
from http.server import BaseHTTPRequestHandler, HTTPServer
class webserverHandler(BaseHTTPRequestHandler):
def do_GET(self):
try:
if self.path.endswith("/hello"):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
output = ""
output += "<html><body>Hello!</body></html>"
self.wfile.write(output)
print(output)
return
except IOError:
self.send_error(404, "File Not Found %s" % self.path)
def main():
try:
port = 8080
server = HTTPServer(('',port), webserverHandler)
print("Web server running on port %s" % port)
server.serve_forever()
except keyboardInterrupt:
print("^C entered, stopping web server...")
server.socket.close()
if __name__ == '__main__':
main()
Category: Python
SQLAlchemy
we must first import the necessary libraries, connect to db, and create a session to interface with the database:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from database_setup import Base, Restaurant, MenuItem
engine = create_engine('sqlite:///restaurantMenu.db')
Base.metadata.bind=engine
DBSession = sessionmaker(bind = engine)
session = DBSession()
Create
myFirstRestaurant = Restaurant(name = "Pizza Palace")
session.add(myFirstRestaurant)
sesssion.commit()
cheesepizza = menuItem(name="Cheese Pizza", description = "Made with all natural ingredients and fresh mozzarella", course="Entree", price="$8.99", restaurant=myFirstRestaurant)
session.add(cheesepizza)
session.commit()
firstResult = session.query(Restaurant).first()
firstResult.name
items = session.query(MenuItem).all()
for item in items:
print item.name
Update
In order to update and existing entry in our database, we must execute the following commands:
Find Entry
Reset value(s)
Add to session
Execute session.commit()
veggieBurgers = session.query(MenuItem).filter_by(name= 'Veggie Burger')
for veggieBurger in veggieBurgers:
print veggieBurger.id
print veggieBurger.price
print veggieBurger.restaurant.name
print "\n"
UrbanVeggieBurger = session.query(MenuItem).filter_by(id=8).one()
UrbanVeggieBurger.price = '$2.99'
session.add(UrbanVeggieBurger)
session.commit()
Delete
To delete an item from our database we must follow the following steps:
Find the entry
Session.delete(Entry)
Session.commit()
spinach = session.query(MenuItem).filter_by(name = 'Spinach Ice Cream').one() session.delete(spinach) session.commit()
python sqlalchemy
[vagrant@localhost webapp]$ python
Python 3.5.2 (default, Oct 31 2016, 08:50:29)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from sqlalchemy import create_engine
>>> from sqlalchemy.orm import sessionmaker
>>> from database_setup import Base, Restaurant, MenuItem
>>> engine = create_engine('sqlite:///restaurantmenu.db')
>>> Base.metadata.bind = engine
>>> DBSession = sessionmaker(bind = engine)
>>> session = DBSession()
>>> myFirstRestaurant = Restaurant(name = "Pizza Palace")
>>> session.add(myFirstRestaurant)
>>> session.commit()
>>> session.query(Restaurant).all()
[]
>>> cheesepizza = MenuItem(name= "Cheese Pizza", description = "Made with all natural ingredients and fresh mozzarella", course = "Entree", price = "$8.99", restaurant = myFirstRestaurant)
>>> session.add(cheesepizza)
>>> session.commit()
>>> session.query(MenuItem).all()
[]
>>> firstResult = session.query(Restaurant).first()
>>> firstResult.name
'Pizza Palace'
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from database_setup import Restaurant, Base, MenuItem
engine = create_engine('sqlite:///restaurantmenu.db')
# Bind the engine to the metadata of the Base class so that the
# declaratives can be accessed through a DBSession instance
Base.metadata.bind = engine
DBSession = sessionmaker(bind=engine)
# A DBSession() instance establishes all conversations with the database
# and represents a "staging zone" for all the objects loaded into the
# database session object. Any change made against the objects in the
# session won't be persisted into the database until you call
# session.commit(). If you're not happy about the changes, you can
# revert all of them back to the last commit by calling
# session.rollback()
session = DBSession()
#Menu for UrbanBurger
restaurant1 = Restaurant(name = "Urban Burger")
session.add(restaurant1)
session.commit()
