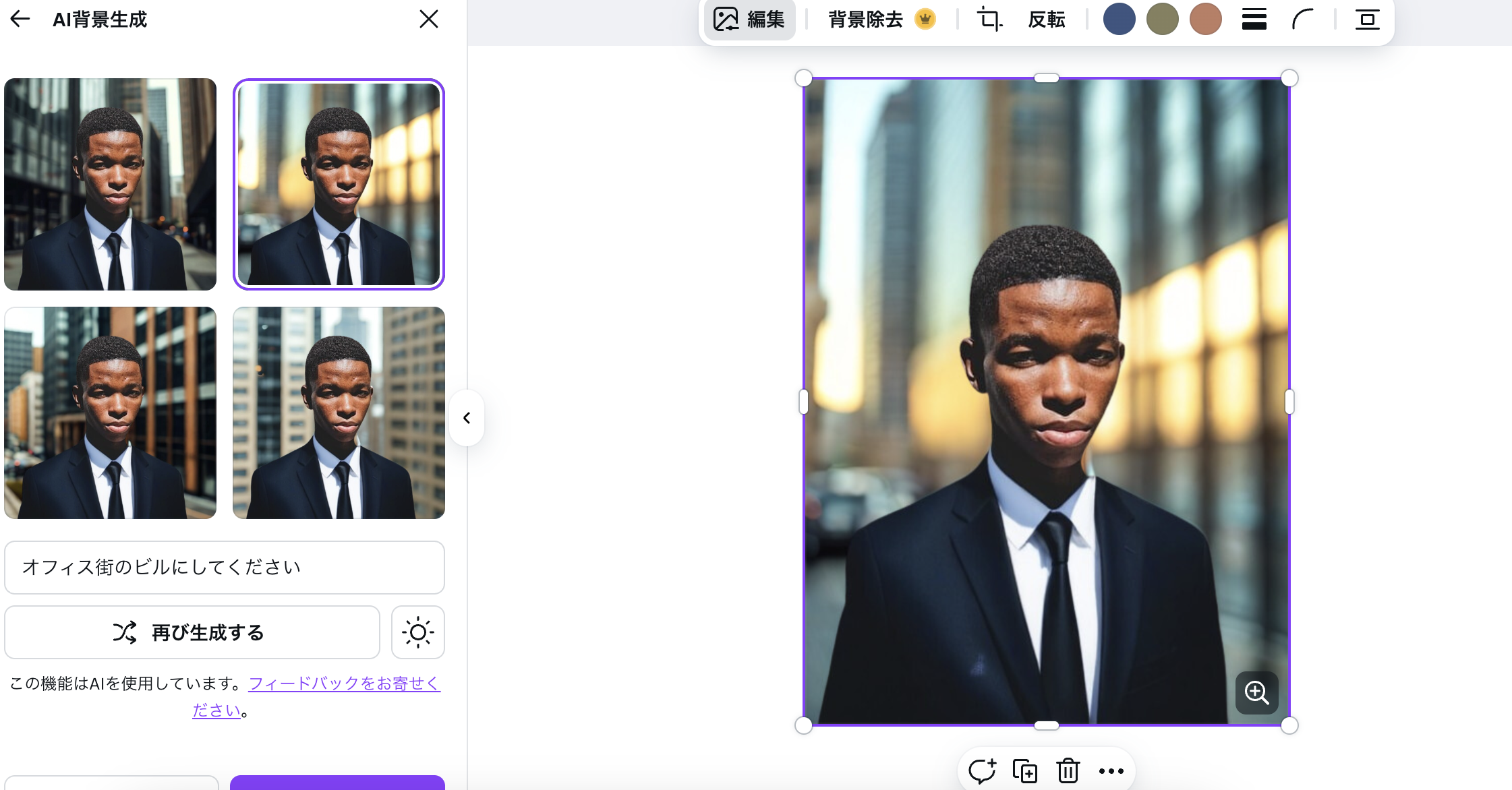
🔍 Canvaマジック編集の仕組みイメージ
ユーザーがマスクを指定(首から下など)
テキスト指示(例: “a black suit and tie”)を入力
Canvaのサーバー側で拡散モデルに送信
画像の「残す部分(顔)」を保持
マスク部分を inpainting(塗り直し)
出力候補を複数生成し、ユーザーに提示
つまり内部的には、Stable Diffusion の inpainting とほぼ同じ流れ
Canvaの服差し替えも「Diffusion Model の inpainting」と考えて良い。
なんだこれは、凄すぎる。。。
### 動画の合成技術
1. 共通点(画像と同じ部分)
生成モデルを使う
画像生成で使うDALL·EやStable Diffusionのように、動画合成もニューラルネットワーク(特に生成モデル)を使います。
条件付き生成が可能
画像: 「黒いスーツを着た人」というプロンプト
動画: 「黒いスーツを着た人が歩く」というプロンプト
→ プロンプトに応じてフレームごとに生成する点は共通
データ表現はピクセルや特徴量
動画も結局は連続した画像(フレーム)なので、フレーム単位での画像合成技術が応用されます。
2. 動画ならではの追加課題
時間方向の一貫性
画像は単独で完結しますが、動画はフレーム間で連続性が必要
例: 人の手が前のフレームから急に消えると不自然
→ 「時間方向のモデル(Temporal model)」や「フロー情報」を使う
フレーム数が多い
1秒で30フレームなら30枚の画像を生成する必要がある
単純にフレームごとに画像生成すると重くなる
→ 先読みや特徴量伝播で効率化
マスクや編集の複雑さ
動画編集では「同じ位置のオブジェクトを全フレームでマスク」する必要がある
画像編集よりマスク処理が大規模かつ複雑
3. 技術例
画像拡張型
Stable Diffusion をフレームごとに生成+フレーム間のブレ補正
ビデオ特化型生成モデル
Imagen Video(Google)
Runway Gen-2
動画の時間方向情報も含めて生成する
既存動画の変換や編集
Deepfake や映像スタイル変換(例: 動画に別の服装や表情を合成)
元動画を入力として、時間方向に一貫した編集を行う
なるほど、なかなか勉強になるというか、面白いですね。
AIによる写真の合成技術
### 元画像

### ChatGTP-5
1. 範囲指定: 写真の首から下をマスク
2. 希望する服の種類を指示: スーツ+ネクタイ
アウトプット

その他の方法
## 方法1: 画像編集ソフトを使う
Photoshop / GIMP などを使用
– 首から下を「選択ツール」で切り抜き。
– 新しい服の画像を別レイヤーとして用意。
– サイズ・角度を合わせて合成。
– 境界を「ぼかし」や「マスク」で自然になじませる。
これは一番手動ですが、精密に調整できる。
## 方法2: AI画像編集ツールを使う
– Adobe Photoshop(生成塗りつぶし)
– Canva の「AI背景リムーバー+衣装差し替え」
– Fotor, Pixlr, Photopea などの無料ツール
– Stable Diffusion / ComfyUI で「inpainting」機能を使い、服を指定して描き直す
やり方は共通で:
1. 写真をアップロード
2. 首から下を選択(マスク指定)
3. 「服を変える」「スーツにする」など指示
4. AIが服を生成して合成
## 方法3: コーデ専用AIサービス
Fashn.AI や TryOnAI などは、服のバーチャル試着が可能。
自分の写真をアップすると、選んだ服を着せてくれる仕組み。
# AIによる画像合成の仕組み
1. 画像生成モデル(例:拡散モデル)
現在主流なのは 拡散モデル(Diffusion Model, Stable Diffusion など) です。
仕組みをざっくりいうと:
■ノイズ付加
もとの学習画像に少しずつランダムなノイズを加えていき、最終的に「ただのノイズ画像」にします。
■ノイズ除去の学習
「ノイズ画像から元画像を推定する」タスクを繰り返し学習します。
■生成
実際に画像を作るときは、ランダムなノイズ画像から始めて、学習した「ノイズ除去器(U-Netなど)」で少しずつノイズを取り除き、条件(テキスト指示やマスク部分の画像など)に沿った新しい画像に仕上げます。
