yum is an integrated management system for packages.
It manages RPM packages and is more convenient and easier to use than using the rpm command. yum manages and integrates RPM information and resolves dependencies automatically. It is in the same standing position as APT in Debian. By using yum, can update package of distribution, search for package, delete package, display package information, etc.
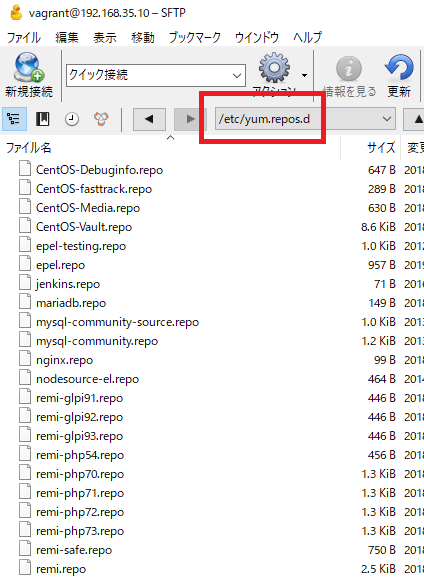
For the repository, a separate file is prepared and describe in “/etc/yum.repos.d”.
[vagrant@localhost ~]$ cd /etc/yum.repos.d
[vagrant@localhost yum.repos.d]$ ls
CentOS-Base.repo mariadb.repo remi-php54.repo
CentOS-Debuginfo.repo mysql-community-source.repo remi-php70.repo
CentOS-Media.repo mysql-community.repo remi-php71.repo
CentOS-Vault.repo nginx.repo remi-php72.repo
CentOS-fasttrack.repo nodesource-el.repo remi-php73.repo
epel-testing.repo remi-glpi91.repo remi-safe.repo
epel.repo remi-glpi92.repo remi.repo
jenkins.repo remi-glpi93.repo
[vagrant@localhost yum.repos.d]$ sudo touch logstash.repo
公式と同じように書きます。
[vagrant@localhost yum.repos.d]$ sudo vi logstash.repo
[vagrant@localhost yum.repos.d]$ cat logstash.repo
[logstash-5.x]
name=Elastic repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[vagrant@localhost ~]$ sudo yum install logstash
読み込んだプラグイン:fastestmirror
インストール処理の設定をしています
Loading mirror speeds from cached hostfile
* base: ftp.nara.wide.ad.jp
* extras: ftp.nara.wide.ad.jp
* remi-safe: ftp.riken.jp
* updates: ftp.nara.wide.ad.jp
https://artifacts.elastic.co/packages/5.x/yum/repodata/repomd.xml: [Errno 14] PYCURL ERROR 6 – “Couldn’t resolve host ‘artifacts.elastic.co'”
他のミラーを試します。
エラー: Cannot retrieve repository metadata (repomd.xml) for repository: logstash-5.x. Please verify its path and try again
なにいいいいいいいいいいいいいいいいいいいいい
artifacts.elastic.coが違うだと。。。
REDHATの公式を見る
>Satellite または Proxy サーバーに完全修飾ドメイン名 (FQDN) が設定されており、Apache が使用する SSL 証明書の CommonName (CN) が FQDN に設定されていることを確認してください。
https://access.redhat.com/ja/solutions/1307833
[vagrant@localhost yum.repos.d]$ grep CN /etc/httpd/conf/ssl.crt/server.crt
grep: /etc/httpd/conf/ssl.crt/server.crt: そのようなファイルやディレクトリはありません
[vagrant@localhost yum.repos.d]$ grep ^SSLCert /etc/httpd/conf.d/ssl.conf
SSLCertificateFile /etc/pki/tls/certs/localhost.crt
SSLCertificateKeyFile /etc/pki/tls/private/localhost.key
何言いいいいいいいいいいいいいいいい、わからん。
あかん、とりあえずelasticsearchに行こう。