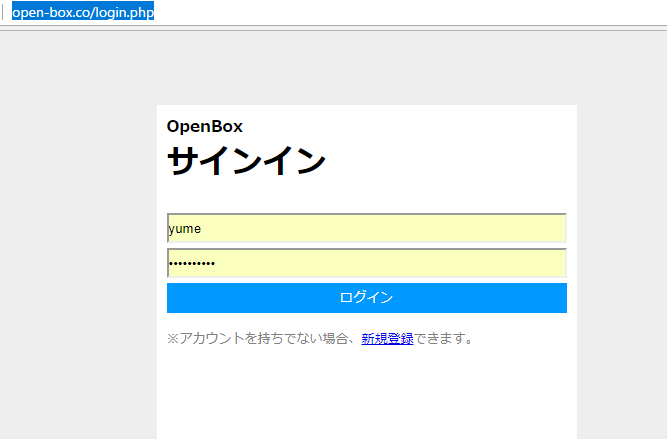
まず、login.phpで、sessionのusernameとpasswordがokなら、メールトップ画面にリダイレクトする処理を書いています。
<?php elseif($status == "ok"): header('Location: mail.php?path=u0'); ?>
こちらがログイン後の画面。outlookのUIを参考にしています。
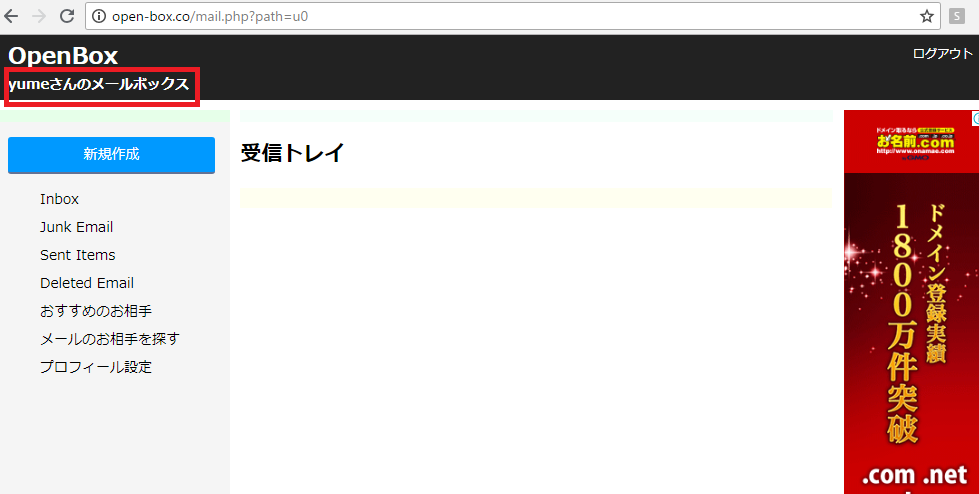
「yumeさんのメールボックス」がh2です。
続いて、python。 sessionのusernameをyumeでpostして、beautifulsoupでh2をselect_oneします。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
USER = "yume"
PASS = "hogehoge"
session = requests.session()
login_info = {
"username" : USER,
"password": PASS,
}
url_login = "http://open-box.co/login.php"
res = session.post(url_login, data=login_info)
res.raise_for_status()
print("success")
soup = BeautifulSoup(res.text, "html.parser")
a = soup.select_one("h2").string
if a is None:
print("取得できませんでした")
quit()
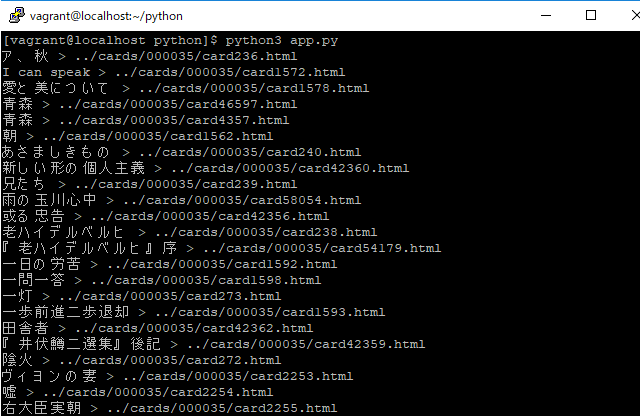
print(a)
[vagrant@localhost python]$ python3 app.py
success
yumeさんのメールボックス
おいおいおい。まてまてまて、頭が追い付かない。
すげー、python!
え、それなら、もしかして、twitterもいける?
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
USER = "hoge"
PASS = "hogehoge"
session = requests.session()
login_info = {
"signin-email" : USER,
"signin-password": PASS,
}
url_login = "https://twitter.com/login"
res = session.post(url_login, data=login_info)
res.raise_for_status()
print("success")
[vagrant@localhost python]$ python3 app.py
Traceback (most recent call last):
File “app.py”, line 16, in
res.raise_for_status()
File “/home/vagrant/.pyenv/versions/3.5.2/lib/python3.5/site-packages/requests/models.py”, line 939, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://twitter.com/login
Forbiddenだ。さすがにあかんか。
twitterに限らず、requests.session()では、ログインできないようにできるらしいですね。
なるほどね。