2. 条件付き生成(テキストやマスクの利用)
■テキスト条件
「黒いスーツ」「ネクタイ」などの文章を CLIP などのテキスト埋め込みモデルで数値化し、それをガイドとして生成します。
■マスク条件(inpainting)
画像の特定範囲(例:首から下)にマスクをかけて「ここだけ生成し直す」と指定します。
すると AI は残りの画像を手掛かりに、マスク部分を自然に埋めてくれます。
3. 合成時の工夫
境界処理:マスクの縁をぼかして違和感を減らす
コンテキスト利用:背景や光の方向を読み取り、生成結果を自然に馴染ませる
ランダム性制御:シード値を固定すれば毎回同じ結果を再現できる
## ブラウザ上で操作できるサービス
✅ Canva
Webブラウザで利用可能(無料プランあり)
「AI背景リムーバー」や「マジック編集(服の差し替え)」が使える
👉 https://www.canva.com/
✅ Fotor
ブラウザ版あり(無料プラン+有料プラン)
AIによる背景削除、合成、衣装差し替えが可能
👉 https://www.fotor.com/
✅ Pixlr
完全にブラウザで動作(広告付き無料プランあり)
Photoshop風の操作感で、レイヤー編集・マスクも可能
👉 https://pixlr.com/
✅ Photopea
完全無料でブラウザ上で動作
Photoshop互換の操作感
手動マスク+他画像合成は可能(AI自動生成は弱め)
👉 https://www.photopea.com/
拡散モデル(diffusion)
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# ==== MNIST データセットから1枚取得 ====
transform = transforms.Compose([
transforms.ToTensor(),
])
dataset = torchvision.datasets.MNIST(root="./data", train=True, download=True, transform=transform)
image, _ = dataset[0] # 1枚だけ
image = image.squeeze(0) # (1,28,28) → (28,28)
# ==== 拡散プロセス ====
T = 10 # ステップ数
noisy_images = []
x = image.clone()
for t in range(T):
noise = torch.randn_like(x) * 0.1
x = (x + noise).clamp(0,1) # ノイズを足す
noisy_images.append(x)
# ===== 擬似的な逆拡散(平均を取ってノイズを少しずつ減らすだけ) =====
denoised_images = []
y = noisy_images[-1].clone()
for t in range(T):
y = (y*0.9 + image*0.1) # 単純な補間で元画像に近づける
denoised_images.append(y)
# ===== 可視化 =====
fig, axes = plt.subplots(3, T, figsize=(15, 5))
# 元画像
axes[0,0].imshow(image, cmap="gray")
axes[0,0].set_title("Original")
axes[0,0].axis("off")
# 拡散 (ノイズ付与)
for i in range(T):
axes[1,i].imshow(noisy_images[i], cmap="gray")
axes[1,i].axis("off")
axes[1,0].set_title("Forward Diffusion")
# 逆拡散 (ノイズ除去の雰囲気だけ)
for i in range(T):
axes[2,i].imshow(denoised_images[i], cmap="gray")
axes[2,i].axis("off")
axes[2,0].set_title("Reverse (Toy)")
plt.show()
DCGAN
