
$ mecab –version
mecab of 0.996
$ pip3 install install natto-py
### 全体フロー
1. 評価用のデータ作成
2. 評価テキストが入ってくる
3. 1文毎に分解してmecabを使って品詞分解
4. 用意してあった用語、名詞別リストと照らし合わせ、それぞれの点数を足し合わす
5. 上記の4を文の数だけ繰り返す
### コード
1. 設定コード
2. データを読み込むコード
3. 読み込んだデータを処理
4. 処理したデータを出力
import codecs, csv
import re
from natto import MeCab
import os
def nlp(data): nm = MeCab()
negaposi_dic = getNegaPosiDic()
sentenses = re.split("[。!!♪♫★☆>??()w]", data)
try: for sentense in sentenses:
negaposi = 0 result_all = nm.parse(sentense)
for word in result_words: try: word_toarray = re.split('[\t,]', word) if word_toarray[7] in negaposi_dic: negaposi = int(negaposi_dic[word_toarray[7]])
except Exception as e: print('%r' % e, flush=True) print(data, flush=True) return points
csvデータセットの中身
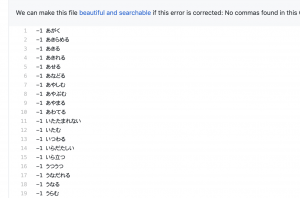
$ python3 app.py
美味しく炊けます。 安定の象印! 保温も良く臭くならないので良いです。 食べ過ぎ注意ですね
ERROR:natto.environment:MeCab dictionary charset not found
$ mecab -D
param.cpp(69) [ifs] no such file or directory: /usr/local/lib/mecab/dic/mecab-ipadic-neologd/dicrc