menuItem2 = MenuItem(name = "Veggie Burger", description = "Juicy grilled veggie patty with tomato mayo and lettuce", price = "$7.50", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem1 = MenuItem(name = "French Fries", description = "with garlic and parmesan", price = "$2.99", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Chicken Burger", description = "Juicy grilled chicken patty with tomato mayo and lettuce", price = "$5.50", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Chocolate Cake", description = "fresh baked and served with ice cream", price = "$3.99", course = "Dessert", restaurant = restaurant1)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Sirloin Burger", description = "Made with grade A beef", price = "$7.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem4)
session.commit()
menuItem5 = MenuItem(name = "Root Beer", description = "16oz of refreshing goodness", price = "$1.99", course = "Beverage", restaurant = restaurant1)
session.add(menuItem5)
session.commit()
menuItem6 = MenuItem(name = "Iced Tea", description = "with Lemon", price = "$.99", course = "Beverage", restaurant = restaurant1)
session.add(menuItem6)
session.commit()
menuItem7 = MenuItem(name = "Grilled Cheese Sandwich", description = "On texas toast with American Cheese", price = "$3.49", course = "Entree", restaurant = restaurant1)
session.add(menuItem7)
session.commit()
menuItem8 = MenuItem(name = "Veggie Burger", description = "Made with freshest of ingredients and home grown spices", price = "$5.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem8)
session.commit()
#Menu for Super Stir Fry
restaurant2 = Restaurant(name = "Super Stir Fry")
session.add(restaurant2)
session.commit()
menuItem1 = MenuItem(name = "Chicken Stir Fry", description = "With your choice of noodles vegetables and sauces", price = "$7.99", course = "Entree", restaurant = restaurant2)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Peking Duck", description = " A famous duck dish from Beijing[1] that has been prepared since the imperial era. The meat is prized for its thin, crisp skin, with authentic versions of the dish serving mostly the skin and little meat, sliced in front of the diners by the cook", price = "$25", course = "Entree", restaurant = restaurant2)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Spicy Tuna Roll", description = "Seared rare ahi, avocado, edamame, cucumber with wasabi soy sauce ", price = "15", course = "Entree", restaurant = restaurant2)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Nepali Momo ", description = "Steamed dumplings made with vegetables, spices and meat. ", price = "12", course = "Entree", restaurant = restaurant2)
session.add(menuItem4)
session.commit()
menuItem5 = MenuItem(name = "Beef Noodle Soup", description = "A Chinese noodle soup made of stewed or red braised beef, beef broth, vegetables and Chinese noodles.", price = "14", course = "Entree", restaurant = restaurant2)
session.add(menuItem5)
session.commit()
menuItem6 = MenuItem(name = "Ramen", description = "a Japanese noodle soup dish. It consists of Chinese-style wheat noodles served in a meat- or (occasionally) fish-based broth, often flavored with soy sauce or miso, and uses toppings such as sliced pork, dried seaweed, kamaboko, and green onions.", price = "12", course = "Entree", restaurant = restaurant2)
session.add(menuItem6)
session.commit()
#Menu for Panda Garden
restaurant1 = Restaurant(name = "Panda Garden")
session.add(restaurant1)
session.commit()
menuItem1 = MenuItem(name = "Pho", description = "a Vietnamese noodle soup consisting of broth, linguine-shaped rice noodles called banh pho, a few herbs, and meat.", price = "$8.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Chinese Dumplings", description = "a common Chinese dumpling which generally consists of minced meat and finely chopped vegetables wrapped into a piece of dough skin. The skin can be either thin and elastic or thicker.", price = "$6.99", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Gyoza", description = "The most prominent differences between Japanese-style gyoza and Chinese-style jiaozi are the rich garlic flavor, which is less noticeable in the Chinese version, the light seasoning of Japanese gyoza with salt and soy sauce, and the fact that gyoza wrappers are much thinner", price = "$9.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Stinky Tofu", description = "Taiwanese dish, deep fried fermented tofu served with pickled cabbage.", price = "$6.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem4)
