
顔検出は2001年「Viola & Johns」の「Rapid Object Detection using a Boosted Cascade of Simple Features」という論文でアルゴリズムが発表され急速に普及していった。
https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
要点
– Integral-ImageによるHaar-like検出器の高速演算
– AdaBoostによる検出能力の強化
– 多段フィルタ(cascade)による非顔領域の高速排除
画像の中の特定の領域をくり抜いて、顔か否かの判定を関数で行う
→ただし、顔を判定する領域の大きさは計算する側では決められず、一定でないため、計算量が膨大になる
1.Haar-like検出器(Haar-like feature)
HaarウェーブレットにしてIntegral-Imageを組み合わせて高速化した
-> 目の辺りになる位置の上下に隣接する横長の長方形領域を切り出してそれぞれの領域の明度の平均をとる
-> 上の領域が明るくて下の領域が暗かったら顔画像の候補
-> 鼻筋の天辺よりは鼻筋の両脇の明るさの平均*4のほうが小さいことが多い
これらの判断基準だけで、顔候補が一気に減る
さらにIntegral-Imageを使うと、その計算が数回の加減算で可能になる。
窓サイズを変えるのもコントラストの調整も、手間が急激に減る

ViolaとJonesの論文では200個の特徴を使うだけでも95%の精度を実現できると書いてある。
上記を繰り返し処理するだけで、候補数が急減する
これを多段フィルタ(cascade)による非顔領域の高速排除という
2. AdaBoostによる検出能力の強化
異なった視点から対象を選択する分類器を組み合わせる
目の判定、口の判定など数多の分類器の中から良いものを使用する
正解の画像を大量に用意して、分類器の精度をテストし、精度の高い分類器を良い分類器として採用する
主なHaar-lieの分類器
a. Edge features
b. Line features
c. Center-surround features
OpenCVを用いた処理ロジックイメージ
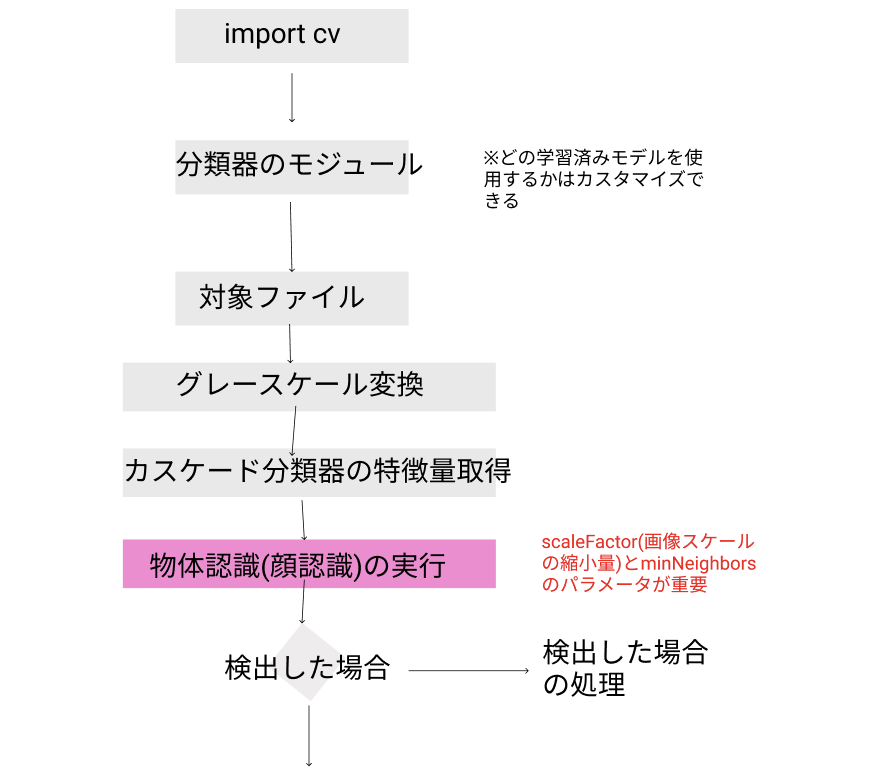
対象画像が、傾きがある可能性があれば、傾きを考慮した処理を入れる。
これはいわゆる顔か否かの判定だけだが、個人識別だと、顔のDBと照らし合わせて一致するかどうかを判定するのだろう。
イメージはできますね。
OpenCVの公式サポートは、Python, C++, Java