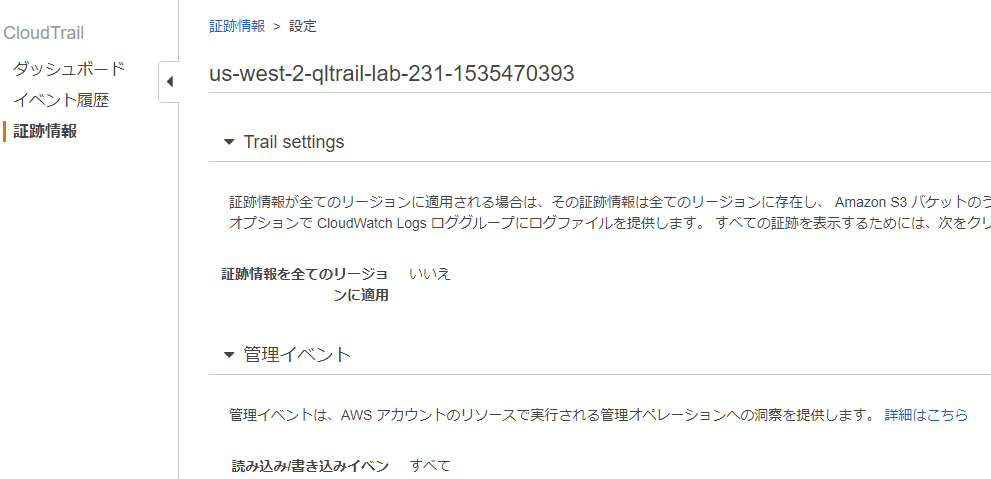
AWS CloudTrail
Amazon Elasticsearch Service
-> 分析サービス
一気に詰め込みすぎて大分こんがらがってきました。
cloud watch
kibana
ソフトウェアエンジニアの技術ブログ:Software engineer tech blog
随机应变 ABCD: Always Be Coding and … : хороший

AWS CloudTrail
Amazon Elasticsearch Service
-> 分析サービス
一気に詰め込みすぎて大分こんがらがってきました。
cloud watch
kibana
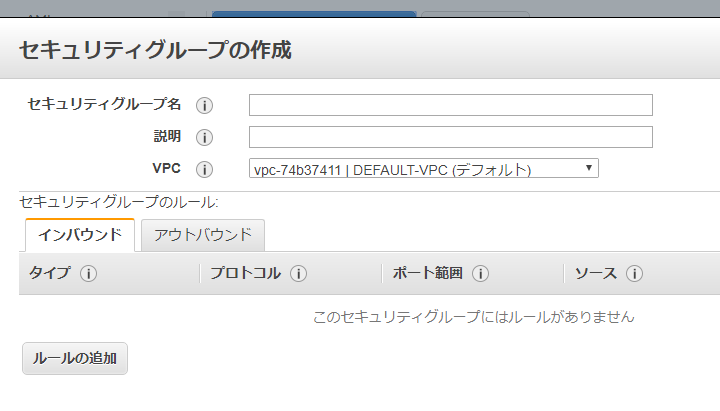
EC2 に行き、セキュリティグループを触ります。

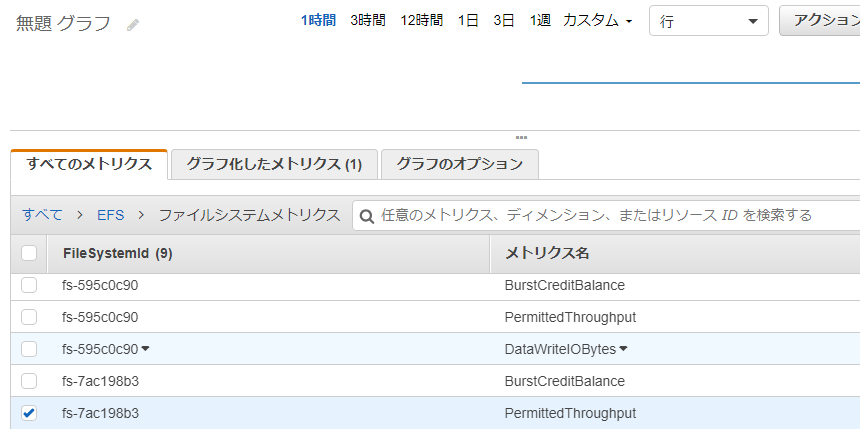
-ファイルシステムの作成
何やってるか、わからなくなってくる。
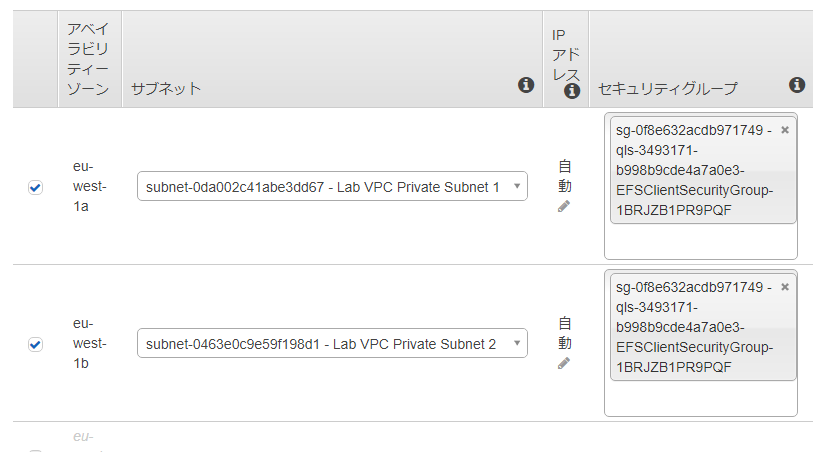
ファイルシステムへのアクセス
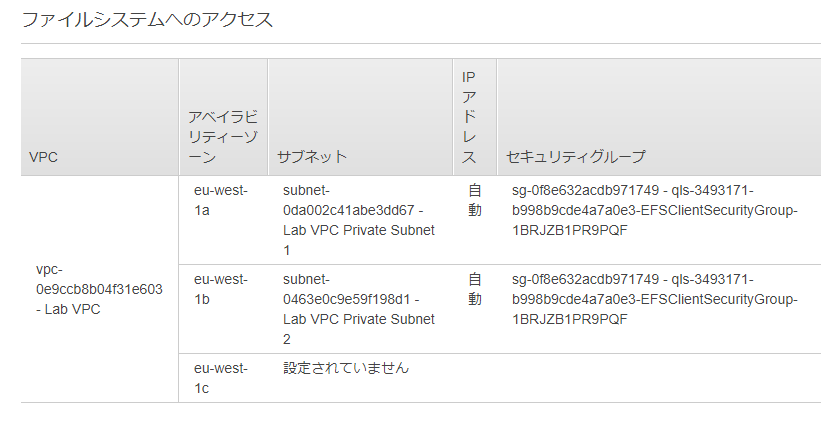
VPC、アベイラビリティゾーン、サブネット、IPアドレス、セキュリティグループがあります。
puttyでec2にログインします。
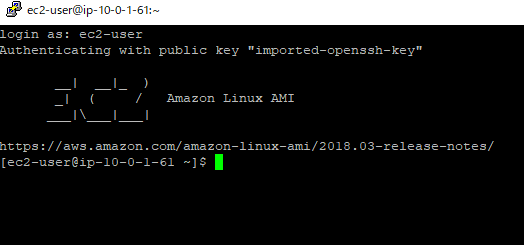
mount instruction
sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport fs-7ac198b3.efs.eu-west-1.amazonaws.com:/ efs
[ec2-user@ip-10-0-1-61 ~]$ sudo df -hT
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 488M 56K 488M 1% /dev
tmpfs tmpfs 497M 0 497M 0% /dev/shm
/dev/xvda1 ext4 7.8G 1.2G 6.5G 16% /
sudo fio –name=fio-efs –filesize=10G –filename=./efs/fio-efs-test.img –bs=1M –nrfiles=1 –direct=1 –sync=0 –rw=write –iodepth=200 –ioengine=libaio
CloudWatch
なんだこれ、凄いな。
IAMで作成します。
キーID
