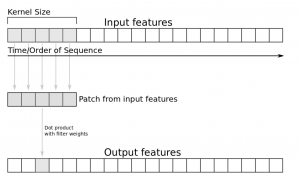
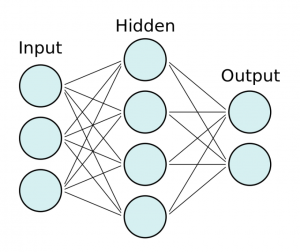
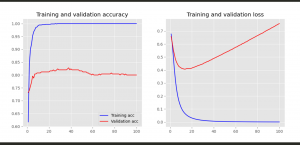
#### choosing a Data Set
Sentiment Labelled Sentences Data Set
https://archive.ics.uci.edu/ml/machine-learning-databases/00331/
※Yelpはビジネスレビューサイト(食べログのようなもの)
※imdbは映画、テレビなどのレビューサイト
こちらから、英文のポジティブ、ネガティブのデータセットを取得します。
$ ls
amazon_cells_labelled.txt imdb_labelled.txt readme.txt yelp_labelled.txt
import pandas as pd
filepath_dict = {
'yelp': 'data/yelp_labelled.txt',
'amazon': 'data/amazon_cells_labelled.txt',
'imdb': 'data/imdb_labelled.txt'
}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source
df_list.append(df)
df = pd.concat(df_list)
print(df.iloc[0])
$ python3 app.py
sentence Wow… Loved this place.
label 1
source yelp
Name: 0, dtype: object
This data, predict sentiment of sentence.
vocabularyごとにベクトル化して重みを学習して判定する
>>> sentences = [‘John likes ice cream’, ‘John hates chocolate.’]
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> vectorizer = CountVectorizer(min_df=0, lowercase=False)
>>> vectorizer.fit(sentences)
CountVectorizer(lowercase=False, min_df=0)
>>> vectorizer.vocabulary_
{‘John’: 0, ‘likes’: 5, ‘ice’: 4, ‘cream’: 2, ‘hates’: 3, ‘chocolate’: 1}
>>> vectorizer.transform(sentences).toarray()
array([[1, 0, 1, 0, 1, 1],
[1, 1, 0, 1, 0, 0]])
### Defining Baseline Model
First, split the data into a training and testing set
from sklearn.model_selection import train_test_split
import pandas as pd
filepath_dict = {
'yelp': 'data/yelp_labelled.txt',
'amazon': 'data/amazon_cells_labelled.txt',
'imdb': 'data/imdb_labelled.txt'
}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source
df_list.append(df)
df = pd.concat(df_list)
df_yelp = df[df['source'] == 'yelp']
sentences = df_yelp['sentence'].values
y = df_yelp['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
.value return NumPy array
from sklearn.feature_extraction.text import CountVectorizer
// 省略
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)
print(X_train)
$ python3 split.py
(0, 125) 1
(0, 145) 1
(0, 201) 1
(0, 597) 1
(0, 600) 1
(0, 710) 1
(0, 801) 2
(0, 888) 1
(0, 973) 1
(0, 1042) 1
(0, 1308) 1
(0, 1345) 1
(0, 1360) 1
(0, 1494) 2
(0, 1524) 2
(0, 1587) 1
(0, 1622) 1
(0, 1634) 1
(1, 63) 1
(1, 136) 1
(1, 597) 1
(1, 616) 1
(1, 638) 1
(1, 725) 1
(1, 1001) 1
: :
(746, 1634) 1
(747, 42) 1
(747, 654) 1
(747, 1193) 2
(747, 1237) 1
(747, 1494) 1
(747, 1520) 1
(748, 600) 1
(748, 654) 1
(748, 954) 1
(748, 1001) 1
(748, 1494) 1
(749, 14) 1
(749, 15) 1
(749, 57) 1
(749, 108) 1
(749, 347) 1
(749, 553) 1
(749, 675) 1
(749, 758) 1
(749, 801) 1
(749, 1010) 1
(749, 1105) 1
(749, 1492) 1
(749, 1634) 2
#### LogisticRegression
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print("Accuracy:", score)
$ python3 split.py
Accuracy: 0.796
for source in df['source'].unique():
df_source = df[df['source'] == source]
sentences = df_source['sentence'].values
y = df_source['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print('Accuracy for {} data: {:.4f}'.format(source, score))
$ python3 split.py
Accuracy for yelp data: 0.7960
Accuracy for amazon data: 0.7960
Accuracy for imdb data: 0.7487