
/**
* 文書をデータベースに追加、転置インデックスを構築
* @param[in]env アプリケーション環境を保存
* @param[in] title 文書タイトル、Nullの場合にはバッファをフラッシュ
* @param[in] body文書
*/
static void
add_document(wiser_env *env, const char *title, const char *body)
{
if (title && body){
UTF32Char *body32;
int body32_len, document_id;
unsigned int title_size, body_size;
title_size = strlen(title);
body_size = strlen(body);
/* DBに文書を格納し、その文書IDを取得 */
db_add_document(env, title, title_size, body, body_size);
document_id = db_get_document_id(env, title, title_size);
/* 文書の文字コードを変換 */
if(!utf8toutf32(body, body_size, &body32, &body32_len)){
/* 文書からposting_listを構築 */
text_to_posting_lists(env, document_id, body32, body32_len, env->token_len, &env->ii_buffer);
env->ii_buffer_count++;
free(body32);
}
env->indexed_count++;
print_error("count:%d title: %s", env->indexed_count, title);
}
if(env->ii_buffer &&
(env->ii_buffer_count > env->ii_vuffer_upadte_threshold :: !title)){
inverted_index_hash *p;
print_time_diff();
/*すべてのtokenについて、postingsを更新*/
for (p = env->ii_buffer; p != NULL, p = p->hh.next){
update_postings(env, p);
}
free_inverted_index(env->ii_buffer);
print_error("index flushed.");
env->ii_buffer = NULL;
env->ii_buffer_count = 0;
print_time_diff();
}
}
Month: October 2016
検索エンジンの仕組み
検索エンジンは、一般的に4つのコンポーネントから構成されているといわれる。
Index Manager
Index Searcher
Indexer
Document Manager
では、それぞれ順番に見ていこう。
-Index Manager
インデックス構造を持つデータを管理するコンポーネント。通常、二次記憶上のバイナリファイルとして管理。多くの場合、インデックスを圧縮して保存。
-Index Searcher
インデックスを用いて全文検索処理を行うコンポーネント。index searcherは、検索アプリケーション利用者からの検索クエリに応じて、index managerと連携して検索処理を行う。多くの場合、適合する検索結果を一定の基準で並び替え、その結果の上位のものをアプリケーションに返す。
-Indexer
検索対象のテキスト文章からインデックスを作成するコンポーネント。テキスト文章を解析して単語列へ分解し、その単語列をインデックス構造へと変換する。
-Document Manager
文章管理器は、検索対象の文章を蓄えておくデータベースを管理するコンポーネント。文章管理器は、検索クエリに適合する文章を文書データベースから取り出し、必要に応じてその文書の一部を抽出する。DBMSやDBMが通常使われる。
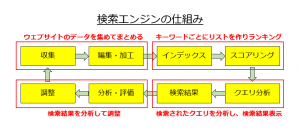
-Crawler
web上のHTMLなどの文章を収集するボット。
-ランキング
PageRankを代表とする検索対象の文章に点数付けを行うシステム。
アルゴリズム
効率の良いアルゴリズムをつくるには、複雑性だけでなく、計算時間(running time)、領域(storage space)など、動的なものも考慮しなければならない。つまり、CPU・メモリの性能や、サーバー環境を熟知した上で、プログラムを組むことに他ならない。
また、高レベルのものは、問題の重要な構造に対応している。
rubyでボットチャット
簡単なボットチャットを作ってみましょう!
といっても、いきなり精巧なモノは出来ないので、コマンドプロンプトで、入力に対して、何か一言返答してくれるものにします。一般的には、「人工無能」と呼ばれているモノです。人工知能の類語で、あまりいい響きではありませんね。
rubyでいきます。
インクルードの箇所は、分割せずにそのまま書いても問題ありません。
proto.rb
#! -ruby Ks
require './unmo'
def prompt(unmo)
return unmo.name + ':' + unmo.responder_name + '>'
end
puts('Unmo System prototype : proto')
proto = Unmo.new('proto')
while true
print('> ')
input = gets
input.chomp!