arn:aws:kms:us-east-1:835000831331:key/fac3b7bf-50f8-4c2f-8e86-c986f32b5511
CloudTrail
S3でuploadする際に、AWS KMS マスターキーで暗号化キーを選択します。
https://s3-us-west-2.amazonaws.com/mycloudtrailbucket7777/AWSLogs/835000831331/CloudTrail/us-west-2/2018/08/28/835000831331_CloudTrail_us-west-2_20180828T1225Z_sQK866tTbfY8AWgK.json.gz
access denied.
ネットワーキング & コンテンツ配信ですね。
CloudFront distributionでS3を選択します。
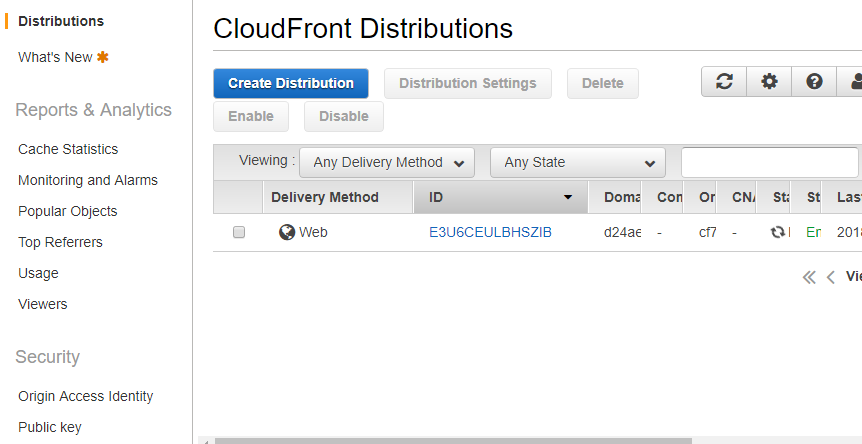
Distribution ID E3U6CEULBHSZIB
ARN arn:aws:cloudfront::838236696057:distribution/E3U6CEULBHSZIB
Log Prefix –
Delivery Method Web
Cookie Logging Off
Distribution Status InProgress
Comment –
Price Class Use All Edge Locations (Best Performance)
AWS WAF Web ACL –
State Enabled
Alternate Domain Names (CNAMEs) –
SSL Certificate Default CloudFront Certificate (*.cloudfront.net)
Domain Name d24aew1nc9kquu.cloudfront.net
Custom SSL Client Support –
Security Policy TLSv1
Supported HTTP Versions HTTP/2, HTTP/1.1, HTTP/1.0
IPv6 Enabled
Default Root Object –
Last Modified 2018-08-28 21:03 UTC+9
Log Bucket
deployに15~20分かかるとのこと。
A cluster is a fully managed data warehouse that consists of a set of compute nodes. Each cluster runs an Amazon Redshift engine and contains one or more databases.
