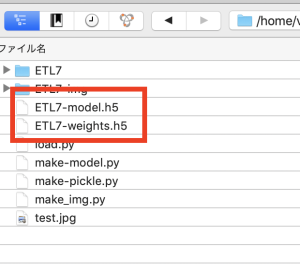
Kerasのモデル保存は、「.h5」というHDF5拡張し(階層データ形式)で保存する
Hierarchical Data Formatの略で5はバージョン
CSVより早い
from tensorflow.keras.models import load_model
model = load_model('ETL7-model.h5')
print(model.summary())
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 320
batch_normalization (BatchN (None, 30, 30, 32) 128
ormalization)
activation (Activation) (None, 30, 30, 32) 0
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
dropout (Dropout) (None, 15, 15, 32) 0
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
batch_normalization_1 (Batc (None, 13, 13, 64) 256
hNormalization)
activation_1 (Activation) (None, 13, 13, 64) 0
conv2d_2 (Conv2D) (None, 11, 11, 64) 36928
batch_normalization_2 (Batc (None, 11, 11, 64) 256
hNormalization)
activation_2 (Activation) (None, 11, 11, 64) 0
max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0
2D)
dropout_1 (Dropout) (None, 5, 5, 64) 0
flatten (Flatten) (None, 1600) 0
dense (Dense) (None, 512) 819712
batch_normalization_3 (Batc (None, 512) 2048
hNormalization)
activation_3 (Activation) (None, 512) 0
dropout_2 (Dropout) (None, 512) 0
dense_1 (Dense) (None, 48) 24624
activation_4 (Activation) (None, 48) 0
=================================================================
Total params: 902,768
Trainable params: 901,424
Non-trainable params: 1,344
_________________________________________________________________
from tensorflow.keras.models import load_model
from PIL import Image
import numpy as np
model = load_model('ETL7-model.h5')
img = Image.open("test.jpg").convert('L')
img.thumbnail((32, 32))
img = np.array(img)
pred = model.predict(img[np.newaxis]) # numpyのnewaxis
print(np.argmax(pred))
load_modelで読み込みはできるが、それを使って操作する方法がわからん…
ETL8でひらがなだけでなく、漢字もできるとのこと。