session.commit()
menuItem2 = MenuItem(name = "Veggie Burger", description = "Juicy grilled veggie patty with tomato mayo and lettuce", price = "$9.50", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
#Menu for Thyme for that
restaurant1 = Restaurant(name = "Thyme for That Vegetarian Cuisine ")
session.add(restaurant1)
session.commit()
menuItem1 = MenuItem(name = "Tres Leches Cake", description = "Rich, luscious sponge cake soaked in sweet milk and topped with vanilla bean whipped cream and strawberries.", price = "$2.99", course = "Dessert", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Mushroom risotto", description = "Portabello mushrooms in a creamy risotto", price = "$5.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Honey Boba Shaved Snow", description = "Milk snow layered with honey boba, jasmine tea jelly, grass jelly, caramel, cream, and freshly made mochi", price = "$4.50", course = "Dessert", restaurant = restaurant1)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Cauliflower Manchurian", description = "Golden fried cauliflower florets in a midly spiced soya,garlic sauce cooked with fresh cilantro, celery, chilies,ginger & green onions", price = "$6.95", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem4)
session.commit()
menuItem5 = MenuItem(name = "Aloo Gobi Burrito", description = "Vegan goodness. Burrito filled with rice, garbanzo beans, curry sauce, potatoes (aloo), fried cauliflower (gobi) and chutney. Nom Nom", price = "$7.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem5)
session.commit()
menuItem2 = MenuItem(name = "Veggie Burger", description = "Juicy grilled veggie patty with tomato mayo and lettuce", price = "$6.80", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
#Menu for Tony's Bistro
restaurant1 = Restaurant(name = "Tony\'s Bistro ")
session.add(restaurant1)
session.commit()
menuItem1 = MenuItem(name = "Shellfish Tower", description = "Lobster, shrimp, sea snails, crawfish, stacked into a delicious tower", price = "$13.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Chicken and Rice", description = "Chicken... and rice", price = "$4.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Mom's Spaghetti", description = "Spaghetti with some incredible tomato sauce made by mom", price = "$6.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Choc Full O\' Mint (Smitten\'s Fresh Mint Chip ice cream)", description = "Milk, cream, salt, ..., Liquid nitrogen magic", price = "$3.95", course = "Dessert", restaurant = restaurant1)
session.add(menuItem4)
session.commit()
menuItem5 = MenuItem(name = "Tonkatsu Ramen", description = "Noodles in a delicious pork-based broth with a soft-boiled egg", price = "$7.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem5)
session.commit()
#Menu for Andala's
restaurant1 = Restaurant(name = "Andala\'s")
session.add(restaurant1)
session.commit()
menuItem1 = MenuItem(name = "Lamb Curry", description = "Slow cook that thang in a pool of tomatoes, onions and alllll those tasty Indian spices. Mmmm.", price = "$9.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Chicken Marsala", description = "Chicken cooked in Marsala wine sauce with mushrooms", price = "$7.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Potstickers", description = "Delicious chicken and veggies encapsulated in fried dough.", price = "$6.50", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Nigiri Sampler", description = "Maguro, Sake, Hamachi, Unagi, Uni, TORO!", price = "$6.75", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem4)
session.commit()
menuItem2 = MenuItem(name = "Veggie Burger", description = "Juicy grilled veggie patty with tomato mayo and lettuce", price = "$7.00", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
#Menu for Auntie Ann's
