まず、public route table (public subnet割り当て)と private route table(private subnet割り当て) を作ります。
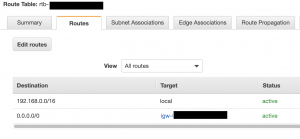
public route table
– internet gatewayを割り当てています。
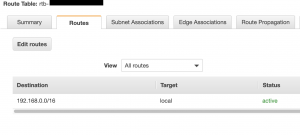
private route table
– 後でnat gatewayを割り当て
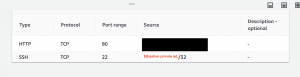
private subnetに配置しているEC2のセキュリティグループのインバウンドルール
-> sshのルールで、bastion serverの ${private IPv4 ip}/32 を設定する
### ローカルからbastionにssh
$ ssh ec2-user@${basionserverのpublic ip} -i ~/.ssh/*.pem
そして、bastionサーバにログインし、/.sshに 秘密鍵(*.pem)を配置する
### bastionからprivate subnetのec2にログイン
$ ssh -i .ssh/*.pem ec2-user@${bastionserverのprivate ip}
すごいハマった。3時間ぐらい。
ローカルからはpublic ipでsshログインするけど、bationからはprivate IPv4 ipでログインする
これ違い理解してないと、なんでログインできないか永遠にわからなかったわ