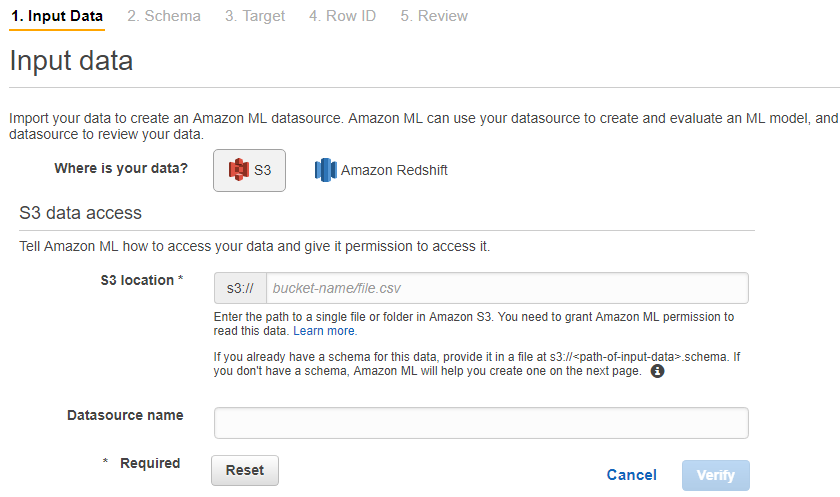
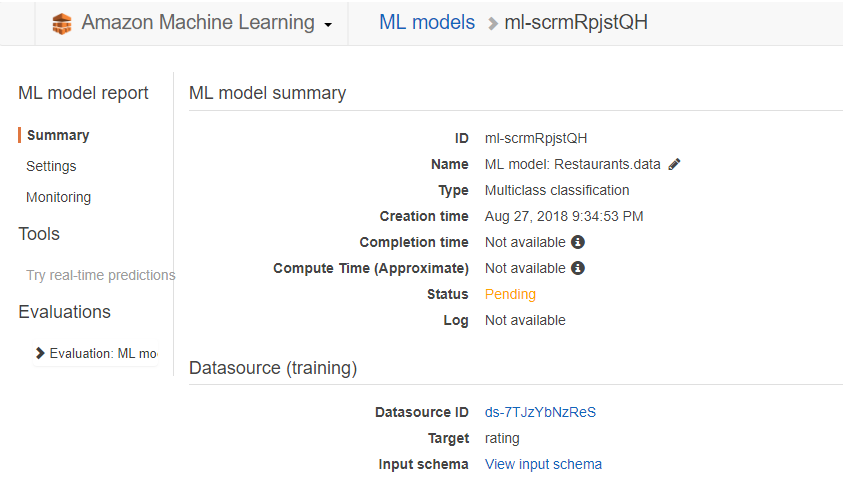
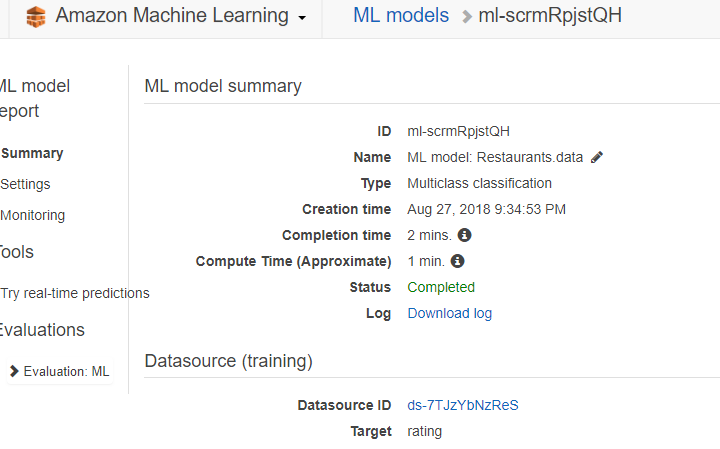
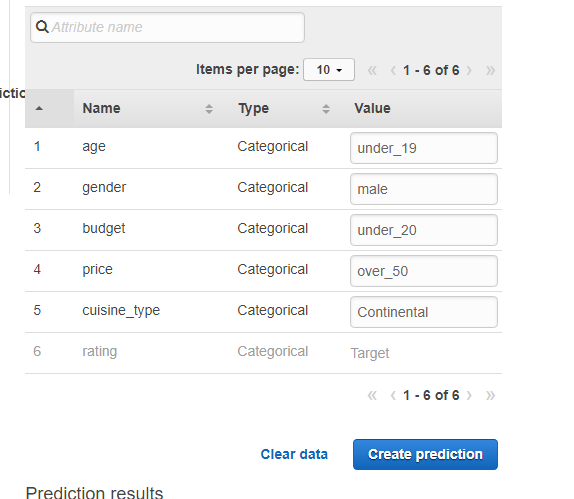
Annotation is critical to AI development and operation.
It is important to create large amount of accurate annotation data
Analysis and improvement of annotation process by machine learning.
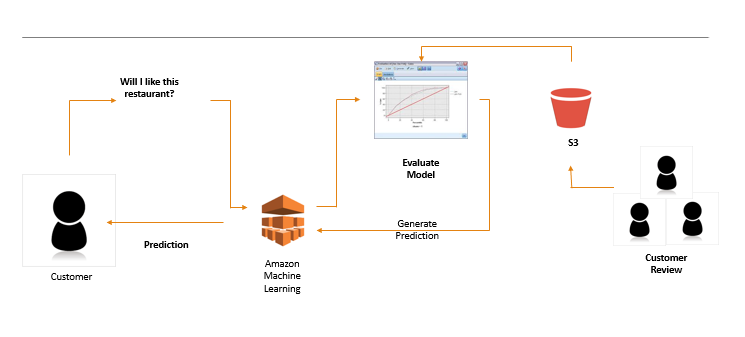
Annotations are processes located upstream of pipeline. Therefore, if there are many errors in the annotation, it may have a fatal effect on subsequent processes, including model learning and evaluation(in many cases, evaluation data is also generated by the annotation).
Why is annotation important?
To unify the content to be read from the data.
In the upstream process of the AI pipeline, it has a fatal impact on the leader processes such as model learning and evaluation.
アノテーションが重要そうだ、というのは直ぐに気づきますが、研究が活発な分野っぽいですね。