restaurant1 = Restaurant(name = "Auntie Ann\'s Diner' ")
session.add(restaurant1)
session.commit()
menuItem9 = MenuItem(name = "Chicken Fried Steak", description = "Fresh battered sirloin steak fried and smothered with cream gravy", price = "$8.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem9)
session.commit()
menuItem1 = MenuItem(name = "Boysenberry Sorbet", description = "An unsettlingly huge amount of ripe berries turned into frozen (and seedless) awesomeness", price = "$2.99", course = "Dessert", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Broiled salmon", description = "Salmon fillet marinated with fresh herbs and broiled hot & fast", price = "$10.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem3 = MenuItem(name = "Morels on toast (seasonal)", description = "Wild morel mushrooms fried in butter, served on herbed toast slices", price = "$7.50", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem3)
session.commit()
menuItem4 = MenuItem(name = "Tandoori Chicken", description = "Chicken marinated in yoghurt and seasoned with a spicy mix(chilli, tamarind among others) and slow cooked in a cylindrical clay or metal oven which gets its heat from burning charcoal.", price = "$8.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem4)
session.commit()
menuItem2 = MenuItem(name = "Veggie Burger", description = "Juicy grilled veggie patty with tomato mayo and lettuce", price = "$9.50", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
menuItem10 = MenuItem(name = "Spinach Ice Cream", description = "vanilla ice cream made with organic spinach leaves", price = "$1.99", course = "Dessert", restaurant = restaurant1)
session.add(menuItem10)
session.commit()
#Menu for Cocina Y Amor
restaurant1 = Restaurant(name = "Cocina Y Amor ")
session.add(restaurant1)
session.commit()
menuItem1 = MenuItem(name = "Super Burrito Al Pastor", description = "Marinated Pork, Rice, Beans, Avocado, Cilantro, Salsa, Tortilla", price = "$5.95", course = "Entree", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem2 = MenuItem(name = "Cachapa", description = "Golden brown, corn-based Venezuelan pancake; usually stuffed with queso telita or queso de mano, and possibly lechon. ", price = "$7.99", course = "Entree", restaurant = restaurant1)
session.add(menuItem2)
session.commit()
restaurant1 = Restaurant(name = "State Bird Provisions")
session.add(restaurant1)
session.commit()
menuItem1 = MenuItem(name = "Chantrelle Toast", description = "Crispy Toast with Sesame Seeds slathered with buttery chantrelle mushrooms", price = "$5.95", course = "Appetizer", restaurant = restaurant1)
session.add(menuItem1)
session.commit
menuItem1 = MenuItem(name = "Guanciale Chawanmushi", description = "Japanese egg custard served hot with spicey Italian Pork Jowl (guanciale)", price = "$6.95", course = "Dessert", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
menuItem1 = MenuItem(name = "Lemon Curd Ice Cream Sandwich", description = "Lemon Curd Ice Cream Sandwich on a chocolate macaron with cardamom meringue and cashews", price = "$4.25", course = "Dessert", restaurant = restaurant1)
session.add(menuItem1)
session.commit()
print("added menu items!")
CRUD
create, read, update, delete
pip install sqlalchemy
orm for python
object relational mapper
sql alchemy
->vagrant file already set up
http://www.sqlalchemy.org/
import os
import sys
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy import create_engine
Base = declarative_base()
class Restaurant(Base):
__tablename__ = 'restaurant'
id = Column(Integer, primary_key=True)
name = Column(String(250), nullable=False)
class MenuItem(Base):
__tablename__ = 'menu_item'
name =Column(String(80), nullable = False)
id = Column(Integer, primary_key = True)
description = Column(String(250))
price = Column(String(8))
course = Column(String(250))
restaurant_id = Column(Integer,ForeignKey('restaurant.id'))
restaurant = relationship(Restaurant)
engine = create_engine('sqlite:///restaurantmenu.db')
Base.metadata.create_all(engine)
python redis module
Python client for Redis key-value store
$ sudo pip install redis
index.python
# _*_ coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import unicode_literals
def jaccard(e1, e2):