クラスターの起動
詳細設定
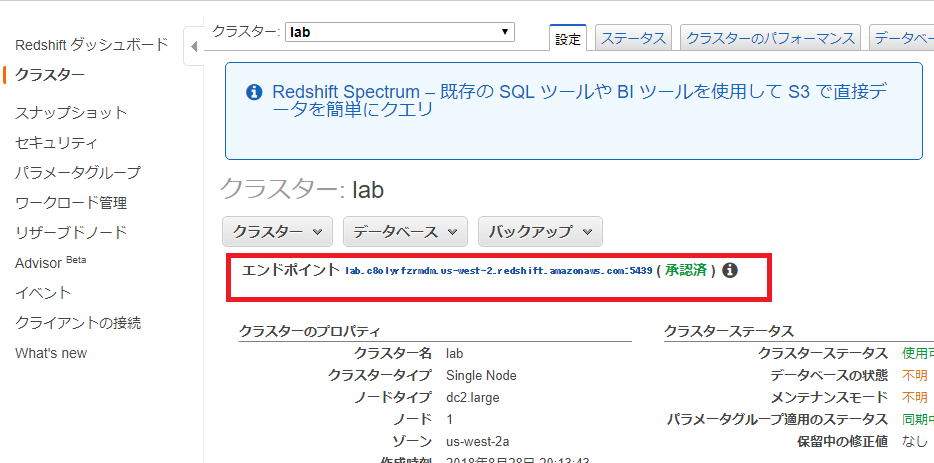
クラスターの起動
クラスターのエンドポイント
connect
うお!なんだこれ
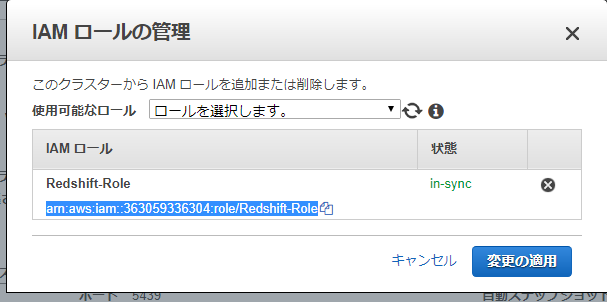
IAMロール
run query
COPY users FROM 's3://awssampledbuswest2/tickit/allusers_pipe.txt' CREDENTIALS 'aws_iam_role=arn:aws:iam::363059336304:role/Redshift-Role' DELIMITER '|';
S3からimport
凄い
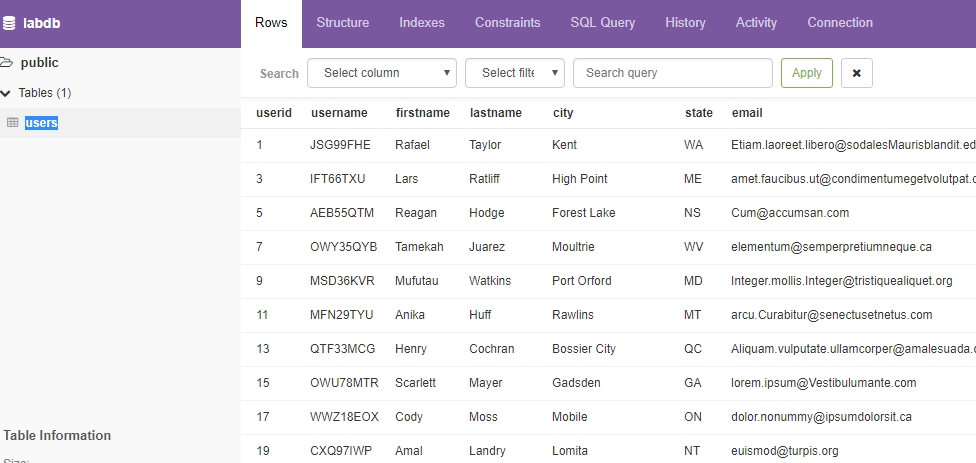
SELECT userid, firstname, lastname, city, state FROM users WHERE likesports AND NOT likeopera AND state = 'OH' ORDER BY firstname;
割と早いですね。
ここでもCSVをS3に保存して処理してます♪
概念図
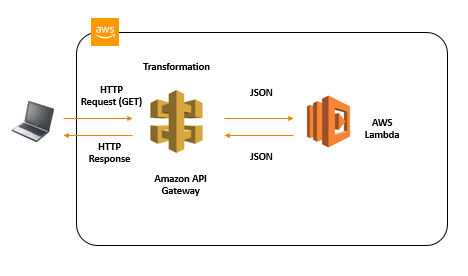
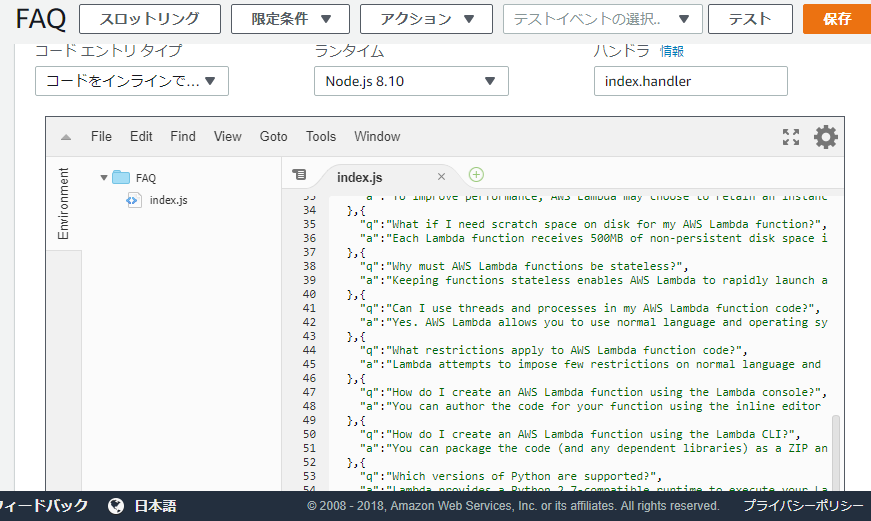
Lambda Node.js 8.10を選択します。
index.jsをsetする。