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# ==== Generator ====
class Generator(nn.Module):
def __init__(self, nz=100, ngf=64, nc=1): # nz: 潜在変数次元, nc: チャネル数
super().__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(nz, ngf*4, 7, 1, 0, bias=False),
nn.BatchNorm2d(ngf*4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf*4, ngf*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf*2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf*2, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, x):
return self.main(x)
# ==== Discriminator ====
class Discriminator(nn.Module):
def __init__(self, nc=1, ndf=64):
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf, ndf*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(ndf*2, 1, 7, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.main(x).view(-1, 1)
# ==== データセットの準備 ====
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = torchvision.datasets.MNIST(root="./data", train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True)
# ==== モデルの初期化 ====
device = "cuda" if torch.cuda.is_available() else "cpu"
netG = Generator().to(device)
netD = Discriminator().to(device)
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999))
# ==== 学習の実行 ====
nz = 100
nz = 100
for epoch in range(1): # デモなので1エポックだけ
for i, (real, _) in enumerate(dataloader):
real = real.to(device)
b_size = real.size(0)
label_real = torch.ones(b_size, 1, device=device)
label_fake = torch.zeros(b_size, 1, device=device)
# --- Discriminator 学習 ---
netD.zero_grad()
output_real = netD(real)
lossD_real = criterion(output_real, label_real)
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake = netG(noise)
output_fake = netD(fake.detach())
lossD_fake = criterion(output_fake, label_fake)
lossD = lossD_real + lossD_fake
lossD.backward()
optimizerD.step()
# --- Generator 学習 ---
netG.zero_grad()
output = netD(fake)
lossG = criterion(output, label_real)
