
Convents have revolutionized image classification and computer vision to extract features from images.
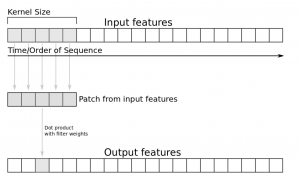
Keras use Conv1D layer
model = Sequential() model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen)) model.add(layers.Conv1D(128, 5, activation='relu')) model.add(layers.GlobalMaxPooling1D()) model.add(layers.Dense(10, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) print(model.summary())
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 100) 100
_________________________________________________________________
conv1d (Conv1D) (None, 96, 128) 64128
_________________________________________________________________
global_max_pooling1d (Global (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 10) 1290
_________________________________________________________________
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 65,529
Trainable params: 65,529
Non-trainable params: 0
_________________________________________________________________