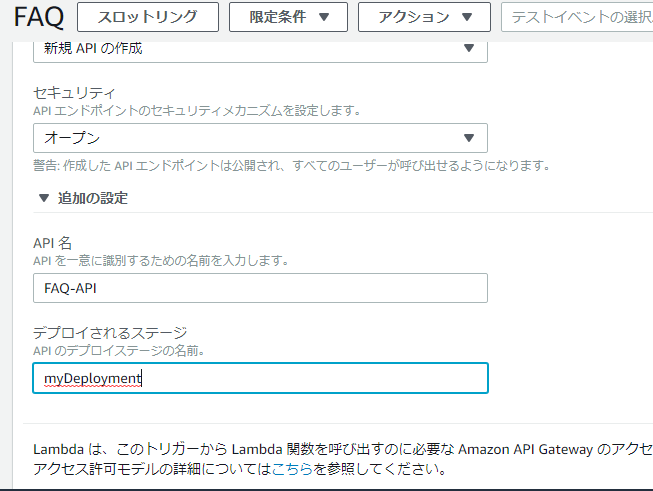
新規API
{“q”:”How do I compile my AWS Lambda function Java code?”,”a”:”You can use standard tools like Maven or Gradle to compile your Lambda function. Your build process should mimic the same build process you would use to compile any Java code that depends on the AWS SDK. Run your Java compiler tool on your source files and include the AWS SDK 1.9 or later with transitive dependencies on your classpath. For more details, see our documentation.”}
う~ん、よくわからん。lambdaと組み合わせて使ってますね。他も、AWSのメニューとの組み合わせが多いですな。
IAMに行きます。Securityは詳しくなりたい。
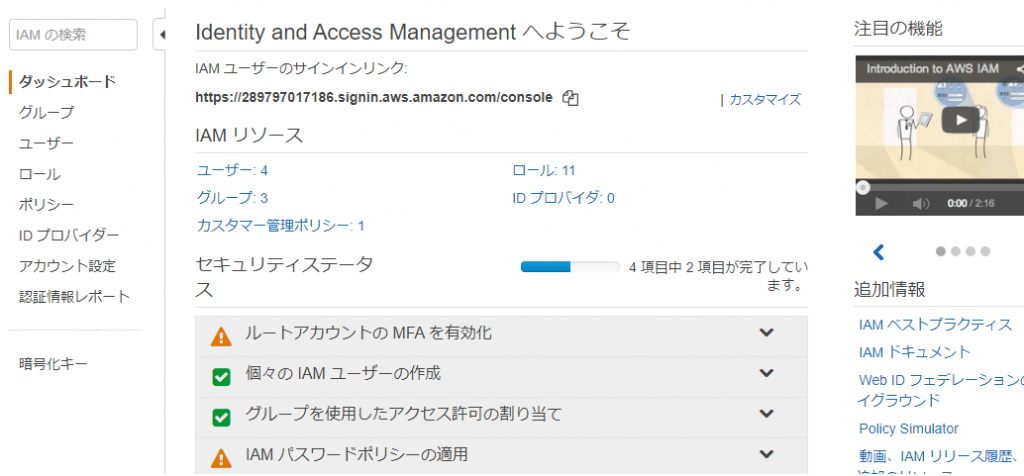
in the navigation pane on the left, click users.
