
Chat GPTと同じように、Canvaでも画像合成ができる。
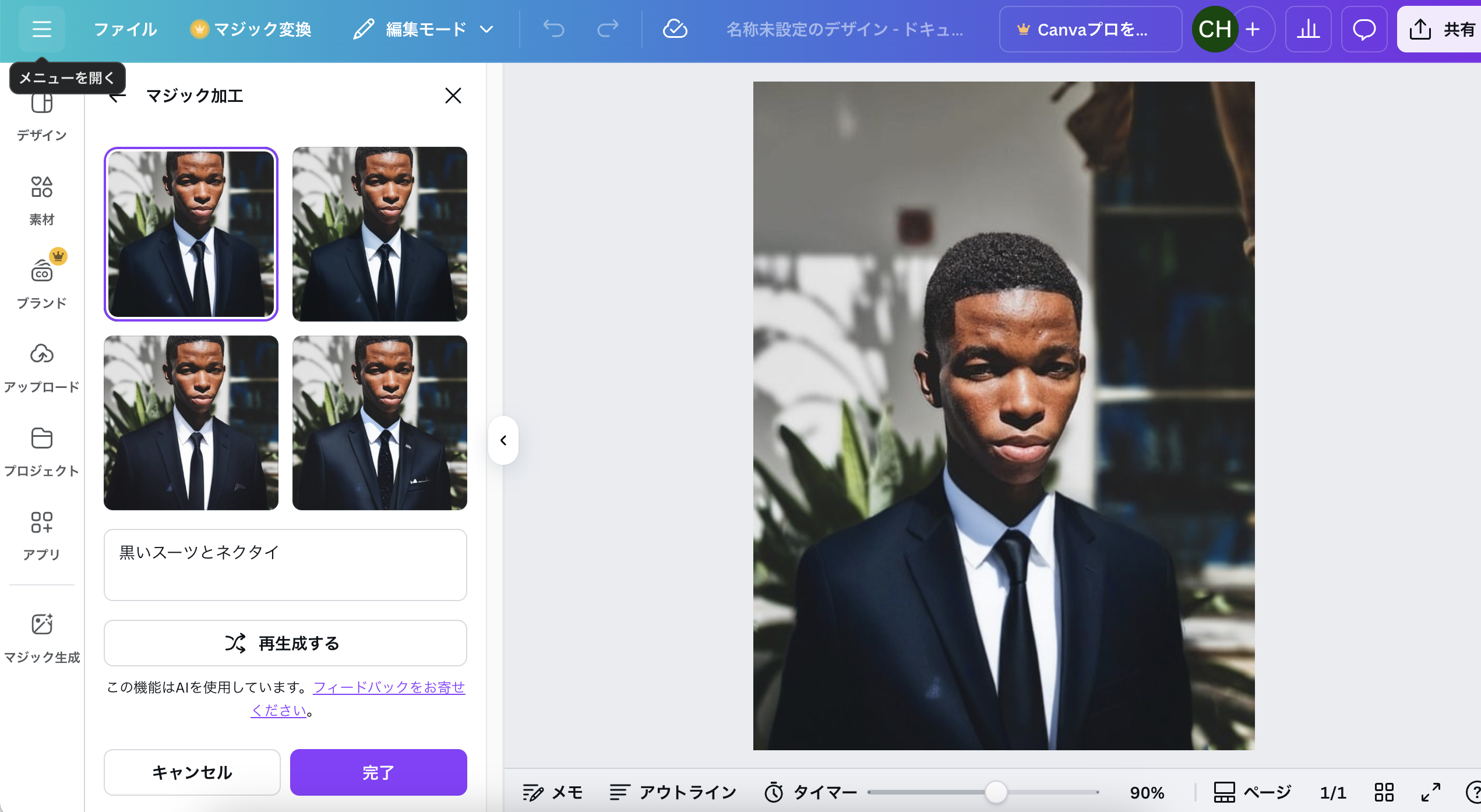
背景を変えることもできる。
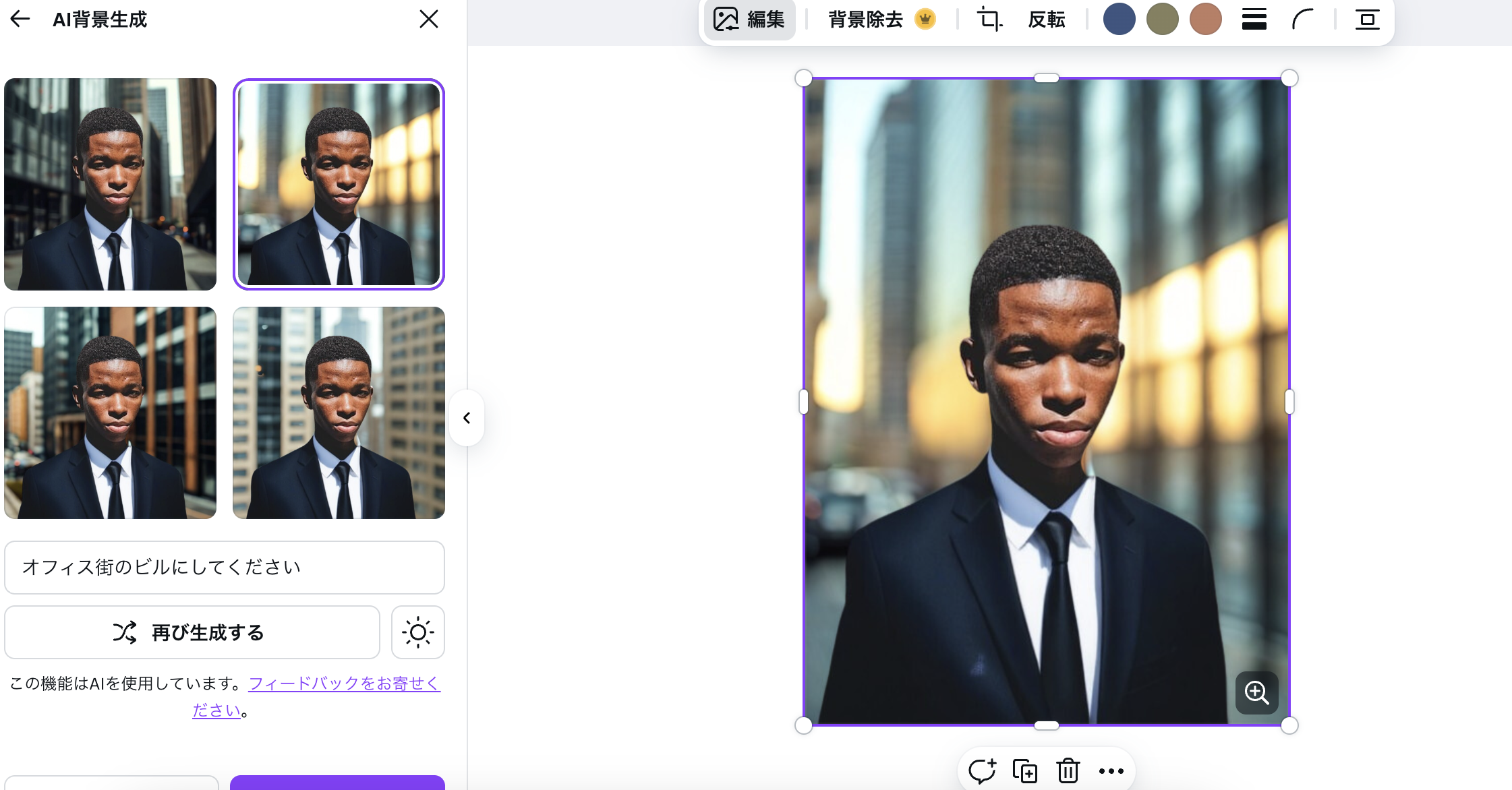
🔍 Canvaマジック編集の仕組みイメージ
ユーザーがマスクを指定(首から下など)
テキスト指示(例: “a black suit and tie”)を入力
Canvaのサーバー側で拡散モデルに送信
画像の「残す部分(顔)」を保持
マスク部分を inpainting(塗り直し)
出力候補を複数生成し、ユーザーに提示
つまり内部的には、Stable Diffusion の inpainting とほぼ同じ流れ
Canvaの服差し替えも「Diffusion Model の inpainting」と考えて良い。
なんだこれは、凄すぎる。。。
### 動画の合成技術
1. 共通点(画像と同じ部分)
生成モデルを使う
画像生成で使うDALL·EやStable Diffusionのように、動画合成もニューラルネットワーク(特に生成モデル)を使います。
条件付き生成が可能
画像: 「黒いスーツを着た人」というプロンプト
動画: 「黒いスーツを着た人が歩く」というプロンプト
