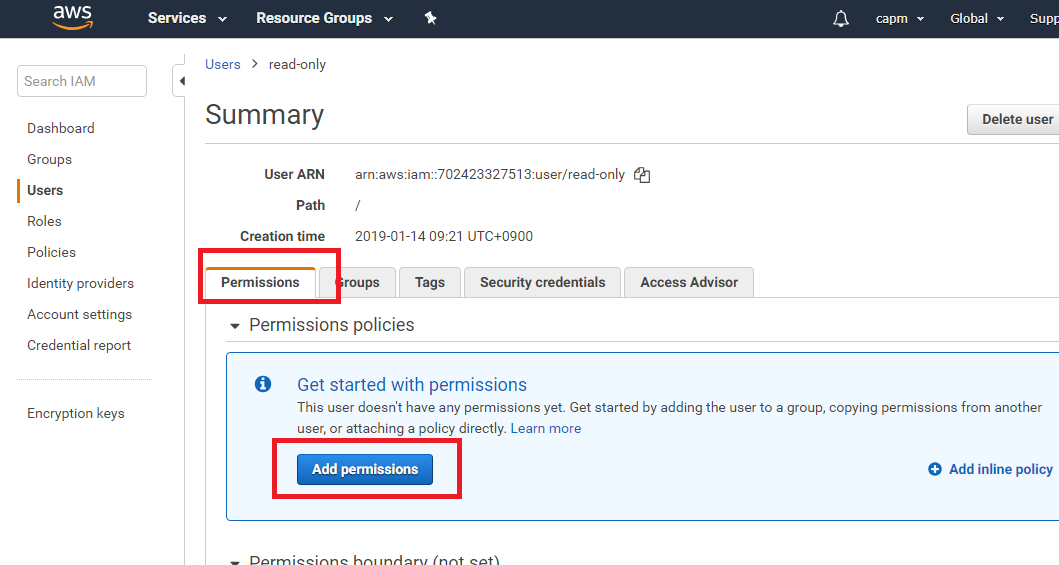
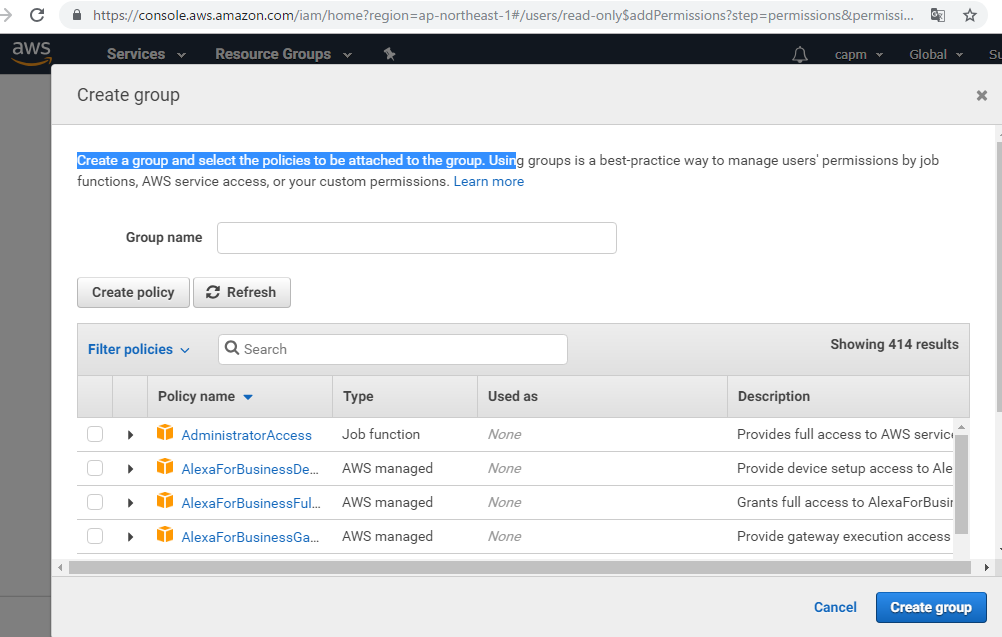
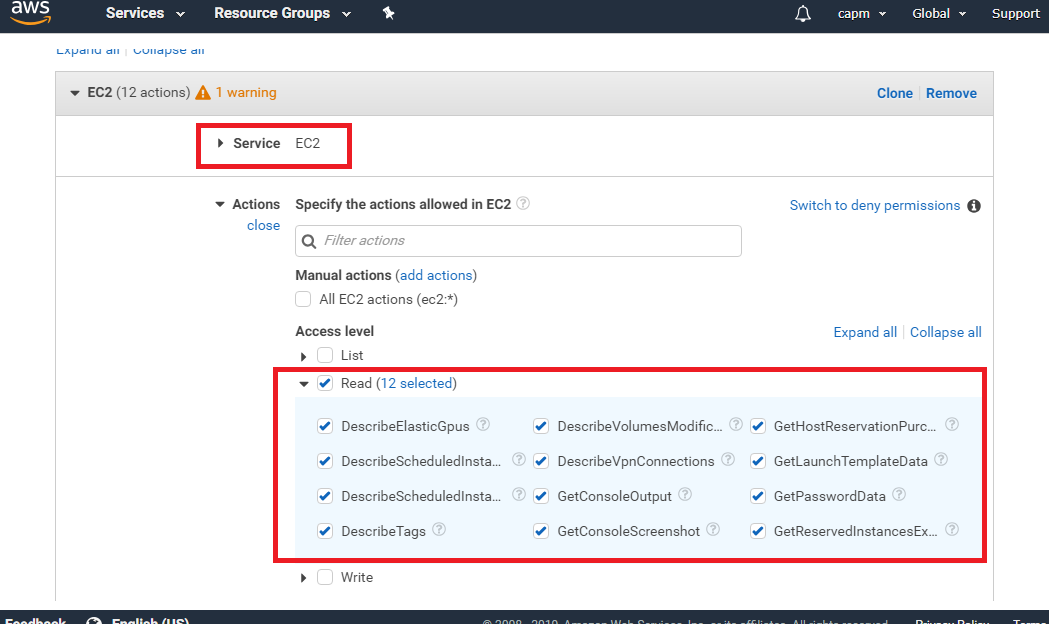
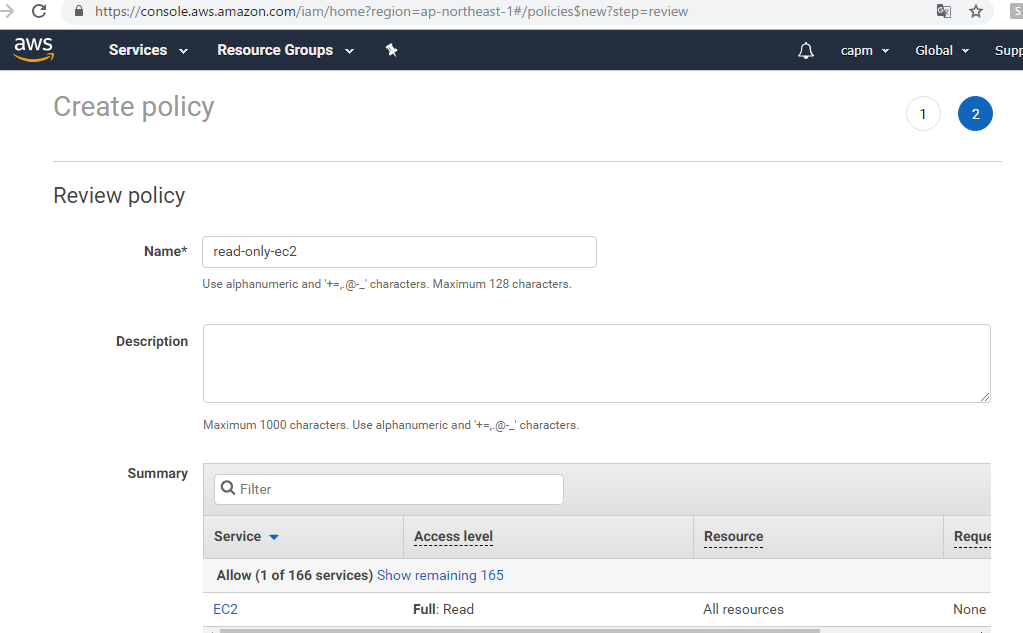
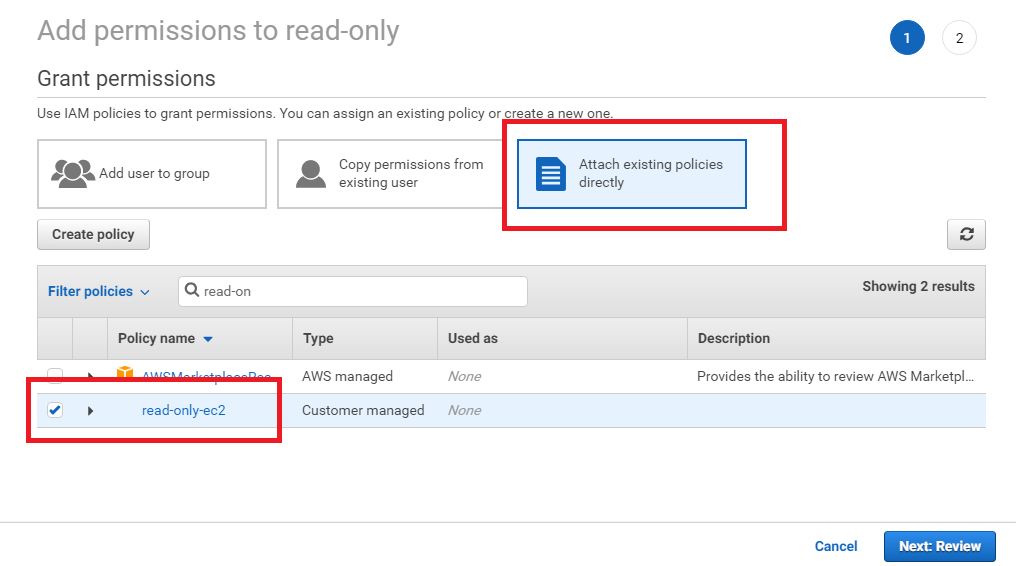
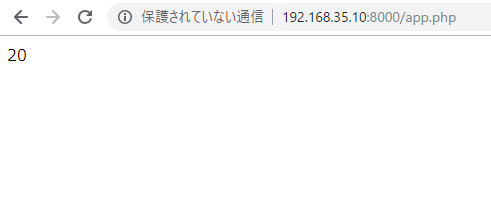
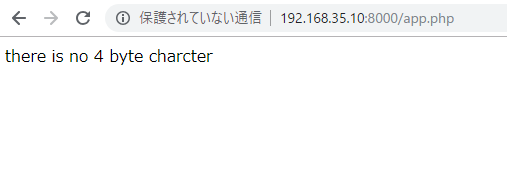
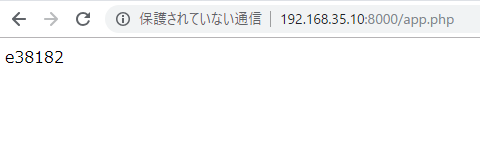
It is necessary to make access right to s3 bucket beforehand with IAM.
