関数の絶対値、ということは、二次関数、三次関数などの絶対値ってことだな。
import numpy as np
import matplotlib.pyplot as plt
pi = 2 * np.pi
x = np.arange(0, 2*pi, 0.1)
y1 = np.sin(x)
y2 = np.abs(np.sin(x))
fig = plt.figure()
ax = fig.add_subplot(111)
ax.grid()
ax.set_xlabel("x", fontsize=16)
ax.set_ylabel("y", fontsize=16)
ax.set_xlim(0, 2*pi)
ax.set_ylim(-1.5, 1.5)
ax.set_xticks([0, pi/2, pi, 3*pi/2, 2*pi])
ax.set_xticklabels(["0", "$\pi/2$", "$\pi$", "$3\pi/2$", "$2\pi$"],
fontsize = 12)
ax.plot(x, y1, linestyle = "--", color = "blue", label = "y = sinx")
ax.plot(x, y2, color = "red", label = "y = |sinx|")
ax.legend()
plt.savefig("01", bbox_inches = "tight")
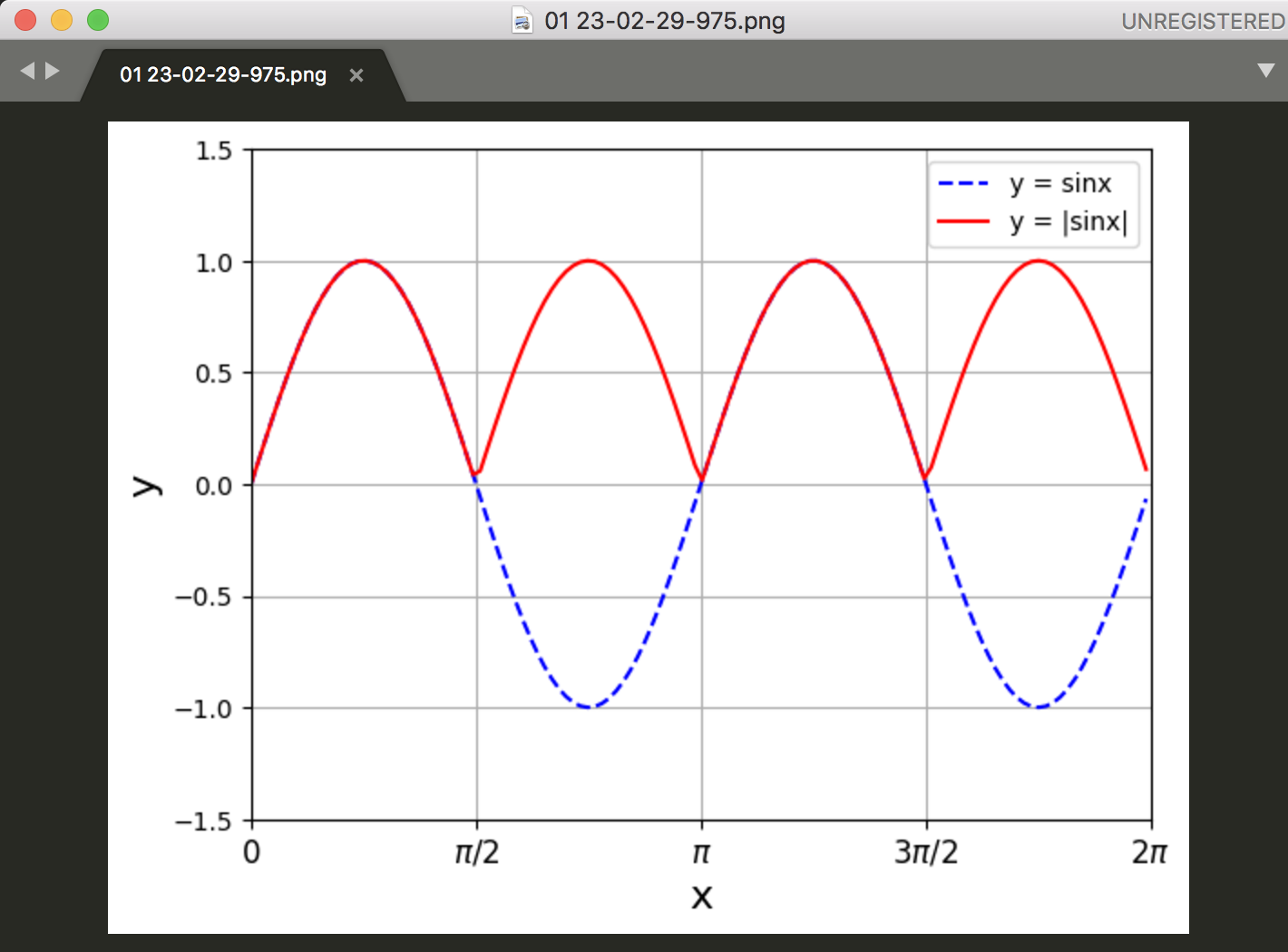
まじかー、これ。うーん、なんだかな。。