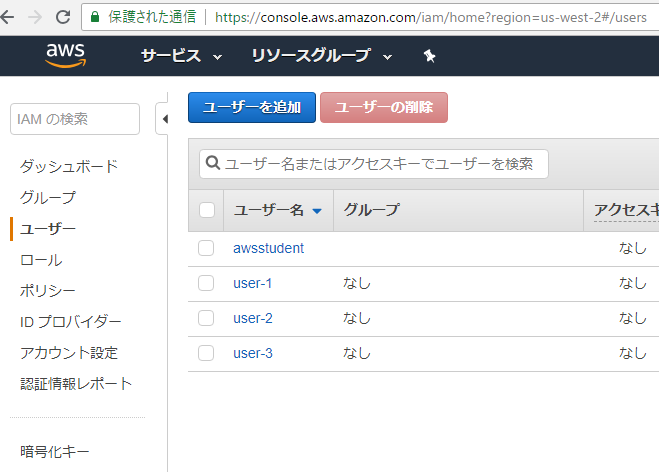
あ、userとroleだ。これはIAMでなくてもやりますね。
ユーザー1はアクセス権限がありません。
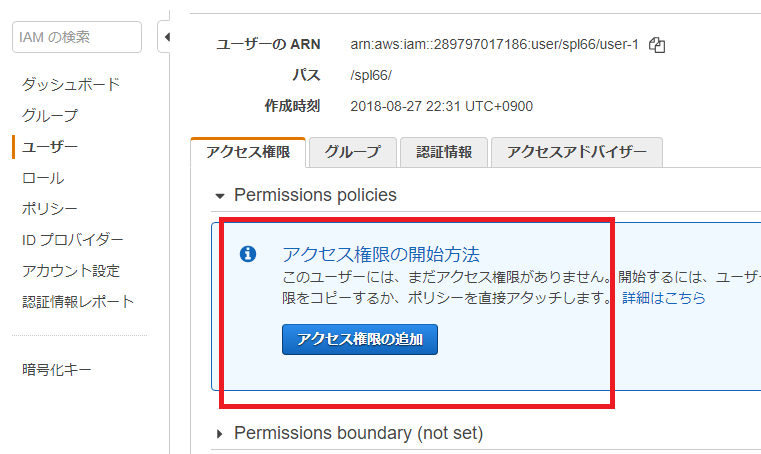
ユーザーだけでなく、グループもある。
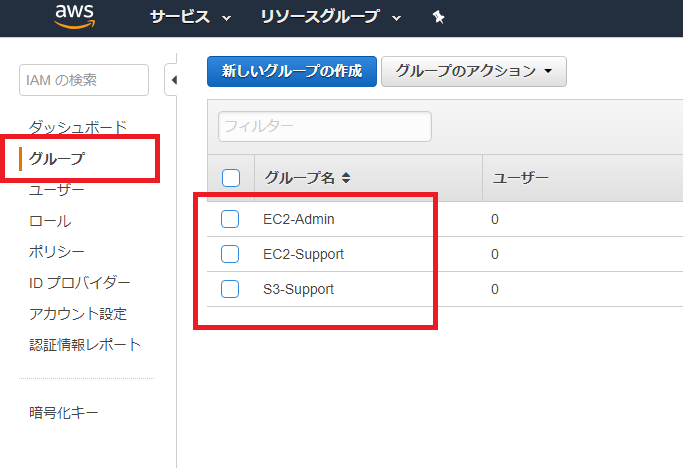
IAM Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "ec2:Describe*",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "elasticloadbalancing:Describe*",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"cloudwatch:ListMetrics",
"cloudwatch:GetMetricStatistics",
"cloudwatch:Describe*"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "autoscaling:Describe*",
"Resource": "*"
}
]
}
business scenario
User In Group Permissions
user-1 S3-Support Read-Only access to Amazon S3
user-2 EC2-Support Read-Only access to Amazon EC2
user-3 EC2-Admin View, Start and Stop Amazon EC2 instances
Groupにユーザーを追加