Use php library to upload to s3. Here is code.
require 'vendor/autoload.php';
if(file_exists($_FILES['upfile']['tmp_name'])){
$ext = substr($_FILES['upfile']['name'], strrpos($_FILES['upfile']['name'],'.') + 1);
echo $ext."<br>";
if(strtolower($ext) !== 'png' && strtolower($ext) !== 'jpg' && strtolower($ext) !== 'jpeg' && strtolower($ext) !== 'gif'){
echo '画像以外のファイルが指定されています。画像ファイル(png/jpg/jpeg/gif)を指定して下さい';
exit();
}
$tmpname = str_replace('/tmp/', '', $_FILES['upfile']['tmp_name']);
echo $tmpname;
$s3client = new Aws\S3\S3Client([
'credentials' => [
'key' => '',
'secret' => ''
],
'region' => 'ap-northeast-1',
'version' => 'latest',
]);
$result = $s3client->putObject([
'Bucket' => 'zeus-image',
'Key' => 'test.png',
'SourceFile' => $_FILES['upfile']['tmp_name'],
'Content-Type' => mime_content_type($_FILES['upfile']['tmp_name']),
]);
}
?>
<div id="content">
<h2>画像管理</h2>
<hr>
<form action="#" method="POST" enctype="multipart/form-data">
<div id="drag-drop-area">
<div class="drag-drop-inside">
<p class="drag-drop-info">ここにファイルをアップロード</p>
<p>または</p>
<!-- <input type="file" value="ファイルを選択" name="image"> -->
<p class="drag-drop-buttons"><input id="fileInput" type="file" value="ファイルを選択" name="upfile"></p>
<input type="submit" value="送信">
</div>
</div>
</form>
HTML form view
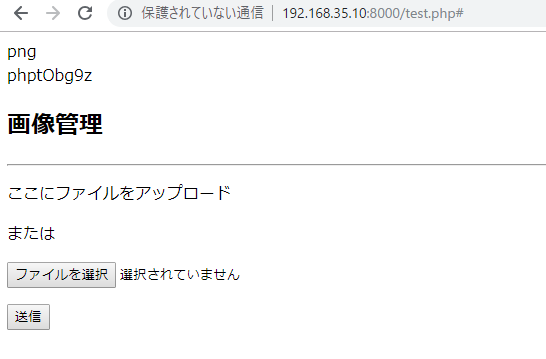
s3
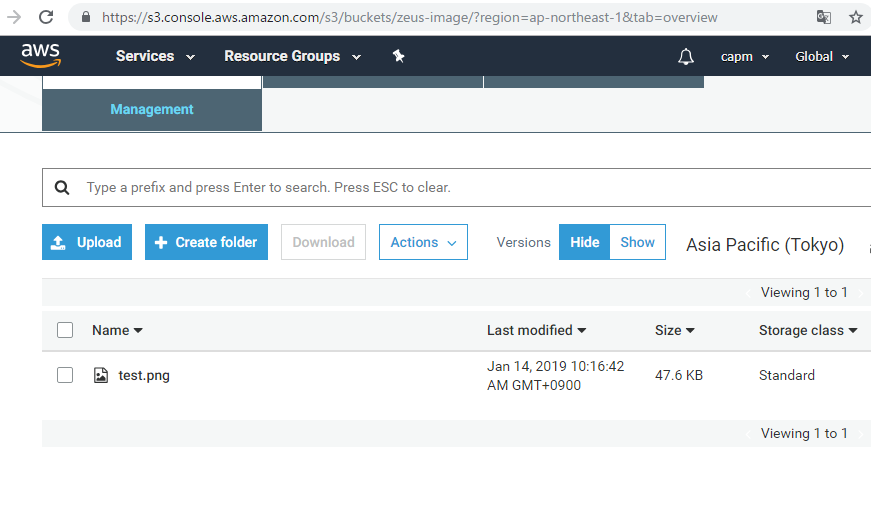
You can confirm that it is being uploaded properly.