→ プロンプトに応じてフレームごとに生成する点は共通
データ表現はピクセルや特徴量
動画も結局は連続した画像(フレーム)なので、フレーム単位での画像合成技術が応用されます。
2. 動画ならではの追加課題
時間方向の一貫性
画像は単独で完結しますが、動画はフレーム間で連続性が必要
例: 人の手が前のフレームから急に消えると不自然
→ 「時間方向のモデル(Temporal model)」や「フロー情報」を使う
フレーム数が多い
1秒で30フレームなら30枚の画像を生成する必要がある
単純にフレームごとに画像生成すると重くなる
→ 先読みや特徴量伝播で効率化
マスクや編集の複雑さ
動画編集では「同じ位置のオブジェクトを全フレームでマスク」する必要がある
画像編集よりマスク処理が大規模かつ複雑
3. 技術例
画像拡張型
Stable Diffusion をフレームごとに生成+フレーム間のブレ補正
ビデオ特化型生成モデル
Imagen Video(Google)
Runway Gen-2
動画の時間方向情報も含めて生成する
既存動画の変換や編集
Deepfake や映像スタイル変換(例: 動画に別の服装や表情を合成)
元動画を入力として、時間方向に一貫した編集を行う
なるほど、なかなか勉強になるというか、面白いですね。