"""
:param e1: list of int
:param e2: list of int
:rtype: float
"""
set_e1 = set(e1)
set_e2 = set(e2)
return float(len(set_e1 & set_e2)) / float(len(set_e1 | set_e2))
def get_key(k):
return 'JACCARD:PRODUCT:{}'.format(k)
# 商品xを購入した人が1,3,5
product_x = [1, 3, 5]
product_a = [2, 4, 5]
product_b = [1, 2, 3]
product_c = [2, 3, 4, 7]
product_d = [3]
product_e = [4, 6, 7]
# 商品データ
products = {
'X': product_x,
'A': product_a,
'B': product_b,
'C': product_c,
'D': product_d,
'E': product_e,
}
#redis
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
for key in products:
base_customers = products[key]
for key2 in products:
if key == key2:
continue
target_customers = products[key2]
# ジャッカード指数
j = jaccard(base_customers, target_customers)
# redis Sortedに記録
r.zadd(get_key(key), key2, j)
# 例1 商品xを買った人はこんな商品も買っています
print(r.zrevrange(get_key('X'), 0, 2))
# 例2 商品Eを買った人はこんな商品も買っています。
print(r.zrevrange(get_key('E'), 0, 2))
[vagrant@localhost rss10]$ python index.py [b'B', b'D', b'A'] [b'C', b'A', b'X']
レコメンドアルゴリズムには、協調フィルタリングと内容ベース(コンテンツベース)フィルタリングがある
Insert DB-API
Inserts in DB API
pg = psycopg2.connect("dbname=somedb")
c = pg.cursor()
c.execute("insert into names values('Jennifer Smith')")
pg.commit()
import sqlite3
db = sqlite3.connect("testdb")
c = db.cursor()
c.execute("insert into balloons values ('blue', 'water') ")
db.commit()
db.close()
DB data attack
‘); delete from posts;–
spam table
<script>
setTimeout(function() {
var tt = document.getElementById('content');
tt.value = "<h2 style='color: #FF6699; font-family: Comic Sans MS'>Spam, spam, spam, spam,<br>Wonderful spam, glorious spam!</h2>";
tt.form.submit();
}, 2500);
</script>
python sql
QUERY = ''' select name, birthdate from animals where species = 'gorilla'; '''
+———+————+
| name | birthdate |
+=========+============+
| Max | 2001-04-23 |
| Dave | 1988-09-29 |
| Becky | 1979-07-04 |
| Liz | 1998-06-12 |
| George | 2011-01-09 |
| George | 1998-05-18 |
| Wendell | 1982-09-24 |
| Bjorn | 2000-03-07 |
| Kristen | 1990-04-25 |
+———+————+
select name, birthdate from animals where species = ‘gorilla’ and name = ‘Max’
否定
QUERY = ''' select name, birthdate from animals where species != 'gorilla' and name != 'Max'; '''
between文
QUERY = ''' select name from animals where species = 'llama' AND birthdate between '1995-01-01' AND '1998-12-31'; '''
query
QUERY = "select max(name) from animals;" QUERY = "select * from animals limit 10;" QUERY = "select * from animals where species = 'orangutan' order by birthdate;" QUERY = "select name from animals where species = 'orangutan' order by birthdate desc;" QUERY = "select name, birthdate from animals order by name limit 10 offset 20;" QUERY = "select species, min(birthdate) from animals group by species;" QUERY = ''' select name, count(*) as num from animals group by name order by num desc limit 5; '''
Limit count Offset skip
limit is how many rows to return
offset is how far into the results to start
Order by columns DESC
columns is which columns to sort by, separated with commas
DESC is sort in reverse order(descending)
Group by columns
columns is which columns to use as groupings when aggregating
QUERY = "select count(*) as num, species from animals group by species order by num desc;"
insert
INSERT_QUERY = '''
insert into animals (name, species, birthdate) values ('yoshi', 'opposum', '2016-12-13');
'''
what’s going on?
this function mean a*b, z is x time multiply.
def naive(a, b):
x = a; y = b
z = 0
while x > 0:
z = z + y
x = x - 1
return z
print(naive(4, 5))
def russian(a, b):
x = a; y = b
z = 0
while x > 0:
if x % 2 == 1: z = z + y
y = y << 1
x = x >> 1
return z
print(russian(5, 5))
make new instance
import media
toy_story = media.Movie("Toy Story",
"A story of a boy and toys that come to life",
"http://upload.wikimedia.org/wikipedia/en/1/13/Toy_Story.jpg",
"https://www.youtube.com/watch?v=vwyZH85NQC4")
# print(toy_story.storyline)
avatar = media.Movie("Avatar",
"A marine on an alien planet",
"http://upload.wikimedia.org/wikipedia/id/b/b0/Avatar-Teaser-Poster.jpg",
"http://www.youtube.com/watch?v=-9ceBgWV8io")
print(avatar.storyline)
# avatar.show_trailer()
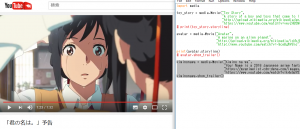