break if input == ''
response = proto.dialogue(input)
puts(prompt(proto) + response)
end
unmo.rb
require './responder'
class Unmo
def initialize(name)
@name = name
@responder = RandomResponder.new('Random')
end
def dialogue(input)
return @responder.response(input)
end
def responder_name
return @responder.name
end
def name
return @name
end
end
responder.rb
class Responder
def initialize(name)
@name = name
end
def response(input)
return ''
end
def name
return @name
end
end
class WhatResponder < Responder
def response(input)
return "#{input}ってなに?";
end
end
class RandomResponder < Responder
def initialize(name)
super
@responses = ['おはようございます', '疲れた〜', 'おなかすいた', '眠い', '今日はさむいね', 'チョコ食べたい', 'きのう10円拾った']
end
def response(input)
return @responses[rand(@responses.size)]
end
end
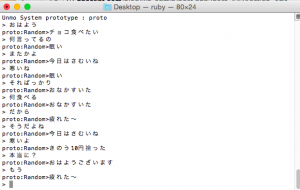
では、コマンドラインで動かしてみましょう。
いかがです、会話になっていませんが、それらしくはありますね。
インデクサのオーバーロード
クラスまたは構造体にインデクサを定義すると、a[i]のように、配列同様に、「インデックス」によるアクセスが可能になります。
同じクラスに複数のインデクサを定義することも可能です。その場合は、メソッドのオーバーロードと同様に、パラメータのシグネチャを別々にする必要があります。パラメータの型が同じで、「インデクサの型」だけが異なるインデクサを定義することはできません。
using System;
using System.Collections.Generic;
using System.Text;
namespace Gushwell.Sample {
public class Book {
public string Name { get; set; }
public string Author { get; set; }
public string Publisher { get; set; }
public string ISBN { get; set; }
public Book(string name, string author,
string publisher, string isbn) {
this.Name = name;
this.Author = author;
this.Publisher = publisher;
this.ISBN = isbn;
}
}
public class BookList {
private List<Book> books = new List<Book>();
public void Add(Book book){
books.Add (book);
}
// インデクサの定義
public Book this[int index]{
get {
return books [index];
}
}
public Book this[string ISBN]{
get {
foreach (Book b in books)
if (b.ISBN == ISBN)
return b;
return null;
}
}
}
class Program {
static void Main(string[] args){
BookList books = new BookList ();
books.Add(new Book("こころ", "夏目漱石",
"新潮社", "978-4101010137"));
books.Add (new Book ("人間失格", "太宰治", "角川書店", "978-4041099124"));
Book book1 = books [0];
Console.WriteLine (book1.Name);
Book book2 = books ["978-4041099124"];
Console.WriteLine (book2.Name);
Console.ReadLine ();
}
}
}
例外の再スロー
キャッチした例外を、そのまま上位層に再度投げることができます。これを例外の再スローといいます。例外を再スローする場合は、「throw」とだけ記述します。例外オブジェクトは指定しません。
using System;
using System.IO;
namespace ExceptionSample {
class Program {
static void Main(string[] args){
try {
Foo ();
} catch (System.ArgumentException) {
Console.WriteLine ("FooでArgumentException発生");
}
try {
Bar ();
} catch (System.ArgumentException) {
Console.WriteLine ("BarでArgumentException発生");
}
Console.ReadLine ();
}
public static void Foo() {
try {
Exec ();
} catch (System.ArgumentException) {
Console.WriteLine ("ExecでArgumentException発生");
}
Console.WriteLine ("Foo終了");
}
public static void Bar() {
try {
Exec ();
} catch (System.ArgumentException) {
Console.WriteLine ("ExecでArgumentException発生");
throw;
}
Console.WriteLine ("Bar終了");
}
public static void Exec(){
throw new System.ArgumentException ();
}
}
}
MainメソッドではFooメソッドとBarメソッドの呼び出し時の例外をキャッチするようにしています。Fooメソッド、Barメソッドの中でも、try-catchで例外処理をしています。
C#の例外処理
例外とは、プログラム実行時に発生するエラーのことです。C#の例外処理機能を使えば、実行中に発生する予期しないエラーや例外的な状況に対処できます。