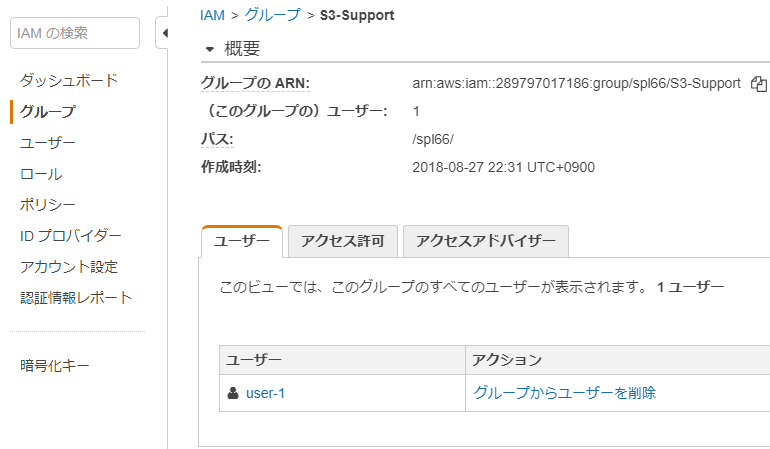
作成したユーザー+permissionでコンソールにログインできるようになる。
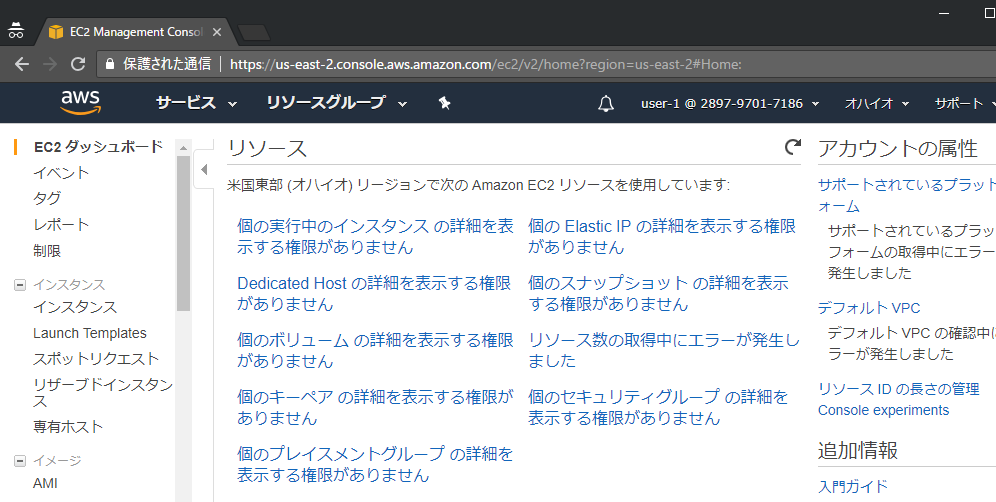
なるほどね。
意外と重要な知識だった。
ガンガン行きます。
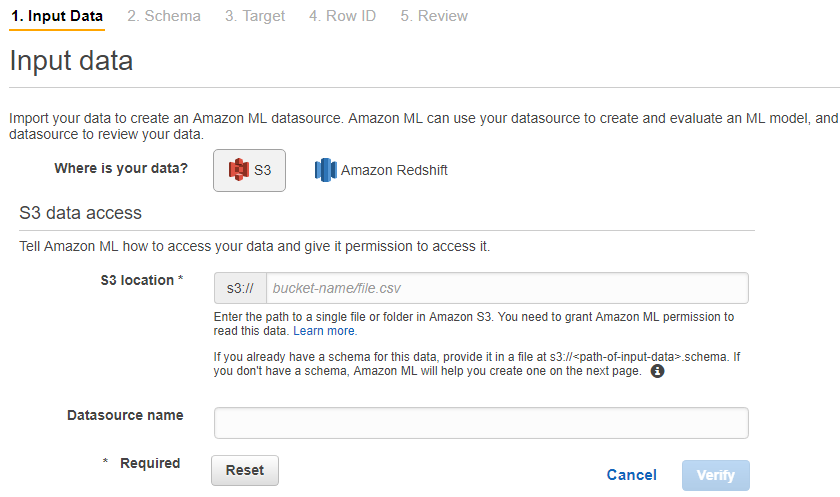
というか、Amazon Redshiftって何だ。。。 dataを保存できるのか。
modeling process
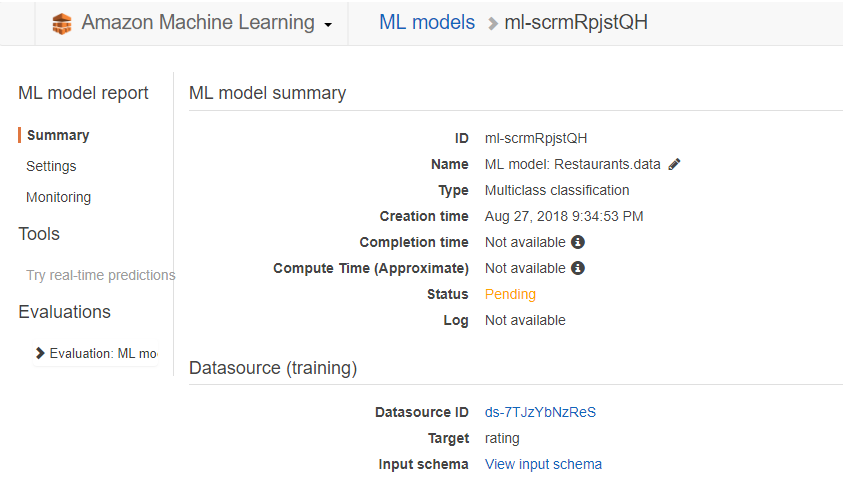
モデリングしてる模様
completed
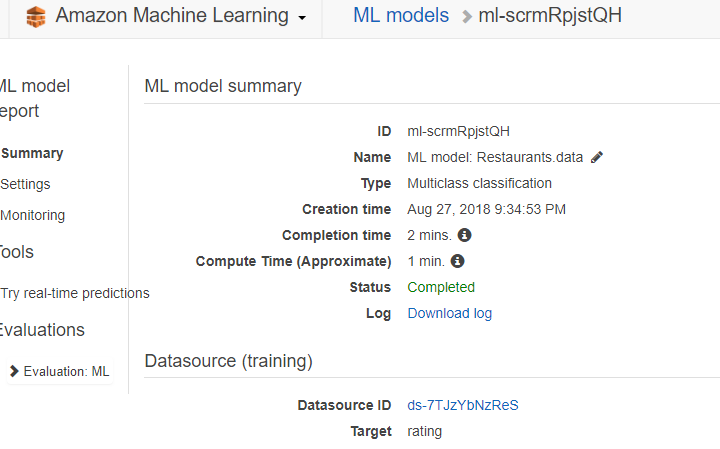
Try real-time prediction
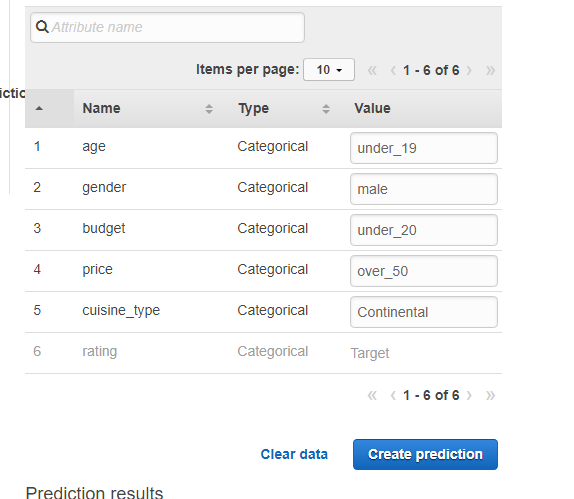
ここで予想します。
うーん、なんとなく流れは分かったようなわからないような。
データセットが用意されていると、単なる作業で頭使わないので駄目ですね。
Amazon machine learning モデルの概念図
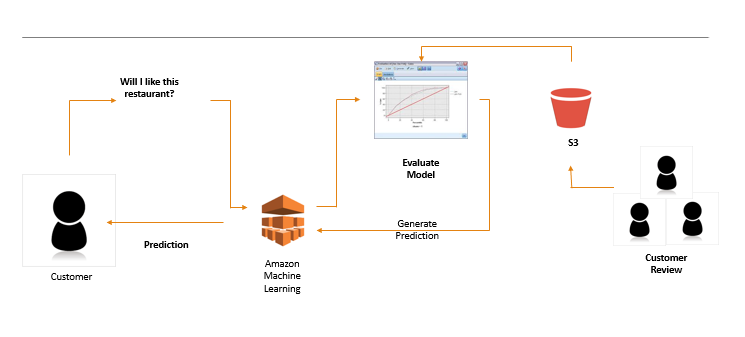
what is amazon machine learning
amazon ML can be used to make predictions for a variety of purposes. For example, you could build a model in Amazon ML that will predict whether a given customer is likely to respond to a marketing offer. Amazon ML creates models