kiminonawa = media.Movie("Kimino na wa",
"Your Name is a 2016 Japanese anime fantasy film written and directed by Makoto Shinkai",
"https://myanimelist.cdn-dena.com/images/anime/7/79999.webp",
"https://www.youtube.com/watch?v=k4xGqY5IDBE")
kiminonawa.show_trailer()
media.py
import webbrowser
class Movie():
def __init__(self, movie_title, movie_storyline, poster_image, trailer_youtube):
self.title = movie_title
self.storyline = movie_storyline
self.poster_image_url = poster_image
self.trailer_youtube_url = trailer_youtube
def show_trailer(self):
webbrowser.open(self.trailer_youtube_url)
import fresh_tomatoes
import media
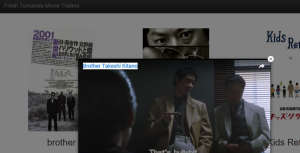
brother = media.Movie("brother",
"Takeshi Kitano plays Yamamoto, a lone yakuza officer. Defeated in a war with a rival family, his boss killed, he heads to Los Angeles, California.",
"https://upload.wikimedia.org/wikipedia/en/a/a1/BrotherKitano.jpg",
"https://www.youtube.com/watch?v=AgjDYR6-DTU")
# print(toy_story.storyline)
outrage = media.Movie("Outrage",
"The film begins with a sumptuous banquet at the opulent estate of the Grand Yakuza leader Sekiuchi (Soichiro Kitamura), boss of the Sanno-kai, a huge organized crime syndicate controlling the entire Kanto region, and he has invited the many Yakuza leaders under his control.",
"https://upload.wikimedia.org/wikipedia/en/f/f4/Outrage-2010-poster.png",
"https://www.youtube.com/watch?v=EXLuvZY8bMU")
#print(avatar.storyline)
# avatar.show_trailer()
#kiminonawa = media.Movie("Kimino na wa",
# "Your Name is a 2016 Japanese anime fantasy film written and directed by Makoto Shinkai",
# "https://myanimelist.cdn-dena.com/images/anime/7/79999.webp",
# "https://www.youtube.com/watch?v=k4xGqY5IDBE")
#kiminonawa.show_trailer()
kids = media.Movie("Kids Return",
"The movie is about two high school dropouts, Masaru (Ken Kaneko) and Shinji (Masanobu Ando)",
"https://upload.wikimedia.org/wikipedia/en/a/a7/KidsReturnPoster.jpg",
"https://www.youtube.com/watch?v=MvY6JCFCrQk")
ratatouille = media.Movie("Ratatouille",
"storyline",
"http://upload.wikimedia.org/wikipedia/en/5/50/RatatouillePoster.jpg",
"https://www.youtube.com/watch?v=3YG4h5GbTqU")
midnight_in_paris = media.Movie("Midnight in Paris",
"storyline",
"http://upload.wikimedia.org/wikipedia/en/9/9f/Midnight_in_Paris_Poster.jpg",
"https://www.youtube.com/watch?v=JABOZpoBYQE")
hunger_games = media.Movie("Hunger Games",
"storyline",
"http://upload.wikimedia.org/wikipedia/en/4/42/HungerGamesPoster.jpg",
"https://www.youtube.com/watch?v=PbA63a7H0bo")
movies = [brother, outrage, kids, ratatouille, midnight_in_paris, hunger_games]
fresh_tomatoes.open_movies_page(movies)
documentation
>>> import turtle >>> turtle.Turtle.__doc__ 'RawTurtle auto-creating (scrolled) canvas.\n\n When a Turtle object is created or a function derived from some\n Turtle method is called a TurtleScreen object is automatically created.\n
inheritance
class Parent():
def __init__(self, last_name, eye_color):
print("parent constructor called")
self.last_name = last_name
self.ey_color = eye_color
class Child(Parent):
def __init__(self, last_name, eye_color, number_of_toys):
print("child constructor called")
Parent.__init__(self, last_name, eye_color)
self.number_of_toys = number_of_toys
#billy_cyrus = Parent("Cyrus","blue")
#print(billy_cyrus.last_name)
myley_crus = Child("cryus", "blue", 5)
print(myley_crus.last_name)
print(myley_crus.number_of_toys)
curse word search
http://www.wdylike.appspot.com/ is a site judge it contain curse word in it.
import urllib
def read_text():
quotes = open(r"C:\Users\hoge\Desktop\controller\movie_quote.txt")
contents_of_file = quotes.read()
# print(contents_of_file)
quotes.close()
check_profanity(contents_of_file)
def check_profanity(text_to_check):
connection = urllib.urlopen("http://www.wdylike.appspot.com/?q="+text_to_check)
output = connection.read()
# print(output)
connection.close()
if "true" in output:
print("Profanity Alert!")
elif "false" in output:
print("This document has no curse words")
else:
print("Could not scan the document properly.")
read_text()
when you write python, google style guide would help coding.
https://google.github.io/styleguide/pyguide.html