C#では、「try」「catch」「finally」のキーワードを使って、例外処理を記述します。
最も基本的な書き方を以下に示します。
try {
// なんらかの処理
// この中で、例外が発生する可能性あり
} catch {
// 例外が発生したときに処理したいコード
}
例外の発生を検出したい場合は、tryブロック内に記述します。tryブロック内で何らかの例外が発生すると、処理が中断され、catchブロックに処理が遷移します。次のコードで確認してみてください。
using System;
namespace Gushwell.Sample {
class Program {
static void Main(string[] args){
try {
int n = 100;
string s = Console.ReadLine ();
int m = int.Parse (s);
int ans = n / m;
Console.WriteLine (ans);
} catch {
Console.WriteLine ("エラーが発生");
}
Console.ReadLine ();
}
}
}
ポリモーフィズム
ポリモーフィズムとは、異なる型を同一視することによって、複数のクラスを同じ操作で制御できる言語特性のことです。「オブジェクト指向」において、もっとも重要な機能の一つと言えるでしょう。
多くのデザインパターンは、このポリモーフィズムの機能を利用しています。
ポリモーフィズムを使わない例
using System;
using System.Collections.Generic;
namespace PolySample {
class Program {
static void Main(string[] args){
List<object> list = new List<object>();
list.Add(new CSharper());
list.Add(new Rubyist());
foreach(object p in list){
if (p is CSharper){
(p as CSharper).Work();
} else if (p is Rubyist){
(p as Rubyist).Work();
}
}
Console.ReadLine();
}
}
public class CSharper {
public void Work() {
Console.WriteLine ("C#でプログラムを書きます");
}
}
public class Rubyist {
public void Work () {
Console.WriteLine ("Rubyでプログラムを書きます");
}
}
}
ポリモーフィズムを利用した例
using System;
using System.Collections.Generic;
namespace PolySample {
class Program {
static void Main(string[] args){
List<Programmer> list = new List<Programmer> ();
list.Add(new CSharper());
list.Add(new Rubyist());
foreach(Programmer p in list){
p.Work ();
}
Console.ReadLine();
}
}
public abstract class Programmer {
public abstract void Work ();
}
public class CSharper : Programmer {
public override void Work() {
Console.WriteLine ("C#でプログラムを書きます");
}
}
public class Rubyist : Programmer {
public override void Work () {
Console.WriteLine ("Rubyでプログラムを書きます");
}
}
}
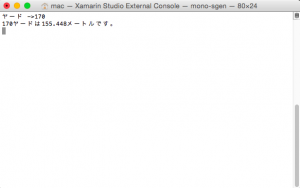
静的メンバーと静的クラス
プログラムが開始されるときは、どのクラスのインスタンスもnewされていない状態です。
using System;
class Program {
static void Main() {
Console.Write ("ヤード ->");
string s = Console.ReadLine ();
double yard = double.Parse (s);
double meter = YardToMeter (yard);
Console.WriteLine ("{0}ヤードは{1}メートルです。", yard, meter);
Console.ReadLine ();
}
// 静的メソッドとして定義
static double YardToMeter (double yd)
{
double meter = yd * 0.9144;
return meter;
}
}
C#のアクセス修飾子
クラスのメンバーへのアクセスを制御するためのものがアクセス修飾子です。C#には、「private」「public」「protected」「internal」の4つが用意されています。
publicなメンバーは、そのメンバーが定義されているクラスの外側から自由にアクセスすることが可能です。一方、privateなメンバーは、そのクラスの中からのみアクセスすることができます。
using System;
using System.IO;
namespace Sample {
class Program {
static void Main(string[] args){
NumericsPicker np = new NumericsPicker ("Sample.txt");
string line = np.GetNext ();
while (line != null){
Console.WriteLine (line);
line = np.GetNext ();
}
Console.ReadLine ();
}
}
class NumericsPicker {
private StreamReader reader;
public NumericsPicker(string filepath){
reader = new StreamReader(filepath);
}
private bool IsAllDigits(string line){
foreach (var c in line) {
if (!char.IsDigit (c))
return false;
}
return true;
}
public string GetNext(){
string line = reader.ReadLine ();
while (line != null && !IsAllDigits (line))
line = reader.ReadLine ();
return line;
}
}
}