lossG.backward()
optimizerG.step()
if i % 200 == 0:
print(f"Epoch[{epoch}] Step[{i}] Loss_D: {lossD.item():.4f} Loss_G: {lossG.item():.4f}")
# ==== 生成画像の表示 ====
noise = torch.randn(64, nz, 1, 1, device=device)
fake = netG(noise).detach().cpu()
grid = torchvision.utils.make_grid(fake, padding=2, normalize=True)
plt.imshow(grid.permute(1, 2, 0))
plt.show()
$ python3 dcgan.py
Epoch[0] Step[0] Loss_D: 1.2740 Loss_G: 0.8563
Epoch[0] Step[200] Loss_D: 0.9803 Loss_G: 1.6264
Epoch[0] Step[400] Loss_D: 0.6745 Loss_G: 1.1438
Epoch[0] Step[600] Loss_D: 0.5692 Loss_G: 1.5479
Epoch[0] Step[800] Loss_D: 0.5681 Loss_G: 1.5251
生成AIで音声と顔の表情などが同期する動画を作りたい
### 全体の流れ
テキスト作成(セリフや説明文)
音声生成(VOICEROID / YMM / CeVIO など)
立ち絵やキャラクター素材の配置
動画編集で背景・効果音・字幕を追加
書き出してYouTube等にアップロード
### 立ち絵と音声を準備
ずんだもんの立ち絵画像(psd)をダウンロードします。
### VOICEVOXによる音声作成
VOICEVOXをダウンロード、インストール
VOICEVOXキャラクターを選んで、テキストからキャラクターボイスに変換して、.wavファイルでエクスポートします。
以下がエクスポートしたwavファイルの例です。
センテンスごとにエクスポートすることも可能です。
### HeyGenでの動画作成
– HeyGenの場合、Avatar画像(png)と音声データ(もしくはテキストデータ+HeyGenの音声)を用意すれば、完全に音声と映像が同期した動画が作成できてしまいます。ただし、freeプランだと15秒以内という制限があるので、長い動画を作るには有料プランにupgradeする必要があります。
ユーザーインターフェイスもわかりやすく、非常に簡単な操作で動画が生成できます。
### ゆっくりMovieMaker4(YMM4)
ゆっくり系の動画を生成できるソフトです。元となるキャラクター画像(立ち絵)に動きやセリフをつけながら編集することができます。YMM4内で音声をつけられるので、VOICEVOXで音声データを作る必要はありません。
YMM4はwindowsにしかインストールできず、macには対応していないので注意が必要です。
HeyGenの場合は、口、顔の表情や体の揺れなどの動作が完全に自動で生成されますが、
YMM4の場合は、音声に合わせた立ち絵の動作はユーザが指定する仕組みとなっており、アルゴリズムが違うような印象です。
capcutというブラウザで動画を編集できるソフトもあるが、こちらはどちらかというと音声に合わせてキャラクターの表情や口元が変化するような機能はない。
### HeyGenとYMM4の違い
🔹 HeyGen の仕組み(AI駆動型)
音声解析+AIモーション生成
音声データから「発話のリズム・イントネーション」を自動解析
AIモデルが「口の開閉」「表情の変化」「頭や体の動き」を推定して生成
ユーザー操作不要
立ち絵をアップするだけで、「人が喋っているような自然な動作」が自動でつく
イメージ的には「モーションキャプチャの自動生成」
🔹 YMM4 の仕組み(プリセット切替型)
ユーザーが動きを指定
「口パクON/OFF」「笑顔に差し替え」「まばたき」などを手動で配置
音声に合わせてタイムラインで「差分画像」を切り替える仕組み
つまり、HeyGenの場合は 音声データから、「口の開閉」「表情の変化」「頭や体の動き」を推定して生成している!