from supervised data sets. This means that the model is based on a set of previous observations. This set of observations consists of features or attributes as well as the target outcome. In the marketing offer example, the features might include the age, profession, and gender of the customer. The target outcome (also called the target variable) would be whether that particular customer responded to the marketing offer or not.
The process of creating a model from a set of known observations is called training. Once you have trained a model in Amazon ML, you can then use the model to predict outcomes from a set of attributes that matches the attributes used to train the model. Amazon ML scales so that you can make thousands of predictions concurrently. This is important, as today machine learning is often used to provide predictions in near real-time. In this lab, you will be using a machine learning model to predict which restaurants a customer is likely to favor based on the results of a search query.
data setをs3のバケットのuploadする。
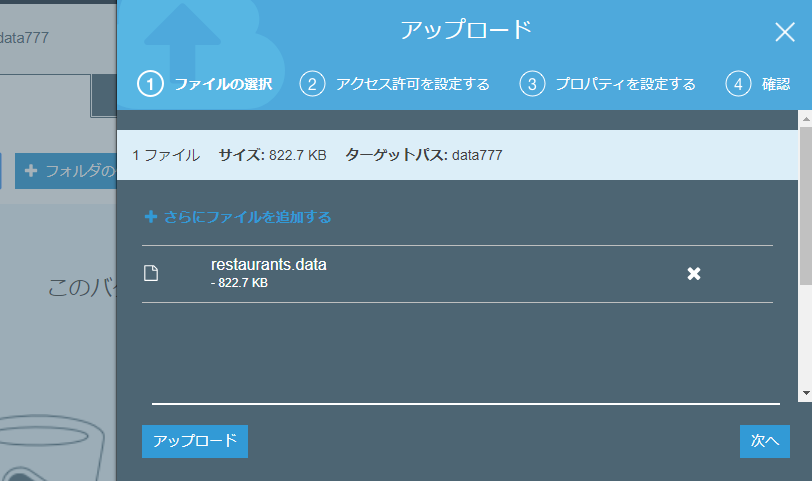
なるほど、S3はこういう風に使うのね。
machine learningを選択する
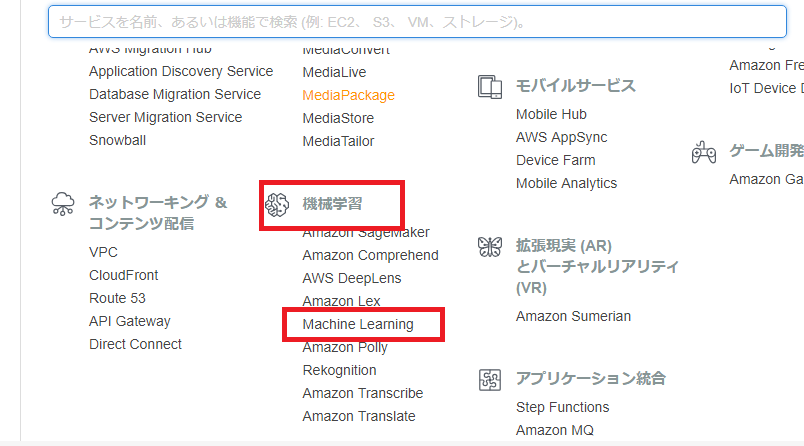
流石にまだ翻訳されてないな。
bucketを作成し、upload、permissionをread only everyoneに変更します。

バケットポリシー
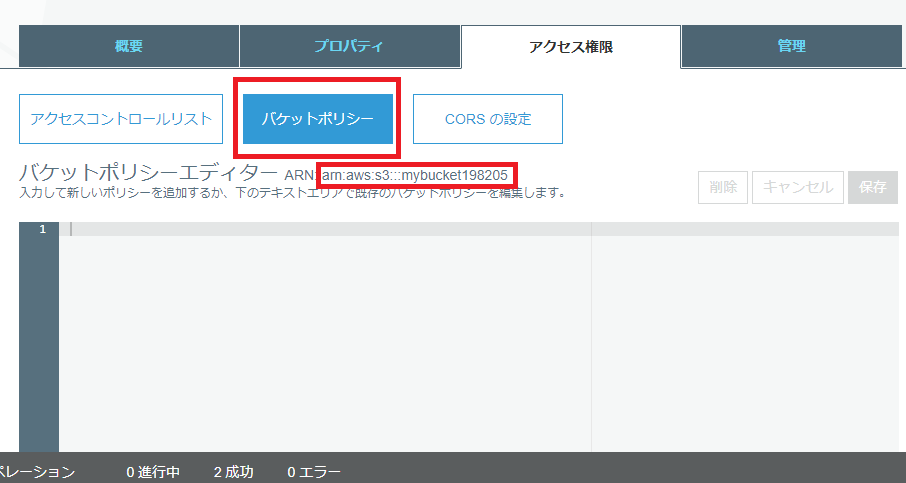
{
"Id": "Policy1535369626475",
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1535369623531",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::mybucket198205/*",
"Principal": "*"
}
]
}
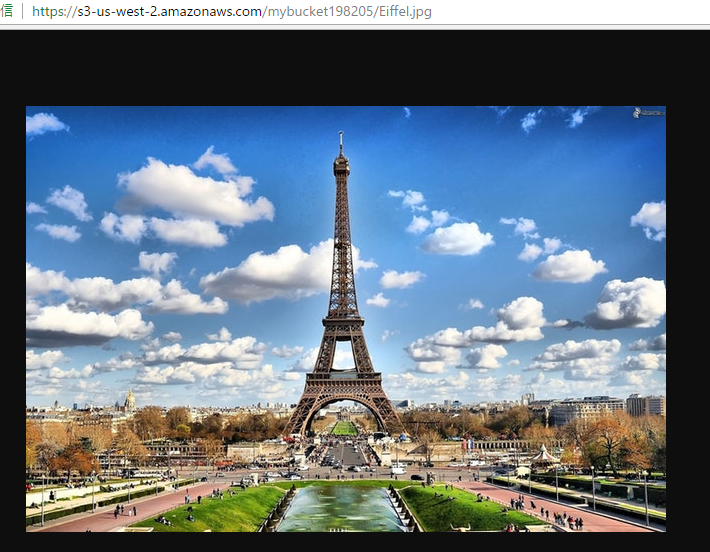
見れるようになりました♪
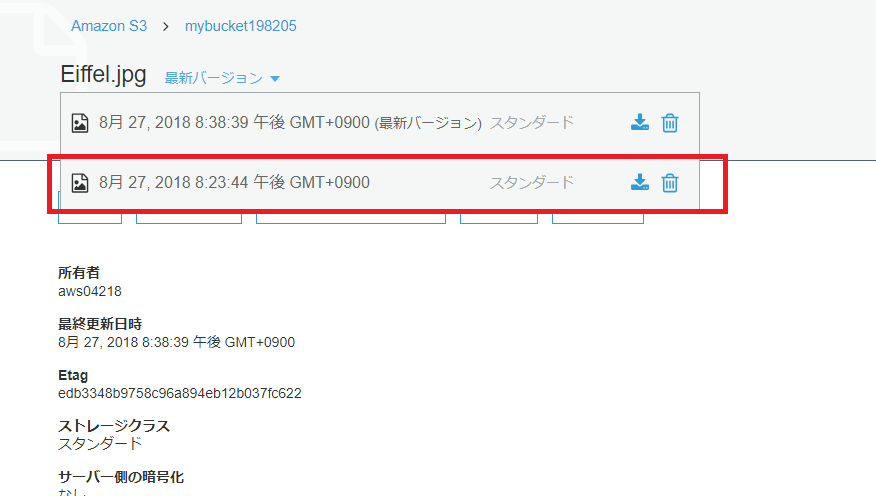
versioning: uploadしても古いバージョンを呼び出せる。
これは中々いいですね。