open ai reference
https://platform.openai.com/docs/api-reference/images/create
なんじゃこりゃ…
use std::io::{stdout, Write};
use curl::easy::{Easy, List};
use dotenv::dotenv;
use std::env;
fn main() {
let _ = dotenv();
let auth = format!("Authorization: Bearer {}", &env::var("OPENAI_API_KEY").unwrap());
let mut list = List::new();
list.append("Content-Type: application/json").unwrap();
list.append(&auth).unwrap();
let mut handle = Easy::new();
handle.url("https://api.openai.com/v1/images/generations").unwrap();
handle.post(true).unwrap();
handle.http_headers(list).unwrap();
let post_field_bytes = "{ \"model\": \"dall-e-3\", \"prompt\": \"A cute baby sea otter\", \"n\": 1, \"size\": \"1024x1024\"}".as_bytes();
handle.post_fields_copy(post_field_bytes).unwrap();
handle.write_function(|data| {
stdout().write_all(data).unwrap();
Ok(data.len())
}).unwrap();
handle.perform().unwrap();
}
Compiling sample v0.1.0 (/home/vagrant/dev/rust/sample)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/sample`
{
“created”: 1738034805,
“data”: [
{
“revised_prompt”: “Imagine a charming depiction of a baby sea otter. This adorable little creature is floating on its back in the gentle waves of a clear blue ocean. Its fur, a shade of rich brown, is slick and slightly wet from its playful activities in the water. The otter’s bright, curious eyes are looking directly towards us, as if inviting us to join the fun. It is holding a small, smooth pebble with its tiny paws, perhaps preparing to break open a shell for a feast. The entire image exudes a sense of playfulness, innocence and natural beauty.”,
“url”: “https://oaidalleapiprodscus.blob.core.windows.net/private/org-wo6kkwujqXYOYKEKz5X1nc60/user-JNvegCxXc2nlYJGCjwPgwcv7/img-Z6WR4EMZFstjPwV7BQriTyyf.png?st=2025-01-28T02%3A26%3A45Z&se=2025-01-28T04%3A26%3A45Z&sp=r&sv=2024-08-04&sr=b&rscd=inline&rsct=image/png&skoid=d505667d-d6c1-4a0a-bac7-5c84a87759f8&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2025-01-28T00%3A53%3A13Z&ske=2025-01-29T00%3A53%3A13Z&sks=b&skv=2024-08-04&sig=V2MXStLlOGdaaB7OOT65JzvSFLRA9zOMHOLN8UPOg1o%3D”
}
]
}
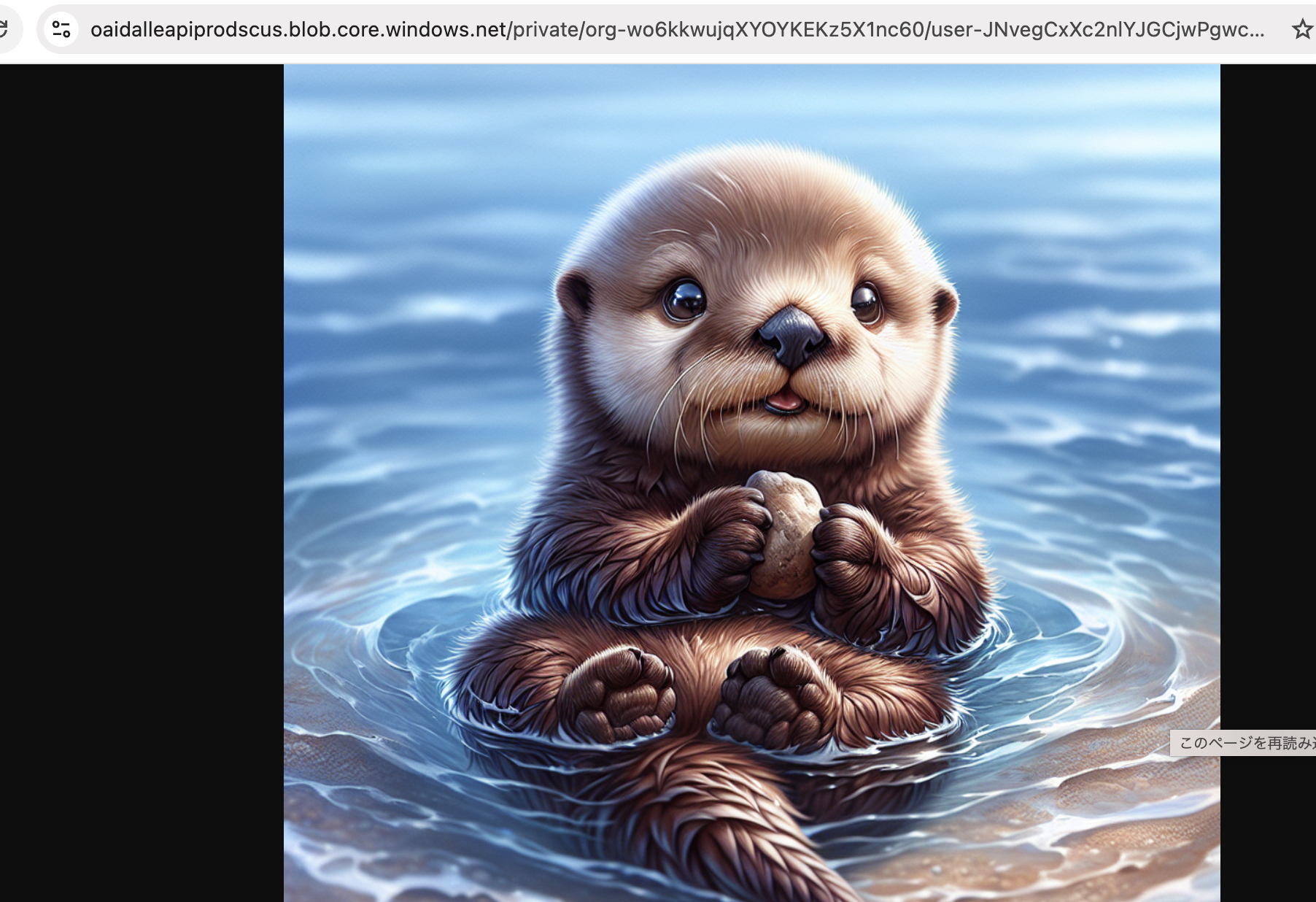
面白いんだけど、サービスとして提供するのは抵抗あるな…