なるほど、つまり
=> JSONやスクリプトの形で、「フレームごとに口パク・まばたき・首の動き」を指示するタイムラインを自動生成
=> 既存のアニメーションライブラリ(例えば Live2D、Unity、After Effects、Blender など)に食わせるデータを準備
をすれば、HeyGenに近いことができるようになる。なるほど〜、仕組み的に面白いですね。
LSTM(Long Short-Term Memory)
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# ===== データ生成 =====
x = np.linspace(0, 100, 1000)
y = np.sin(x)
# 学習用に系列データを作成
seq_length = 20
X, Y = [], []
for i in range(len(y) - seq_length):
X.append(y[i:i + seq_length])
Y.append(y[i + seq_length])
X = np.array(X)
Y = np.array(Y)
X_train = torch.tensor(X, dtype=torch.float32).unsqueeze(-1) # (batch_size, seq_length, input_size)
Y_train = torch.tensor(Y, dtype=torch.float32).unsqueeze(-1) # (batch_size, output_size)
# ===== LSTMモデル定義 =====
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=50, output_size=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = out[:, -1, :] # 最後のタイムステップの出力を取得
out = self.fc(out) # 最後のタイムステップの出力を使用
return out
model = LSTMModel()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# ===== 学習 =====
epochs = 10
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, Y_train)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}], Loss: {loss.item():.4f}')
# ===== 予測 =====
model.eval()
with torch.no_grad():
preds = model(X_train).numpy()
# ===== 結果のプロット =====
plt.plot(Y, label='True')
plt.plot(preds, label='Predicted')
plt.legend()
plt.show()
$ python3 lstm.py
Epoch [1], Loss: 0.4882
Epoch [2], Loss: 0.4804
Epoch [3], Loss: 0.4726
Epoch [4], Loss: 0.4648
Epoch [5], Loss: 0.4570
Epoch [6], Loss: 0.4492
Epoch [7], Loss: 0.4414
Epoch [8], Loss: 0.4335
Epoch [9], Loss: 0.4254
Epoch [10], Loss: 0.4172
変分オートエンコーダ(VAE)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor(),
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
# ==== VAE model ====
class VAE(nn.Module):
def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
self.fc2 = nn.Linear(latent_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
h = torch.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = torch.relu(self.fc2(z))
return torch.sigmoid(self.fc3(h))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# ===== model training =====
model = VAE()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def loss_function(recon_x, x, mu, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
# ===== training loop =====
epochs = 5
for epoch in range(epochs):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.view(-1, 784) # Flatten the input
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f'Epoch {epoch + 1}, Loss: {train_loss / len(train_loader.dataset):.4f}')
# ===== new sample creating =====
model.eval()
with torch.no_grad():
z = torch.randn(16, 20) # Generate random latent vectors
samples = model.decode(z).view(-1, 1, 28, 28) # Decode to images
$ python3 vae.py
Epoch 1, Loss: 164.1793
Epoch 2, Loss: 121.6226
Epoch 3, Loss: 114.7562
Epoch 4, Loss: 111.7122
Epoch 5, Loss: 109.9405
Loss がエポックごとに下がっている → 学習が進んでいる証拠
VAE の Loss は「再構築誤差 (BCE) + KLダイバージェンス」なので、単純な分類モデルの Accuracy とは違って「小さくなるほど良い」という見方