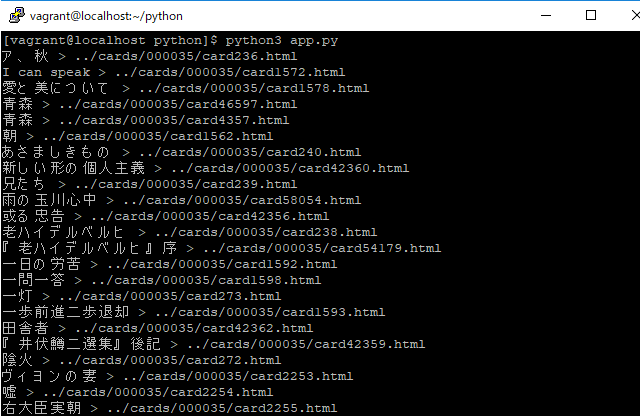
base urlの相対パスをurljoinで結合していく。
from urllib.parse import urljoin base = "http://hoge.com/html/crm.html" print( urljoin(base, "erp.html")) print( urljoin(base, "accounting/ifrs.html")) print( urljoin(base, "../scm.html")) print( urljoin(base, "../img/bi.png")) print( urljoin(base, "../css/style.css"))
[vagrant@localhost python]$ python3 app.py
http://hoge.com/html/erp.html
http://hoge.com/html/accounting/ifrs.html
http://hoge.com/scm.html
http://hoge.com/img/bi.png
http://hoge.com/css/style.css
もし、urljoinがhttpの場合は、そのまま絶対パスを返す。
from urllib.parse import urljoin base = "http://hoge.com/html/crm.html" print( urljoin(base, "erp.html")) print( urljoin(base, "http://www.nttdata.com/jp/ja/services/oss/index.html")) print( urljoin(base, "../scm.html"))
[vagrant@localhost python]$ python3 app.py
http://hoge.com/html/erp.html
http://www.nttdata.com/jp/ja/services/oss/index.html
http://hoge.com/scm.html
なるほど。